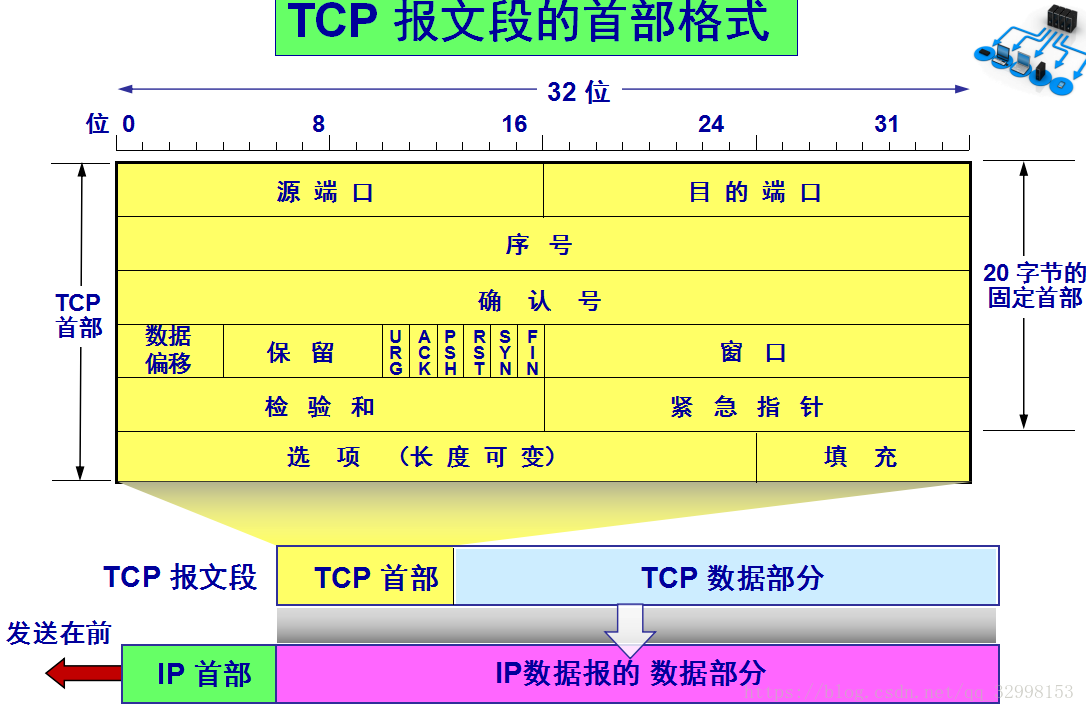
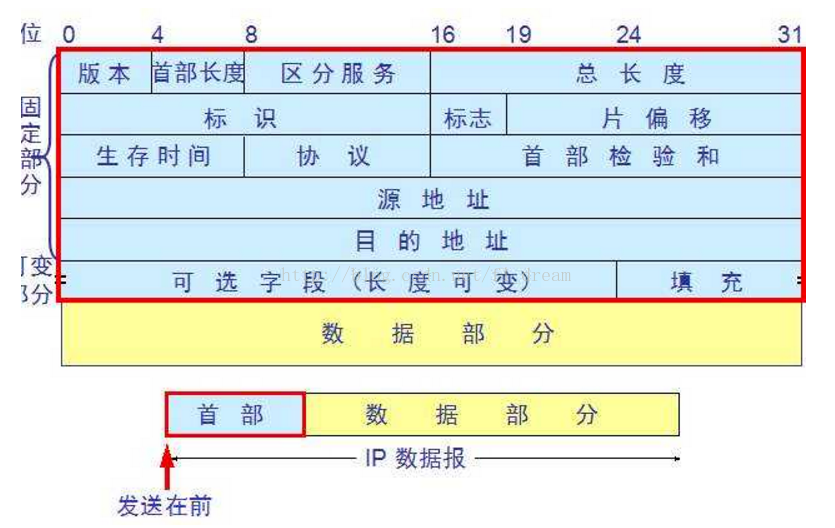
1、IP协议首部 TCP报文段的首部 UDP分组结构 ip数据报 tcp数据报
UDP校验
w


报文长度该字段指定UDP报头和数据总共占用的长度。可能的最小长度是8字节,因为UDP报头已经占用了8字节。由于这个字段的存在,UDP报文总长不可能超过65535字节(包括8字节的报头,和65527字节的数据)。实际上通过IPv4协议传输时,由于IPv4的头部信息要占用20字节,因此数据长度不可能超过65507字节(65,535 − 8字节UDP报头 − 20字节IP头部)。在IPv6的jumbogram中,是有可能传输超过65535字节的UDP数据包的。依据RFC 2675,如果这种情况发生,报文长度应被填写为0。校验和校验和字段可以用于发现头部信息和数据中的传输错误。该字段在IPv4中是可选的,在IPv6中则是强制的。如果不使用校验和,该字段应被填充为全0。
Source port number
This field identifies the sender's port when meaningful and should be assumed to be the port to reply to if needed. If not used, then it should be zero. If the source host is the client, the port number is likely to be an ephemeral port number. If the source host is the server, the port number is likely to be a well-known port number.[4]
Destination port number
This field identifies the receiver's port and is required. Similar to source port number, if the client is the destination host then the port number will likely be an ephemeral port number and if the destination host is the server then the port number will likely be a well-known port number.[4]
Length
A field that specifies the length in bytes of the UDP header and UDP data. The minimum length is 8 bytes because that is the length of the header. The field size sets a theoretical limit of 65,535 bytes (8 byte header + 65,527 bytes of data) for a UDP datagram. However the actual limit for the data length, which is imposed by the underlying IPv4 protocol, is 65,507 bytes (65,535 − 8 byte UDP header − 20 byte IP header).[4]In IPv6 jumbograms it is possible to have UDP packets of size greater than 65,535 bytes.[5] RFC 2675 specifies that the length field is set to zero if the length of the UDP header plus UDP data is greater than 65,535.
Checksum
The checksum field may be used for error-checking of the header and data. This field is optional in IPv4, and mandatory in IPv6.[6] The field carries all-zeros if unused.[7]
https://zh.wikipedia.org/wiki/用户数据协议
由于缺乏可靠性且属于非连接导向协议,UDP应用一般必须允许一定量的丢包、出错和复制粘贴。但有些应用,比如TFTP,如果需要则必须在应用层增加根本的可靠机制。但是绝大多数UDP应用都不需要可靠机制,甚至可能因为引入可靠机制而降低性能。流媒体(流技术)、即时多媒体游戏和IP电话(VoIP)一定就是典型的UDP应用。如果某个应用需要很高的可靠性,那么可以用传输控制协议(TCP协议)来代替UDP。
由于缺乏拥塞控制(congestion control),需要基于网络的机制来减少因失控和高速UDP流量负荷而导致的拥塞崩溃效应。换句话说,因为UDP发送者不能够检测拥塞,所以像使用包队列和丢弃技术的路由器这样的网络基本设备往往就成为降低UDP过大通信量的有效工具。数据报拥塞控制协议(DCCP)设计成通过在诸如流媒体类型的高速率UDP流中,增加主机拥塞控制,来减小这个潜在的问题。
典型网络上的众多使用UDP协议的关键应用一定程度上是相似的。这些应用包括域名系统(DNS)、简单网络管理协议(SNMP)、动态主机配置协议(DHCP)、路由信息协议(RIP)和某些影音流服务等等。
https://www.lifewire.com/tcp-headers-and-udp-headers-explained-817970
http://www.cnpaf.net/Class/UDP/200408/197.html
UDPvs.TCP
UDP和TCP协议的主要区别是两者在如何实现信息的可靠传递方面不同。TCP协议中包含了专门的传递保证机制,当数据接收方收到发送方传来的信息时,会自动向发送方发出确认消息;发送方只有在接收到该确认消息之后才继续传送其它信息,否则将一直等待直到收到确认信息为止。
与TCP不同,UDP协议并不提供数据传送的保证机制。如果在从发送方到接收方的传递过程中出现数据报的丢失,协议本身并不能做出任何检测或提示。因此,通常人们把UDP协议称为不可靠的传输协议。
相对于TCP协议,UDP协议的另外一个不同之处在于如何接收突法性的多个数据报。不同于TCP,UDP并不能确保数据的发送和接收顺序。例如,一个位于客户端的应用程序向服务器发出了以下4个数据报
D1
D22
D333
D4444
但是UDP有可能按照以下顺序将所接收的数据提交到服务端的应用:
D333
D1
D4444
D22
事实上,UDP协议的这种乱序性基本上很少出现,通常只会在网络非常拥挤的情况下才有可能发生。
UDP协议的应用
也许有的读者会问,既然UDP是一种不可靠的网络协议,那么还有什么使用价值或必要呢?其实不然,在有些情况下UDP协议可能会变得非常有用。因为UDP具有TCP所望尘莫及的速度优势。虽然TCP协议中植入了各种安全保障功能,但是在实际执行的过程中会占用大量的系统开销,无疑使速度受到严重的影响。反观UDP由于排除了信息可靠传递机制,将安全和排序等功能移交给上层应用来完成,极大降低了执行时间,使速度得到了保证。
关于UDP协议的最早规范是RFC768,1980年发布。尽管时间已经很长,但是UDP协议仍然继续在主流应用中发挥着作用。包括视频电话会议系统在内的许多应用都证明了UDP协议的存在价值。因为相对于可靠性来说,这些应用更加注重实际性能,所以为了获得更好的使用效果(例如,更高的画面帧刷新速率)往往可以牺牲一定的可靠性(例如,会面质量)。这就是UDP和TCP两种协议的权衡之处。根据不同的环境和特点,两种传输协议都将在今后的网络世界中发挥更加重要的作用
http://view.inews.qq.com/a/20161025A0766200
窄带时代的QQ
QQ是窄带时代极具代表性的产品,在那个网络传输效率比较低的年代,大家还记得Google的首页吗?Google的那个简洁页面,为什么如此简洁?
Google诞生于1998年,也是身处窄带时代,你会发现它的首页字节大小是小于1024的,为什么要小于1024字节,因为以太网的MTU(也就是最大传输单元)是1024,Google为了让用户在一个网络包中传输完成,所以它把页面大小降到了1024以下。这是一种极致传输的表现。
QQ的背后也同样蕴藏着诸多类似的极致追求,早期的QQ客户端安装包是几十k大小,这是为了让用户更快下载,更方便使用。
QQ的传输通信是修改了底层TCP/IP协议栈的,这个技术非常难,因为需要改linux kernel,之所以这样是因为QQ希望传输协议既具备TCP的丢包重传能力,又要具备UDP的高性能,这样QQ可以在保证传输信息的同时又可以维护更多的用户网络连接,在那个年代QQ的单位后台处理能力可能是其他同类产品的10倍以上。
什么是AI?
AI是研究如何应用计算机的软硬件来模拟人类某些智能行为的基本理论、方法和技术。AI包括:计算机视觉、语音识别、自然语音处理等类似人类的感知、认知智能。
当下很多人认为AI就是机器学习,或者说是深度学习。这是很狭义的。
机器学习是AI的核心算法。确切的讲AI和机器学习的关系是这样的:AI = A->f(x)->B,机器学习是人类智能行为的一种拟合函数。
目前的AI总体来讲还是一个非常初级的阶段,虽然我们在某些“感知”智能上有些突破。
比如我们在计算机视觉上的人脸识别能力,语音识别上的速记能力等垂直领域已经接近或者超过人的平均智能水平。但是这些相对于一个人的综合智能来讲还非常狭窄,本质上我觉得还是算法本身还需要更高维的突破,而不是简单的演进。
比如我们针对视觉的AlexNet到VGG再到现在的ResNet,每次算法的演进还只是停留在更深的神经网络,更复杂的神经网络连接的设计上,通过这样复杂的神经网络学习更多的样本特征来更好的拟合人脑的“感知”。
再比如“认知”智能的自然语言处理,但是面对这种语言序列问题,尽管我们的神经网络从早期的RNN演进到LSTM,再到现在的Attention Model,但至今为止机器还无法完全胜任这种复杂计算。
关于IP协议首部长度的计算 - LAMP - CSDN博客 https://blog.csdn.net/fl_dream/article/details/78761713
TCP报文段的首部格式 - qq_32998153的博客 - CSDN博客 https://blog.csdn.net/qq_32998153/article/details/79680704