地址:https://jn.zu.ke.com/zufang
1,首先确定要爬取的数据

2,查看数据来源
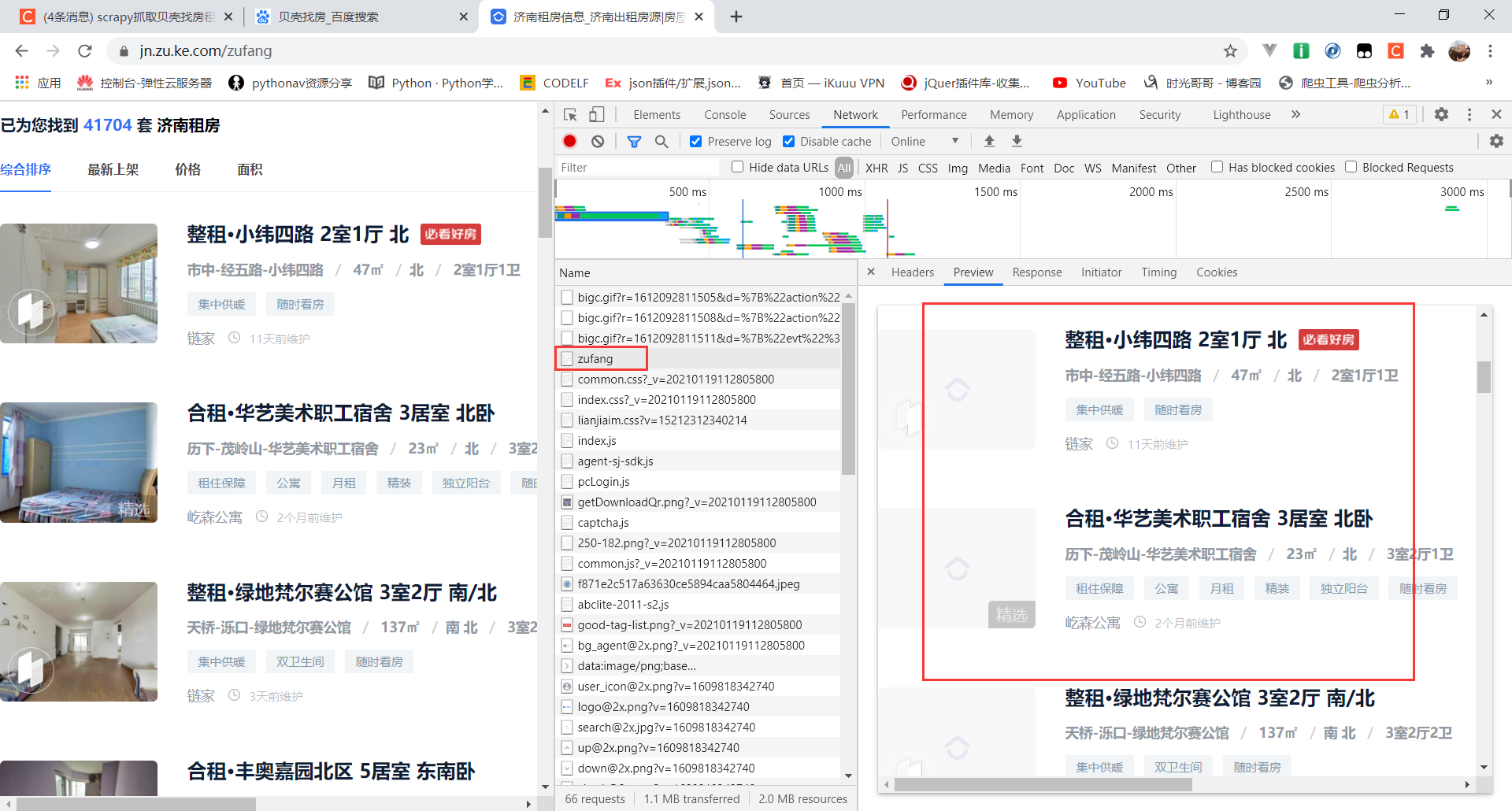
数据直接在网页中展示,不是动态加载,也不需要cookie,更没有什么反爬(之所以写这篇文章是因为我对scrapy框架不了解,正在学习中,加深一下印象)
3.找下一页的数据,寻找url规律
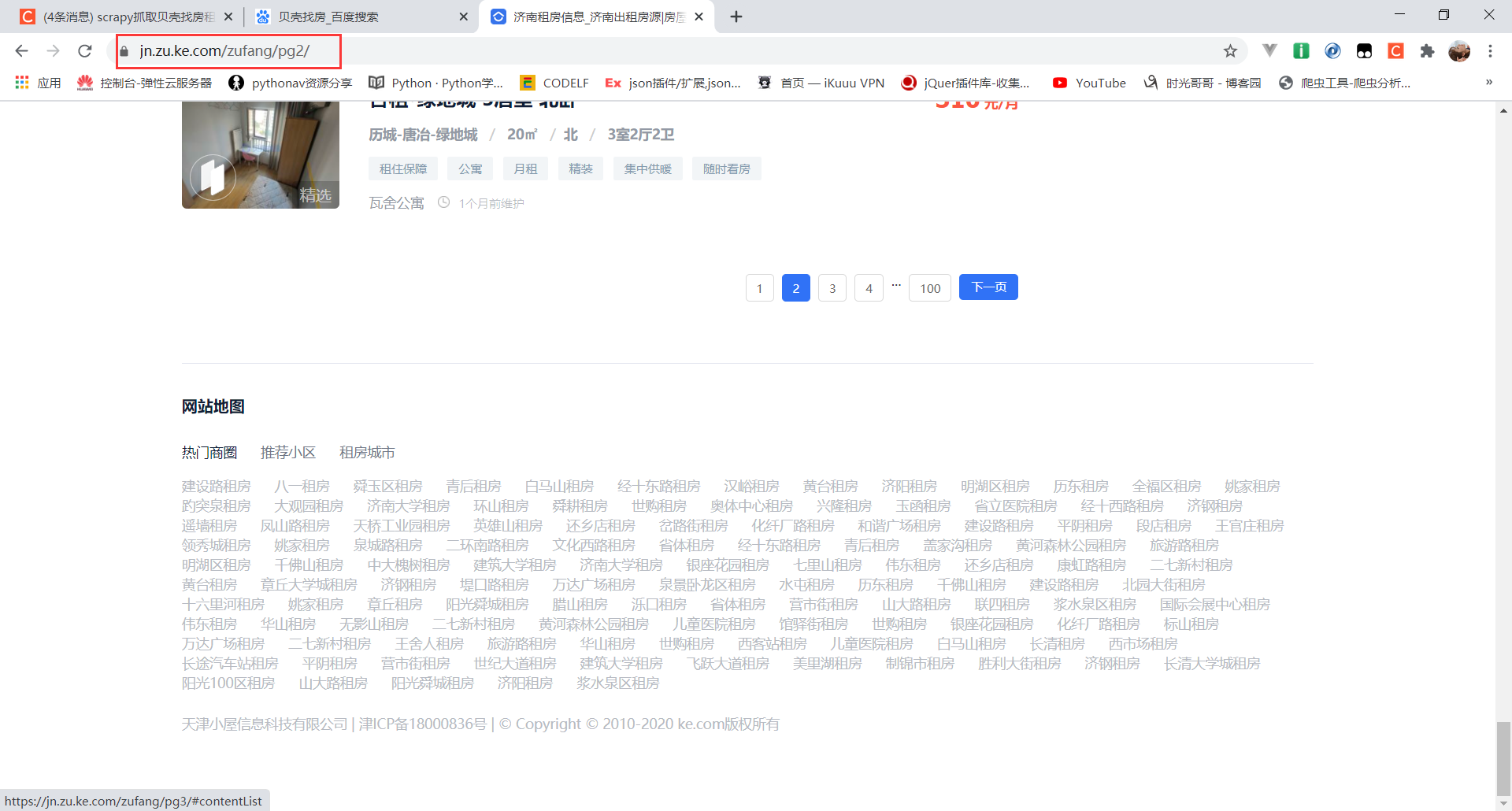
可以看到地址https://jn.zu.ke.com/zufang/pg2/ https://jn.zu.ke.com/zufang/pg3/.。。。。。是有一定规律的
#url可以这样表示
start_urls = [f'https://jn.zu.ke.com/zufang/pg{i}/#contentList' for i in range(1,101)]
4,数据来源分析好了之后就要开始创建项目了
不知道scrapy怎么用的同学可以看我的另外几篇文章 scrapy基本命令 scrapy框架持久化存储 scrapy分布式爬虫 增量式爬虫
5,开始编写代码
1,settings.py配置文件需要改一些配置

2,item.py确定需要的数据
import scrapy class PropertiesItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field() link = scrapy.Field() address = scrapy.Field() big = scrapy.Field() where = scrapy.Field() how = scrapy.Field() price = scrapy.Field() name = scrapy.Field()
3,进行编写爬虫文件
import copy import scrapy from properties.items import PropertiesItem class ExampleSpider(scrapy.Spider): name = 'example' allowed_domains = ['example.com'] start_urls = [f'https://jn.zu.ke.com/zufang/pg{i}/#contentList' for i in range(1,101)] def parse(self, response): node_list = response.xpath('//div[@class="content__list--item--main"]') item = PropertiesItem() for node in node_list: item["title"] = node.xpath("./p[1]/a/text()").extract_first().strip() item["link"] = response.urljoin(node.xpath("./p[1]/a/@href").extract_first().strip()) item["address"] = node.xpath("./p[2]/a[3]/text()").extract_first().strip() item["big"] = node.xpath("./p[2]/text()[5]").extract_first().strip() item["where"] = node.xpath("./p[2]/text()[6]").extract_first().strip() item["how"] = node.xpath("./p[2]/text()[7]").extract_first().strip() item["price"] = node.xpath( './span[@class="content__list--item-price"]/em/text()').extract_first().strip() + '元/月' # item["name"] ='none' # yield item yield scrapy.Request( url=item["link"], callback=self.makes, meta={"item": copy.deepcopy(item)}, dont_filter=True ) def makes(self,response): item = response.meta['item'] item["name"] = response.xpath('//span[@class="contact_name"]/@title').extract_first() yield item
4,编写管道文件pipelines.py
import csv class PropertiesPipeline: def __init__(self): self.fp=None def open_spider(self,spider): print('=====爬虫开始=====') self.fp = open('贝壳.csv', 'w', newline='', encoding="utf8") self.csv_writer=csv.writer(self.fp) self.csv_writer.writerow(["标题", "链接", '地址', "大小", "方向", "居室", "价格","姓名"]) def process_item(self, item, spider): self.csv_writer.writerow( [item["title"], item["link"], item["address"], item["big"], item["where"], item["how"], item["price"],item['name']] ) return item def close_spider(self,spider): self.fp.close() print('=====爬虫结束=====')
别的文件就不需要做任何更改了,想要保存到数据库 ,csv等地方可以看我的博客 scrapy持久化存储 python操作csv,Excel,word
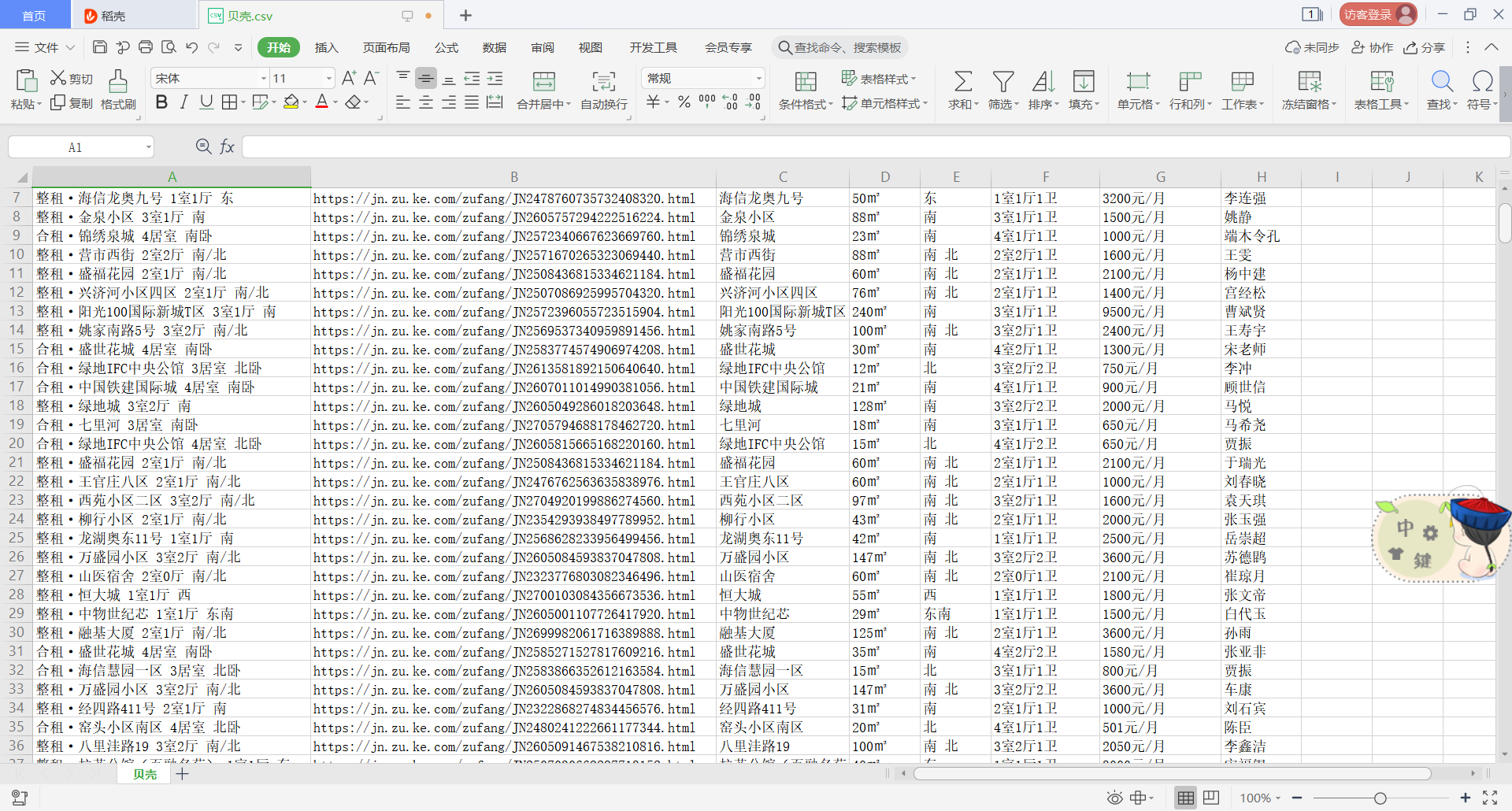
这就是我爬取好的数据,爬取下来是有很多重复数据的,是因为这个网站的原因,他在展示数据的时候就是从一个大列表里面抽取数据来展示,你每刷新一次页面数据也就不一样,可以用数据分析相关模块进行去重,后续会在博客中更新,我目前是存储在csv中,wps,office自带去重功能