 Spark下载
Spark下载
在spark主页的download下,选择自己想要安装的spark版本, 注意跟本地hadoop的兼容性。我这里选择了2.4.0.
https://www.apache.org/dyn/closer.lua/spark/spark-2.4.0/spark-2.4.0-bin-hadoop2.7.tgz
解压与配置环境变量
在master机器上的/opt/spark/下解压安装包
[root@master spark]# tar zxvf spark-2.4.0-bin-hadoop2.7.tgz
在集群各台机器上添加环境变量
vi /etc/profile
export SPARK_HOME=/opt/spark/spark-2.4.0-bin-hadoop2.7/ export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SPARK_HOME/bin:
[root@master spark]# source /etc/profile
配置spark环境
进入spark配置文件路径
[root@master conf]# cd /opt/spark/spark-2.4.0-bin-hadoop2.7/conf
此处需要配置的文件为两个 spark-env.sh和slaves
首先拷贝模板文件
[root@master conf]# cp spark-env.sh.template spark-env.sh
[root@master conf]# cp slaves.template slaves
修改spark-env.sh文件
[root@master conf]# vi spark-env.sh
export JAVA_HOME=/opt/java/jdk1.8.0_191 export HADOOP_HOME=/opt/hadoop/hadoop-2.9.2/ export HADOOP_CONF_DIR=/opt/hadoop/hadoop-2.9.2/etc/hadoop export SPARK_MASTER_IP=192.168.102.3 export SPARK_WORKER_MEMORY=500m export SPARK_WORKER_CORES=1 export SPARK_WORKER_INSTANCES=1
变量说明
- JAVA_HOME:Java安装目录
- HADOOP_HOME:hadoop安装目录
- HADOOP_CONF_DIR:hadoop集群的配置文件的目录
- SPARK_MASTER_IP:spark集群的Master节点的ip地址
- SPARK_WORKER_MEMORY:每个worker节点能够最大分配给exectors的内存大小
- SPARK_WORKER_CORES:每个worker节点所占有的CPU核数目
- SPARK_WORKER_INSTANCES:每台机器上开启的worker节点的数目
这边个人配置都有一定区别,选自己需要的配置就可以了。
修改slaves文件
[root@master conf]# vi slaves
slave1
slave2
将配置好的spark文件夹分发给所有slaves
首先在slave1 和slave2上创建spark文件夹
mkdir /opt/spark/
分发spark
[root@master conf]# scp -r /opt/spark/spark-2.4.0-bin-hadoop2.7 slave1:/opt/spark/ [root@master conf]# scp -r /opt/spark/spark-2.4.0-bin-hadoop2.7 slave2:/opt/spark/
启动Spark集群
因为我们只需要使用hadoop的HDFS文件系统,所以我们并不用把hadoop全部功能都启动。
启动hadoop的HDFS文件系统
[root@master sbin]# start-dfs.sh
启动Spark
因为hadoop/sbin以及spark/sbin均配置到了系统的环境中,它们同一个文件夹下存在同样的start-all.sh文件。所以我把spark的start-all.sh改了一个名字,方便以后使用。
[root@master sbin]# mv start-all.sh start-all-spark.sh
[root@master sbin]# start-all-spark.sh
成功打开之后使用jps在master、slave1和slave2节点上分别可以看到新开启的Master和Worker进程。
[root@master sbin]# jps 4016 Jps 3683 Master 3785 NodeManager 3307 NameNode 3979 JobHistoryServer
[root@slave1 spark]# jps 2420 Worker 2630 NodeManager 2311 DataNode 3082 Jps 2523 ResourceManager
[root@slave2 java]# jps 2547 NodeManager 2693 Jps 2119 SecondaryNameNode 2462 Worker 2047 DataNode
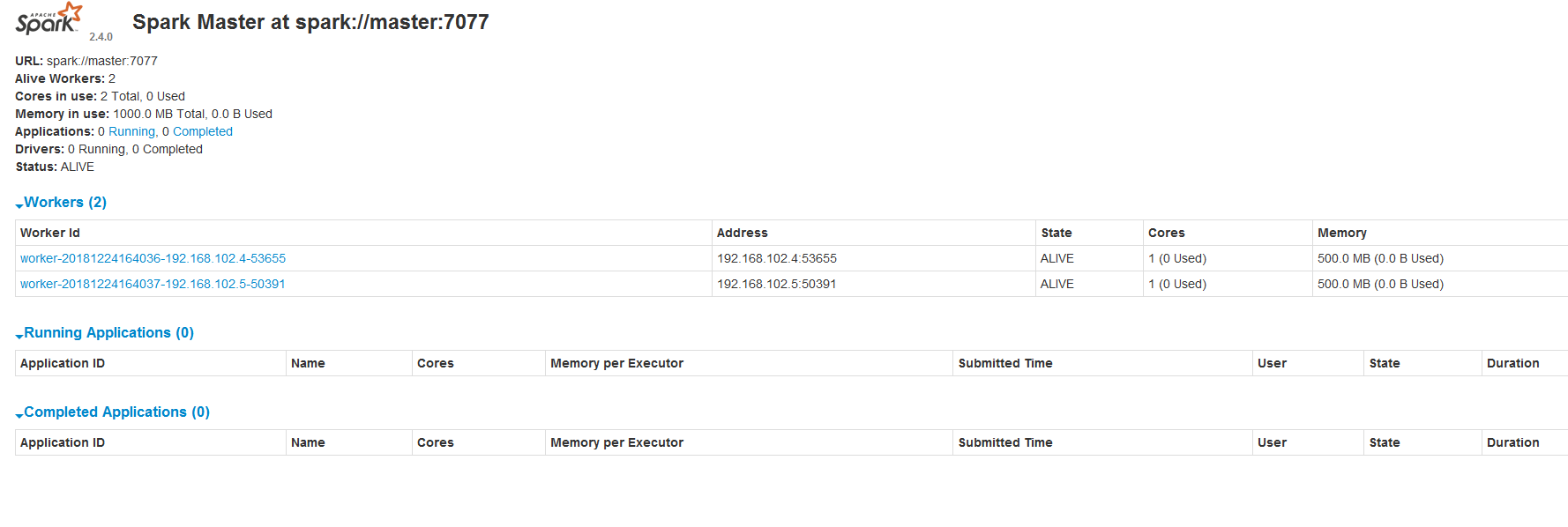
成功打开Spark集群之后可以进入Spark的WebUI界面,可以通过下面地址访问
http://192.168.102.3:8080/