概述:
什么是Solr?
Solr是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务.Solr可以独立运行在Jetty.tomcat.webLogic.webShell等这些Servlet容器中.
全文检索服务(也叫做全文搜索): 服务 是War包.
ES框架 也是基于Lucene,Lucene(是工具包 jar)
服务器: Tomcat Jetty(内嵌服务器) 免费的(私企)
WebLogic(Oracle)政府 Oracle
WebShell(IBM) 收费的 DB2
内嵌服务器和外部的服务器
Tomcat(外部) /webapps/war
War/lib/jetty.jar(内嵌) 稳定性差了点. 测试环境下使用.
1.开发环境 (软件开发工程师) jetty
2.测试环境 (测试工程师) 黑盒 白盒 (既能够测试功能,又能测试代码质量) jetty
3.生产环境 (线上运营) 京东,淘宝 等可以开始卖货了. tomcat
使用Solr进行创建索引和搜索索引的实现方法很简单,如下:
客户端: PHP C++ .NET JAVA
服务端:(War) 在tomcat上运行, 安装jdk, HTTP协议
要使用Solr的两步:
1. 安装服务端(服务端+索引库)
2.java写客户端(java代码可以写客户端,浏览器也可以充当客户端)
Solr的java客户端:
1.创建索引(包含了删,加,改): java客户端以POST方式,发送xml格式字符串给服务端, 服务端返回xml格式字符串.
2.搜索索引: java客户端Get方式 发送json或者xml 返回值json或者xml
后台管理中心(浏览器打开界面) 管理索引
删除
添加
修改
查询
(上面的统称为管理)
创建索引:客户端(可以是浏览器可以是java程序)用POST方法向Solr服务器发送一个描述Field及其内容的XML文档,Solr服务器根据xml文档添加,删除,更新索引.
搜索索引:客户端(可以是浏览器可以是JAVA程序)用GET方法向Solr服务器发送请求,然后对Solr服务器返回XML.json等格式的查询结果进行解析.Solr不提供构建页面UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况.
Solr是一个可以独立运行的搜索服务器,使用solr进行全文检索服务的话,只需要通过http请求访问该服务器即可.
Solr和Lucene的区别?
Lucene是一个开放源代码的全文检索引擎工具包,它是一个完整的全文检索应用.Lucene仅提供了完整的查询引擎和索引引擎,目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者以Lucene为基础构建全文检索应用.
Solr的目标是打造一款企业级的搜索引擎系统,它是基于Lucene一个搜索引擎服务.可以独立运行,通过Solr可以非常快速的构建企业的搜索引擎,通过Solr也可以高效的完成站内搜索功能.
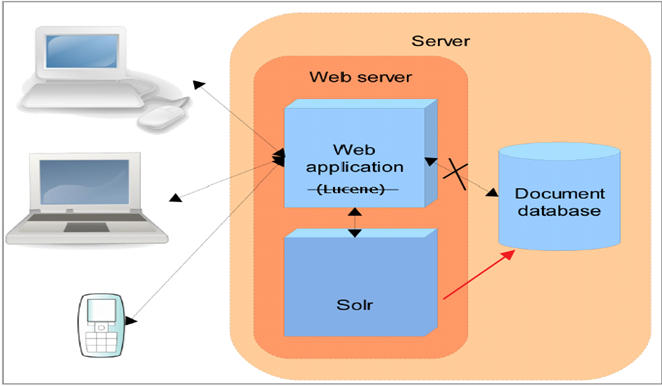
原来的方式,是直接通过web服务器,然后通过Lucene直接使用索引库,但是如果不使用Lucnene的时候,就直接使用Solr来连接索引库.
相对来说Lucene的速度更快,
简单的说 :
1.Lucene 是工具包 是jar包
2.Solr是索引引擎服务 War
3.Solr是基于Lucene(底层是由Lucene写的)
4.上面二个软件都是Apache公司由java写的
在Solr的后端界面

在Solr的集群的时候,会有Master(主人) Slave(奴隶)
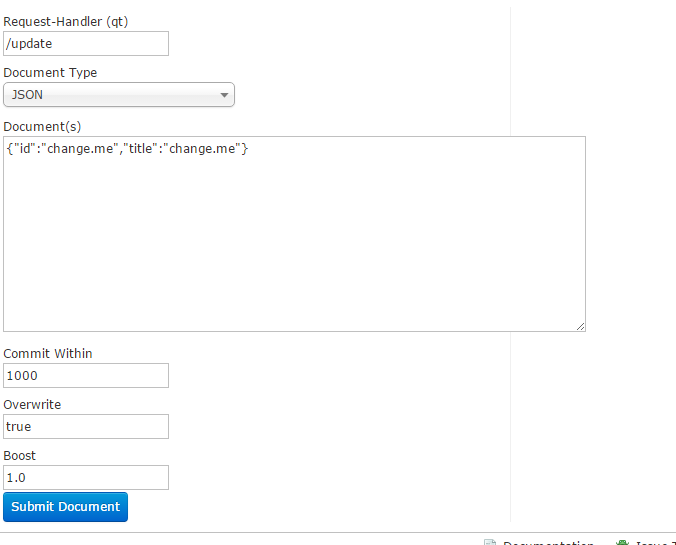
Solr基于Lucene
ID域 必须有 不可重复 字符串类型(中文 正数)
名称域
描述域
价格域
路径域
有事务 提交事务
1.主动提交
2.自动提交,提前设置提交时间 毫秒
Overwrite
当ID相同时,可以进行覆盖
Boost 相关度
什么是相关度?
相关度 = 词出现的次数*Boost
相关度越高,在查询的时候,越靠前.