
前言
上一篇文章讲了爬虫的概念,本篇文章主要来讲述一下如何来解析爬虫请求的网页内容。
一个简单的爬虫程序主要分为两个部分,请求部分和解析部分。请求部分基本一行代码就可以搞定,所以主要来讲述一下解析部分。对于解析,最常用的就是xpath和css选择器,偶尔也会使用正则表达式。
不论是xpah还是css,都是通过html元素或者其中某些属性来选中符合条件的元素节点。
以斗罗大陆的部分html为例。
<div class="detail_video">
<div class="video_title_collect cf">
<h1 class="video_title_cn">
<a target="_blank" _stat="info:title" href="http://v.qq.com/x/cover/m441e3rjq9kwpsc.html">斗罗大陆</a>
<span class="title_en" itemprop="alternateName"></span>
<i class="dot"></i>
<span class="type">动漫</span>
</h1>
</div>
<div class="video_type cf">
<div class="type_item">
<span class="type_tit">别 名:</span>
<span class="type_txt">斗罗大陆动画版</span>
</div>
<div class="type_item">
<span class="type_tit">地 区:</span>
<span class="type_txt">内地</span>
</div>
<div class="type_item">
<span class="type_tit">更新集数:</span>
<span class="type_txt">更新至141集</span>
</div>
</div>
<div class="video_type video_type_even cf">
<div class="type_item">
<span class="type_tit">出品时间:</span>
<span class="type_txt">2018</span>
</div>
<div class="type_item">
<span class="type_tit">更新时间:</span>
<span class="type_txt">每周六10:00更新1集</span>
</div>
</div>
<div class="video_tag cf">
<span class="tag_tit">标 签: </span>
<div class="tag_list">
<a class="tag" href="http://v.qq.com/x/search?q=%E6%88%98%E6%96%97" target="_blank" _stat="info:tag">战斗</a>
</div>
</div>
<div class="video_desc">
<span class="desc_tit">简 介:</span>
<span class="desc_txt">
<span class="txt _desc_txt_lineHight" itemprop="description">唐门外门弟子唐三,因偷学内门绝学为唐门所不容,跳崖明志时却发现没有死,反而以另外一个身份来到了另一个世界,一个属于武魂的世界,名叫斗罗大陆。这里没有魔法,没有斗气,没有武术,却有神奇的武魂。这里的每个人,在自己六岁的时候,都会在武魂殿中令武魂觉醒。武魂有动物,有植物,有器物,武魂可以辅助人们的日常生活。而其中一些特别出色的武魂却可以用来修炼并进行战斗,这个职业,是斗罗大陆上最为强大也是最荣耀的职业“魂师”。
小小的唐三在圣魂村开始了他的魂师修炼之路,并萌生了振兴唐门的梦想。当唐门暗器来到斗罗大陆,当唐三武魂觉醒,他能否在这片武魂的世界再铸唐门的辉煌??
</span>
</span>
</div>
</div>
css选择器
很多学习过前端的小伙伴对css选择器比较熟悉,.是class选择器,#是id选择器。这里挑最几个常用的来讲一下,其他用法可百度。
常见语法
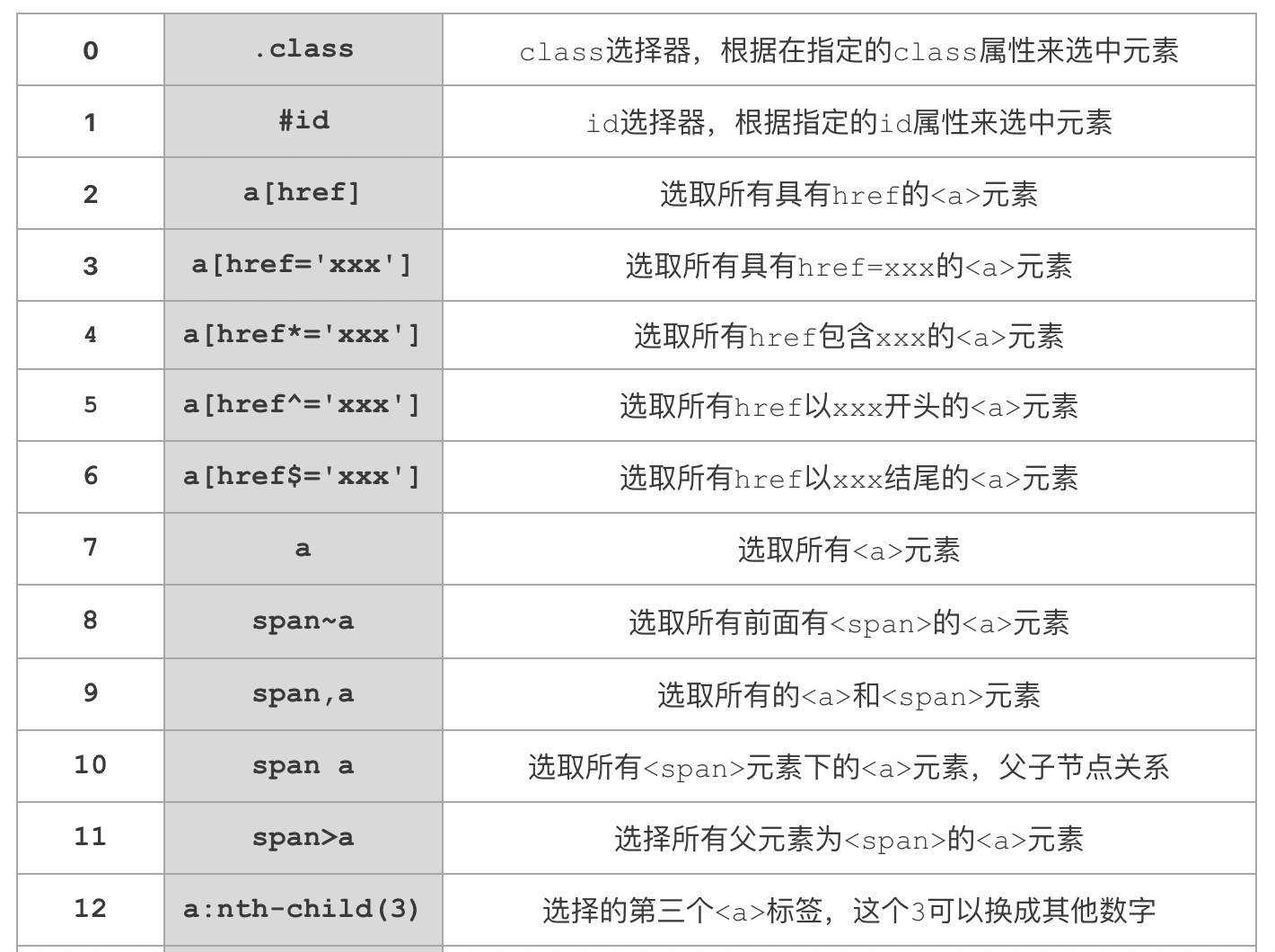
以上就是一些比较常用的css选择器。其中里面的元素a和span只用来举例,可以替换成任意的html元素,href属性也可以替换成元素的其他属性。
样例说明
还是用之前斗罗大陆的程序来说明一下。
import requests
from bs4 import BeautifulSoup
url = 'https://v.qq.com/detail/m/m441e3rjq9kwpsc.html'
# 发起请求,获取页面
response = requests.get(url)
# 解析html,获取数据
soup = BeautifulSoup(response.text, 'html.parser')
# .video_title_cn a 表示class=video_title_cn元素下的<a>
# 这里指的就是<h1 class="video_title_cn">下的<a>,就一个<a>,所以[0]取出此元素
name = soup.select(".video_title_cn a")[0].string
# span.type表示属性class=type的<span>元素
# 这里指的是<span class="type">动漫</span>此元素
category = soup.select("span.type")[0].string
# class=type_txt的<span>有多个,所以根据下标取出列表中对应的元素
# 这里指的是<span class="type_txt">斗罗大陆动画版</span>
alias = soup.select("span.type_txt")[0].string
# <span class="type_txt">内地</span> [1]代表是第二个元素
area = soup.select("span.type_txt")[1].string
# <span class="type_txt">更新至141集</span>
parts =soup.select("span.type_txt")[2].string
# <span class="type_txt">2018</span>
date = soup.select("span.type_txt")[3].string
# <span class="type_txt">每周六10:00更新1集</span>
update = soup.select("span.type_txt")[4].string
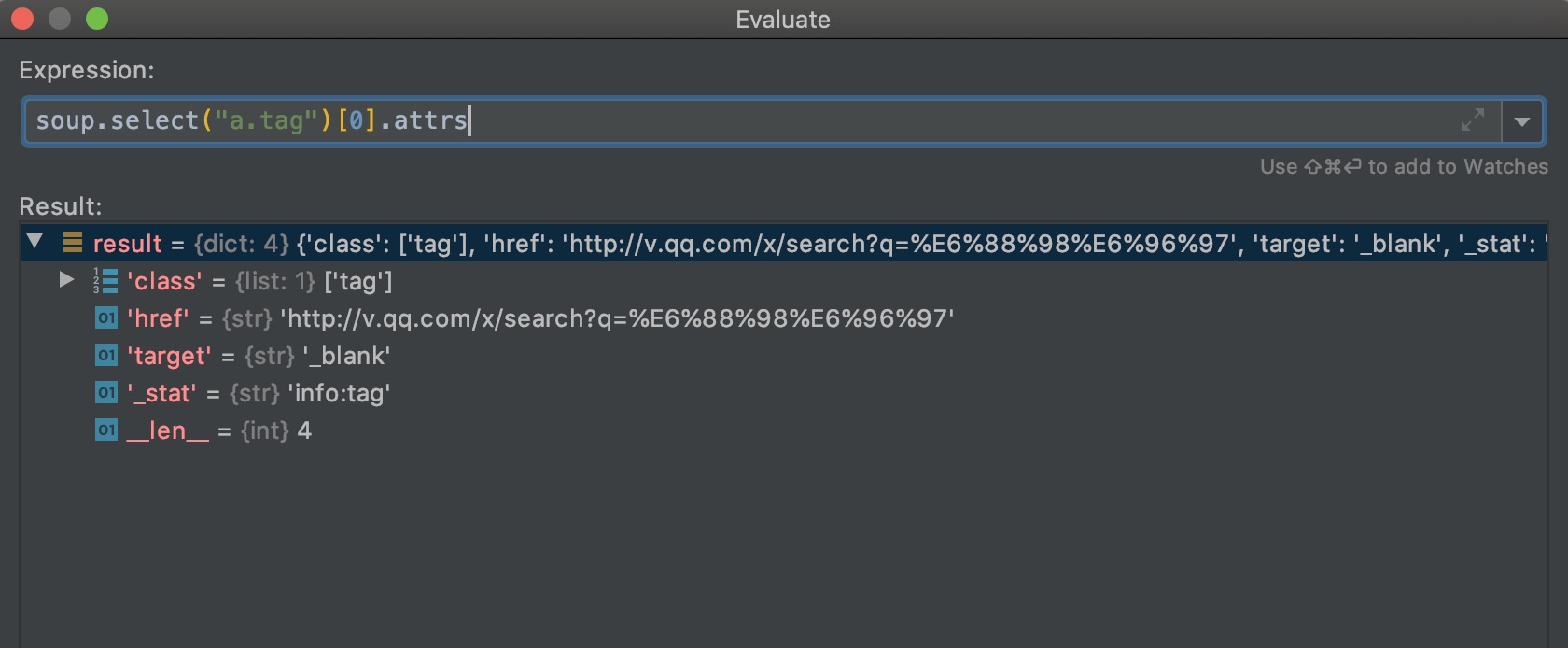
# <a class="tag" href="http://v.qq.com/x/search?q=%E6%88%98%E6%96%97" target="_blank" _stat="info:tag">战斗</a>
tag = soup.select("a.tag")[0].string
# <span class="txt _desc_txt_lineHight">
describe = soup.select("span._desc_txt_lineHight")[0].string
print(name, category, alias, parts, date, update, tag, describe, sep='\n')
soup.select()根据css规则选择元素,返回包含一个或多个元素的list。
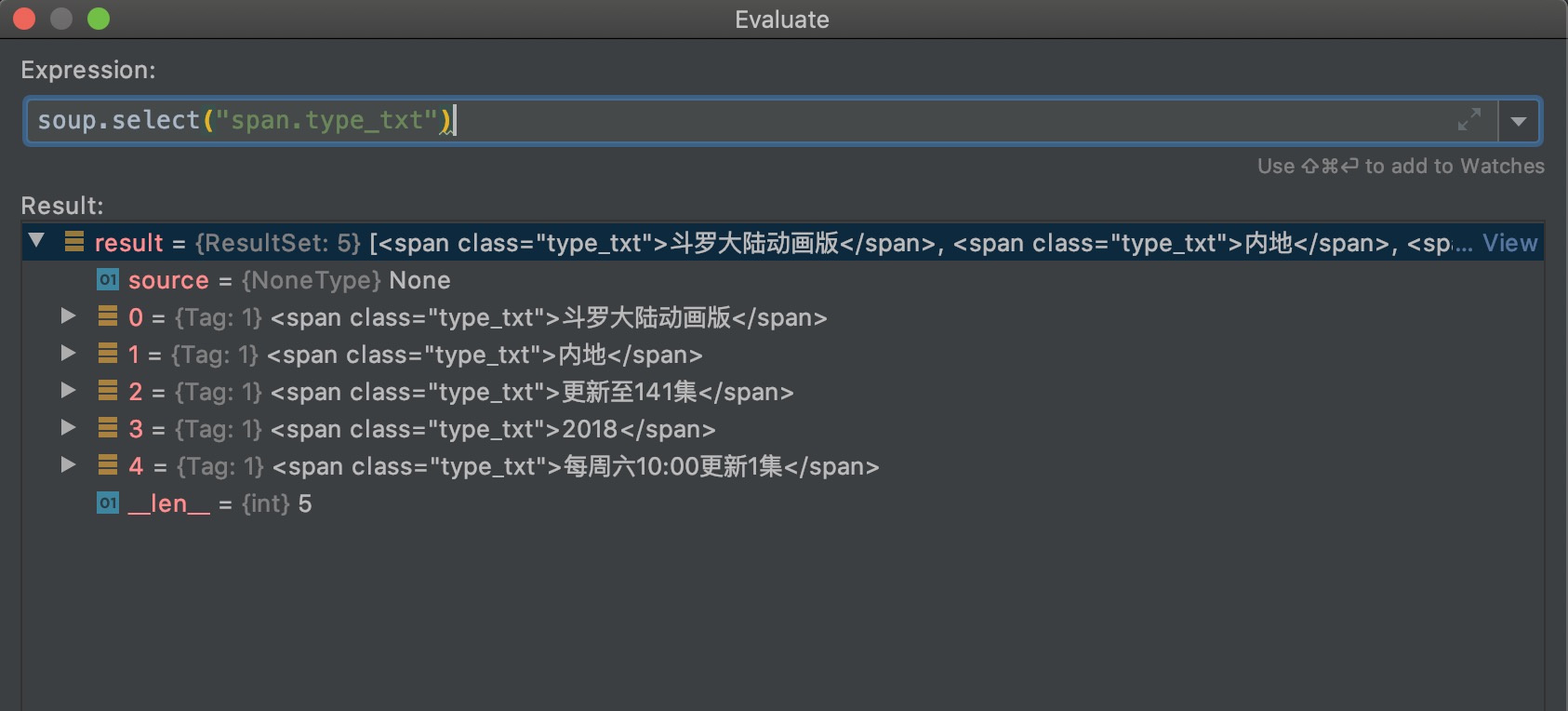
因为html中class="type_txt"的span元素有五个,所以返回了五个元素的列表。遍历列表,每个元素可以通过string属性,来输出元素中间的文本内容;每个元素通过attrs属性,可以获取标签的属性,返回一个字典。
小技巧
如果你要问,不会css选择器能不能写爬虫啊,我肯定不会回答我帮你写啊,我只能告诉你可以!!
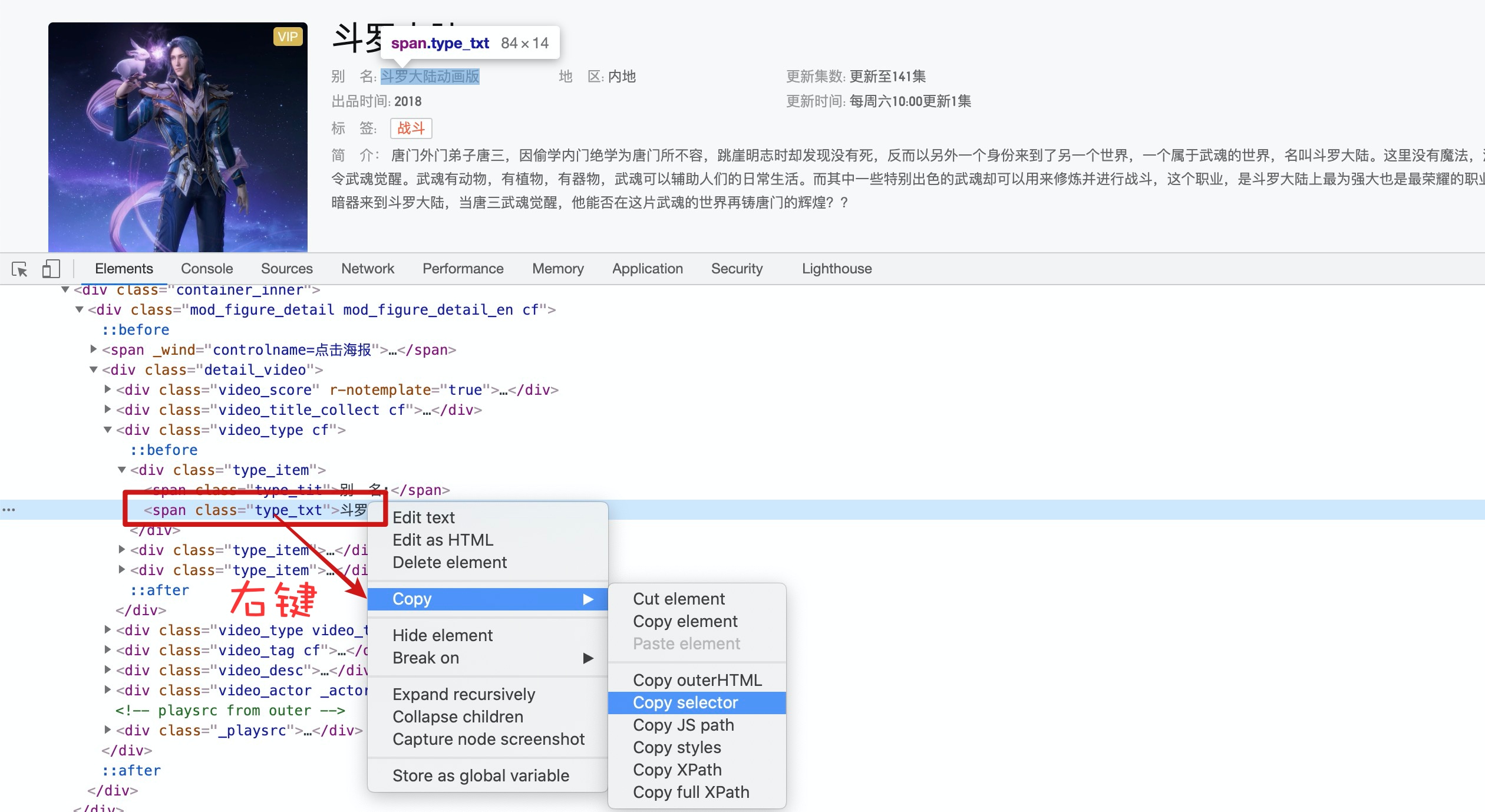
复制的css选择器如下:
body > div:nth-child(3) > div.site_container.container_detail_top > div > div > div > div:nth-child(3) > div:nth-child(1) > span.type_txt
我们用这个测试一下:
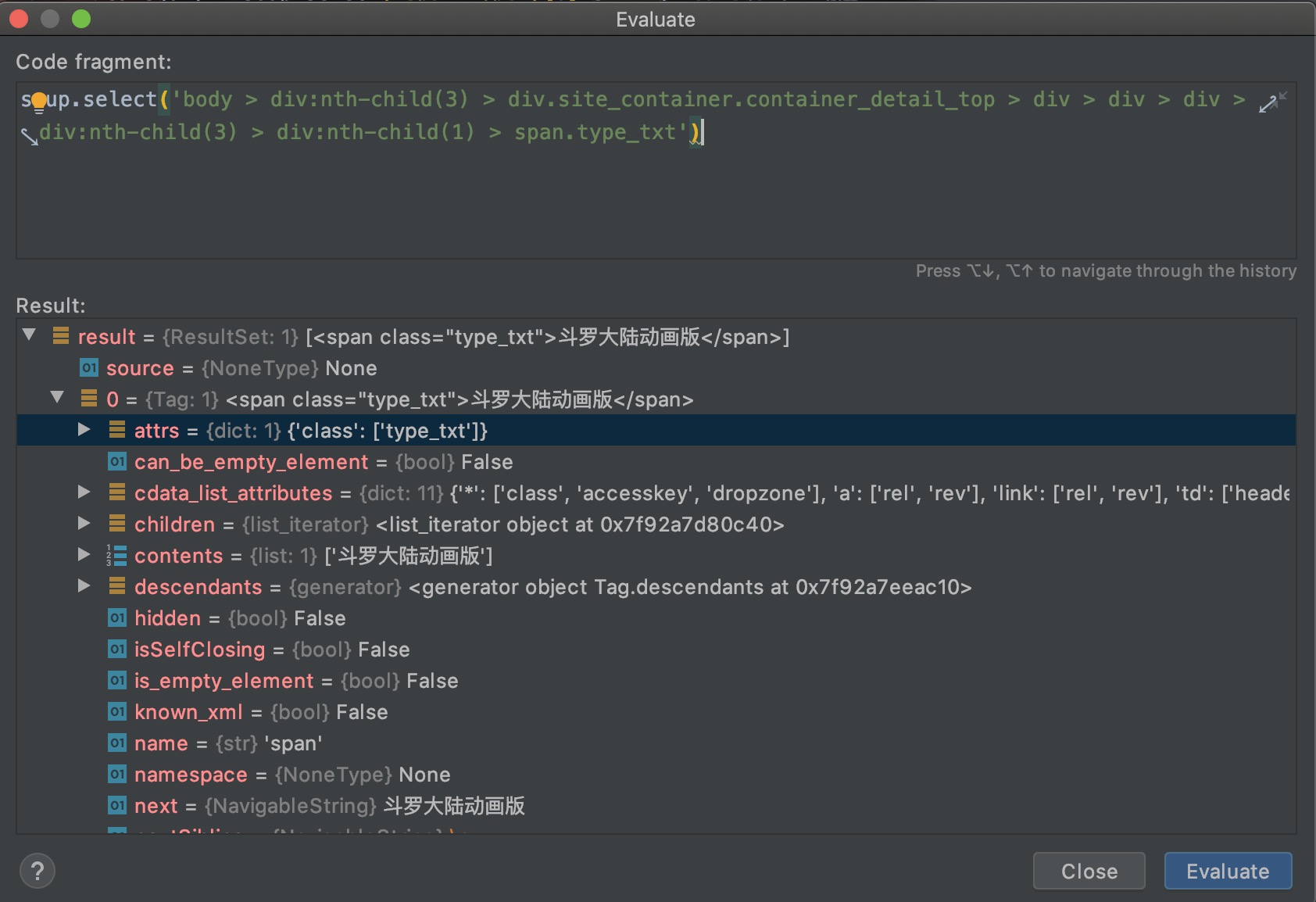
虽然看起来比较长,但还是正确地选择到了span元素。
xpath
xpah全名Xml Path Language(xml路径语言),说实话,我没用过xpath,现学现卖。
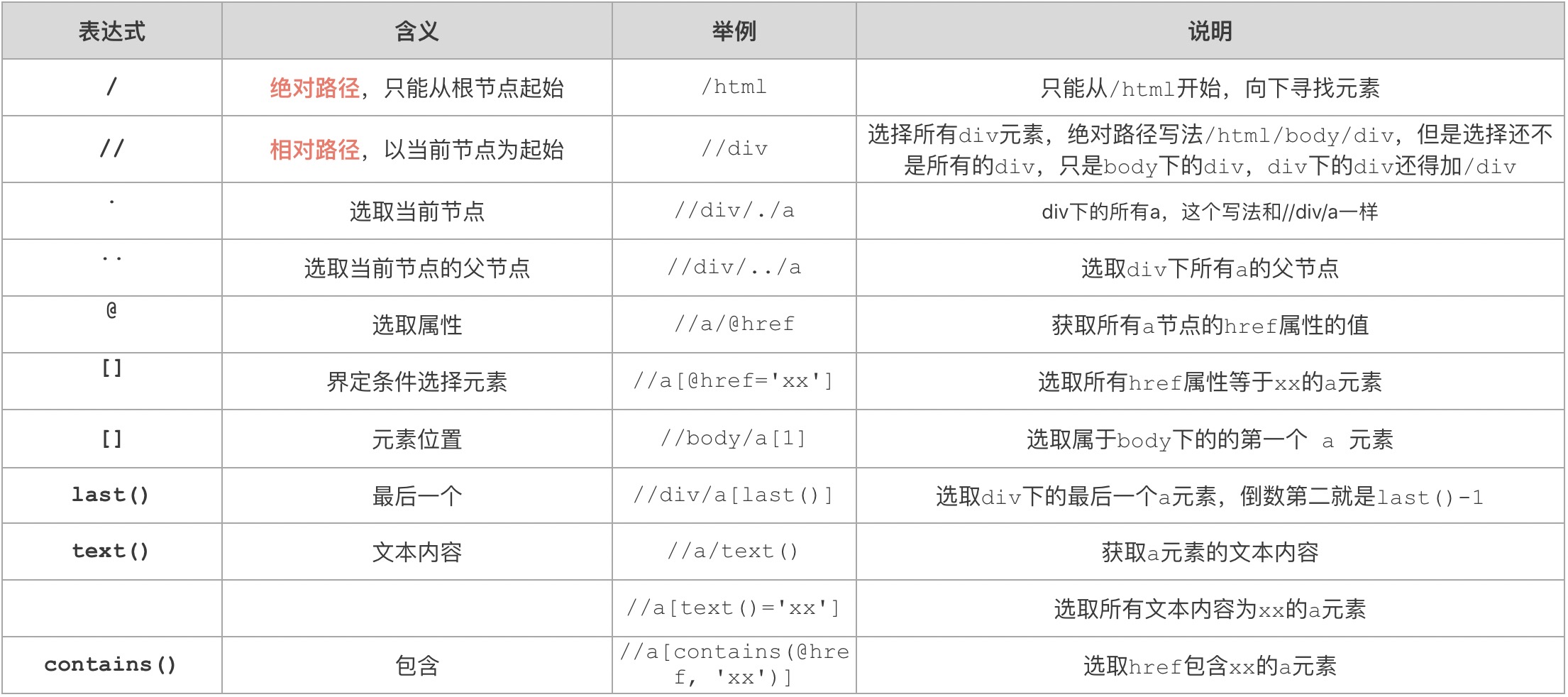
如图是比较常见的xpath语法,我从参考文档、使用测试到整理成表格一共用了半个多小时。从节点选择路径来说,一般相对路径用的比较多。元素后面[]里面的内容就是if条件。
同时,css选择器无法选择元素的父元素,而xpath可以通过../来选择元素的父元素。
样例说明
这个斗罗大陆爬虫样例是博客园的网友从评论区写的,非常感谢。
import requests
from lxml.html import etree
url = 'https://v.qq.com/detail/m/m441e3rjq9kwpsc.html'
response = requests.get(url)
response_demo = etree.HTML(response.text)
# 选择_stat属性为info:title的a元素,/text()表示输出选中的a元素的文本内容
# <a _stat="info:title>斗罗大陆</a>,结果是输出 斗罗大陆
name = response_demo.xpath('//a[@_stat="info:title"]/text()')
# *表示所有节点,所有class="type_txt"的节点的文本
type_txt = response_demo.xpath('//*[@class="type_txt"]/text()')
tag = response_demo.xpath('//*[@class="tag"]/text()')
describe = response_demo.xpath('//*[@class="txt _desc_txt_lineHight"]/text()')
print(name, type_txt, tag, describe, sep='\n')
查看这些变量的值:
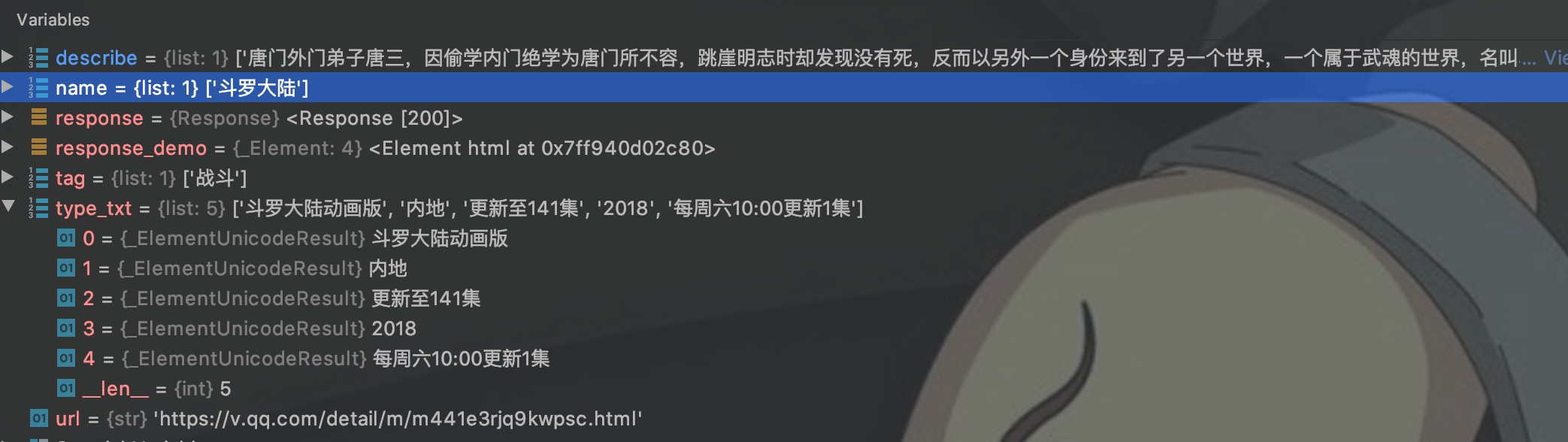
这些变量的类型也是list,也需要用下标或者遍历来取出里面的值。
小技巧
和css一样,不过选择的是Copy Xpath。
复制的xpath:
/html/body/div[2]/div[1]/div/div/div/div[3]/div[1]/span[2]
测试结果:
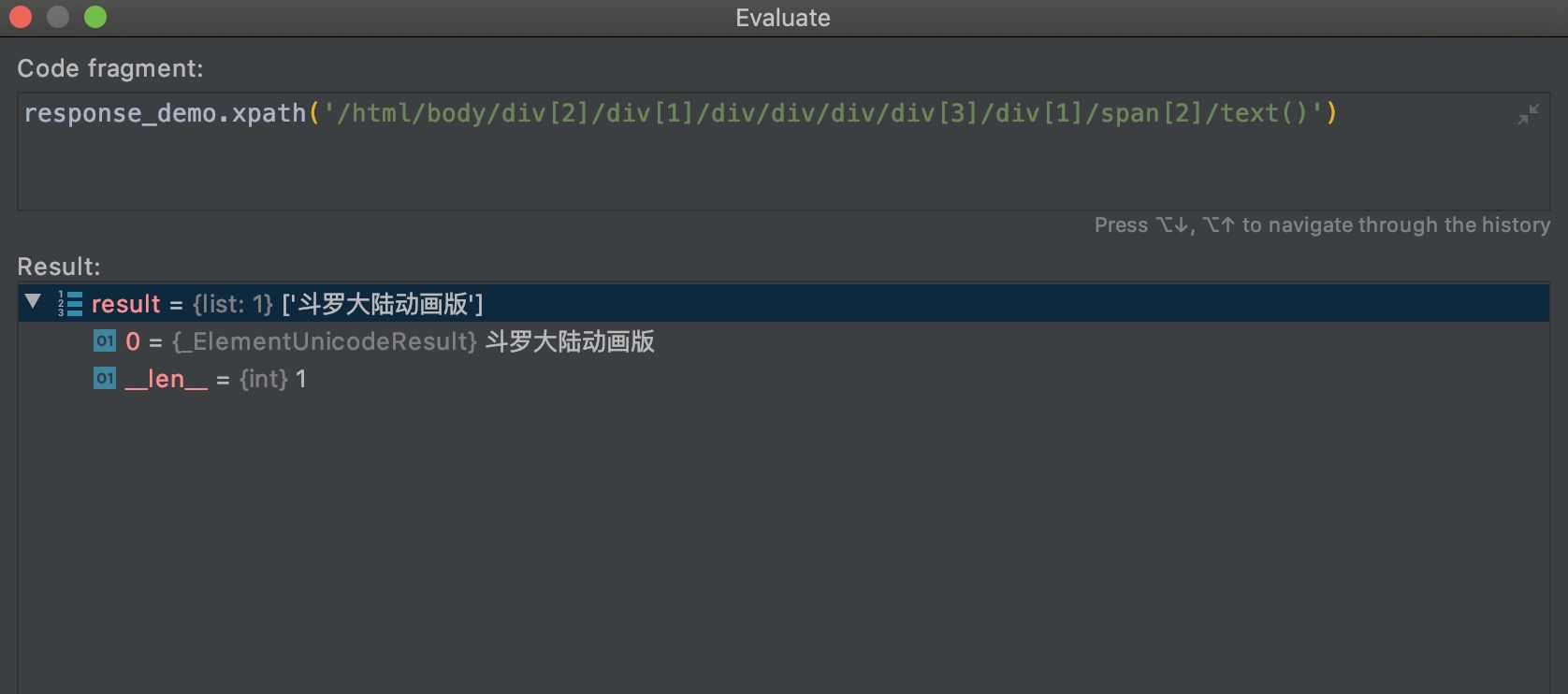
不过要注意的是,xpath一定要对起始点元素做好选择。
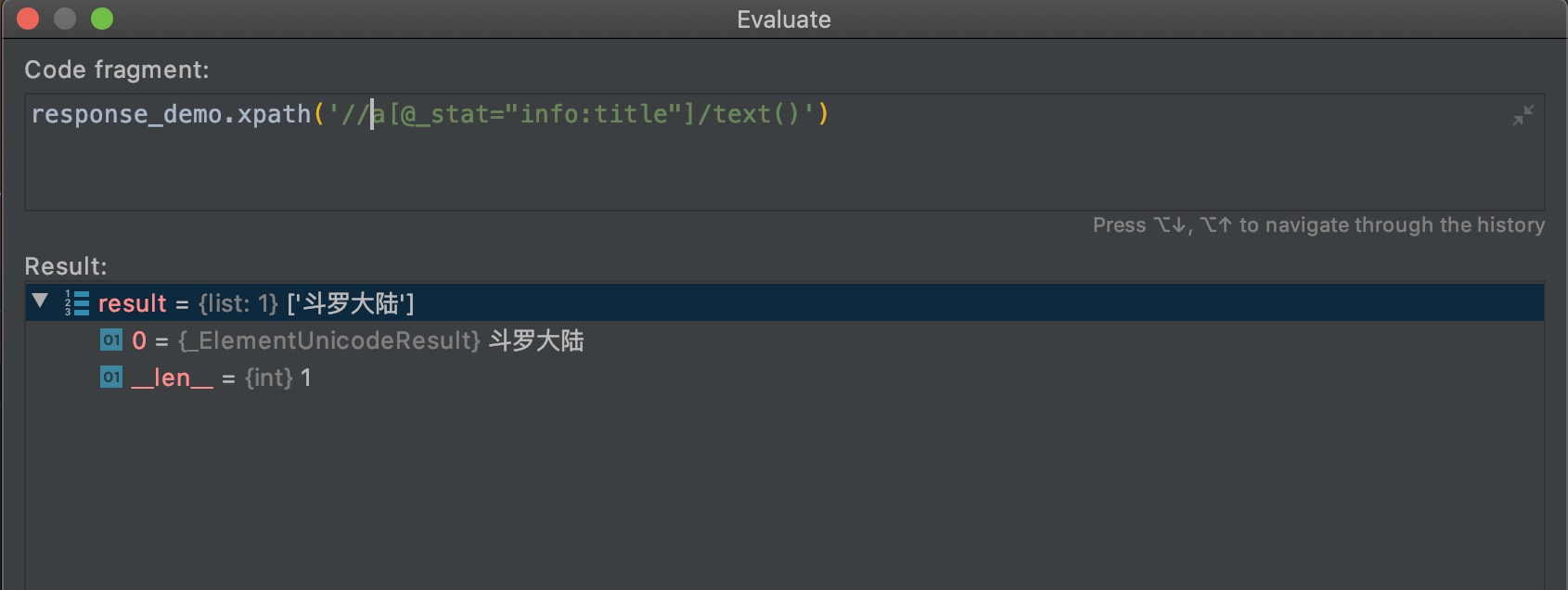
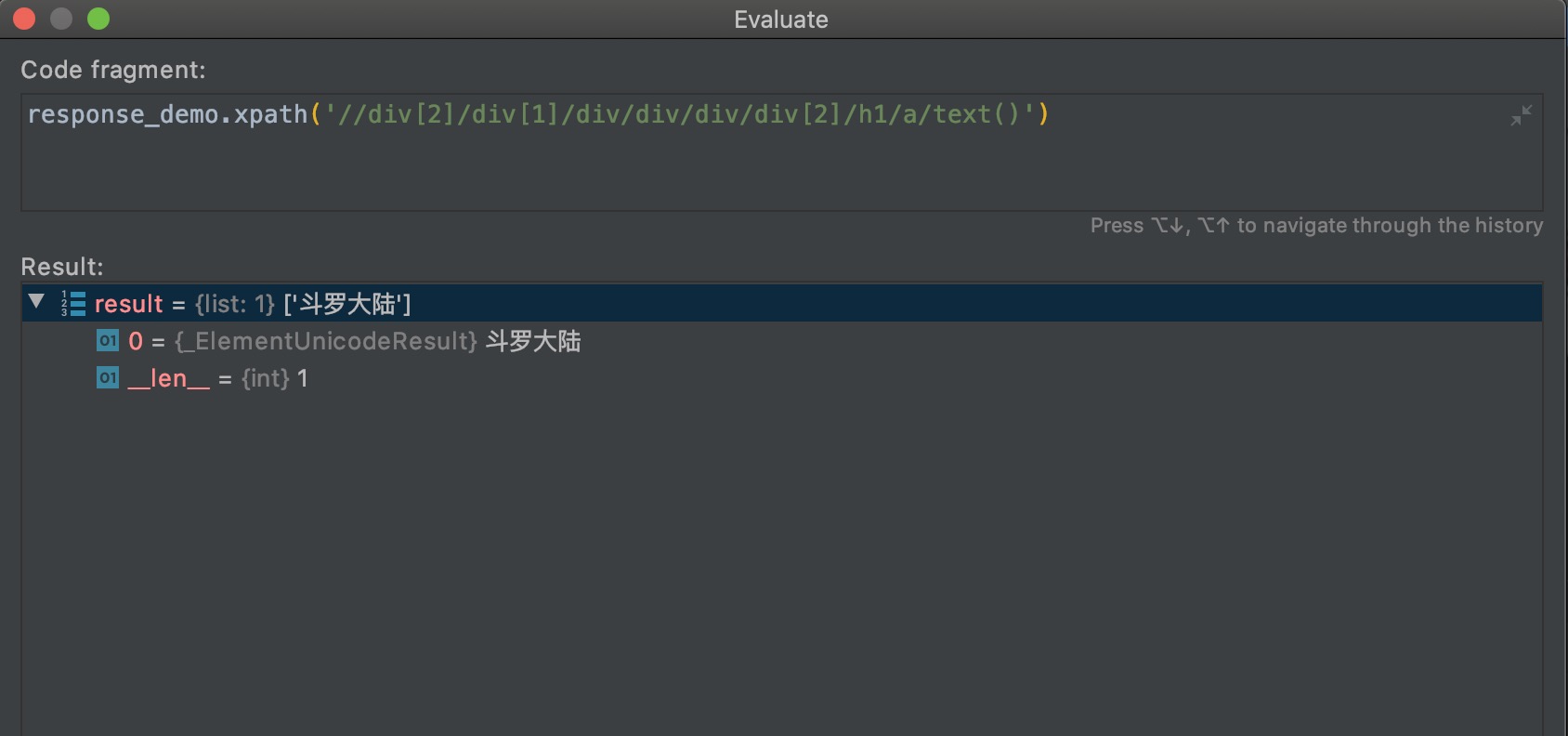
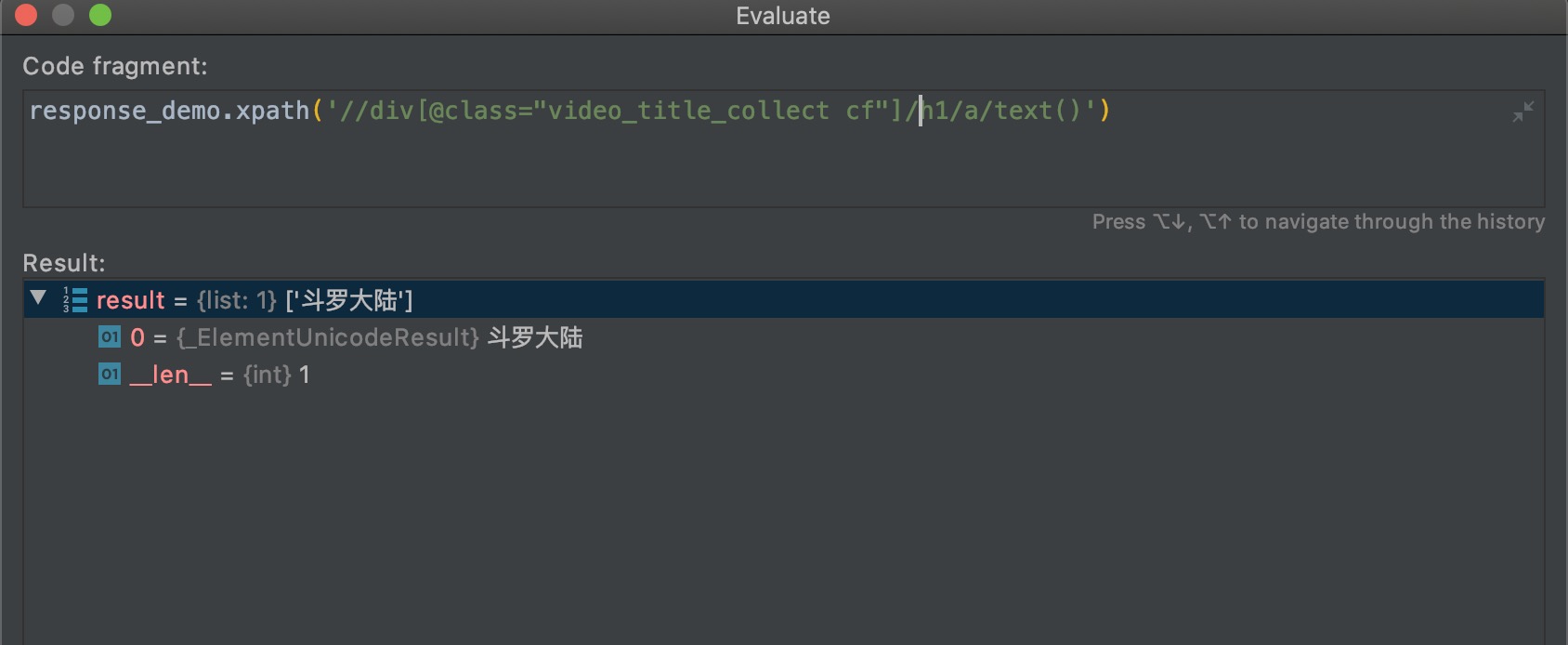
上面三个不一样的xpath输出了同样的结果,起始点元素的选择决定了xpath的复杂度。
性能比较
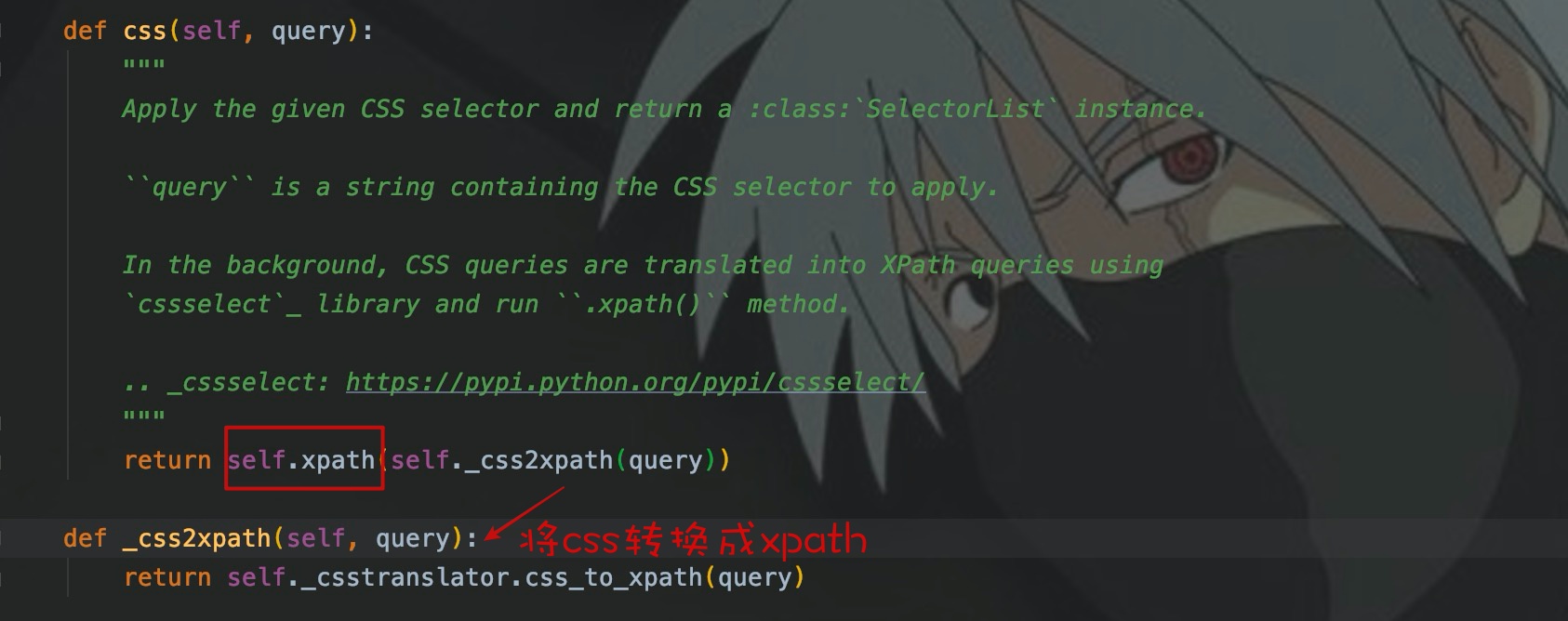
在原生爬虫中,lxml封装的xpath,相对于bs4封装的css性能要好,所以很多人选择使用xpath。在爬虫框架scrapy中,其底层使用的是parsel封装的选择器,css规则最终也会转换成xpath去选择元素,所以css会比xpath慢,因为转换是需要耗时的,但是微乎其微,在实际爬虫程序中基本上感知不到。
结语
本篇文章主要写了一下html的解析,对css选择器和xpath简单的描述了一下。如果想要熟练的使用,还是需要在开发实践中深入理解。
可以根据个人习惯,选择到底是使用css选择器还是xpath,我在scrapy中比较喜欢使用css选择器。因为爬虫也需要控制并发和网站访问频率,所以速度有时候也没有那么重要。期待下一次相遇。
写的都是日常工作中的亲身实践,处于自己的角度从0写到1,保证能够真正让大家看懂。
文章会在公众号 [入门到放弃之路] 首发,期待你的关注。
