一、引言
ClickHouse 是一个用于联机分析( OLAP )的列式数据库管理系统( DBMS )。它于 2016 年以 Apache 2.0 协议开源,以优秀的查询性能,深受广大大数据工程师欢迎。
为了服务客户业务,腾讯云于 2020 年 4 月正式上线 ClickHouse 服务。服务上线以来,迅速获得内外客户广泛支持,服务业务数量成规模增长。与此同时,运维与管控压力也随之而来,用户对弹性伸缩能力的呼声越来越大。
事实上,ClickHouse 是典型的 Share-Nothing 架构,天然支持弹性伸缩能力。无论是增加节点数量,还是增加数据分片副本数量都非常容易。
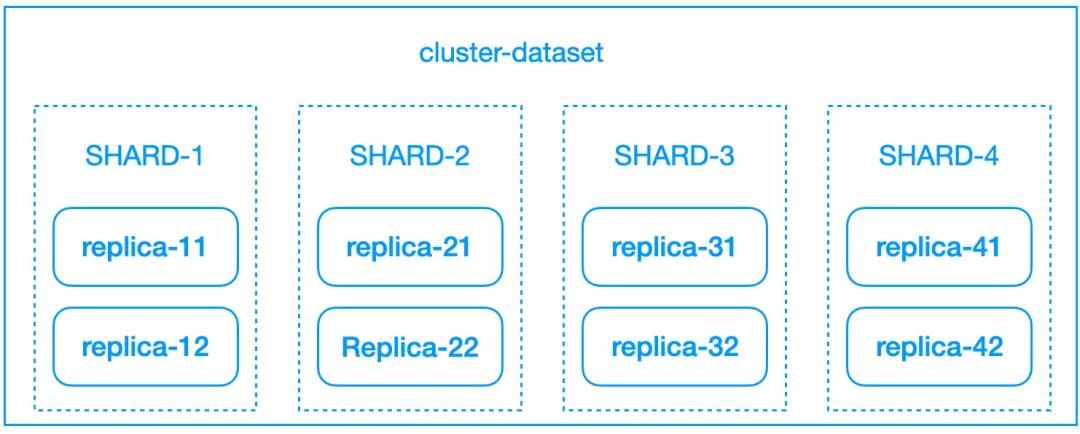
图1 ClickHouse Share-Nothing 架构
但是,ClickHouse 集群在增加节点后,集群上的数据集无法自动均衡分布。需要人工干预,确保数据均衡。同理,下线集群节点前,也需要人工干预,将被下线节点的机器迁移到其他节点。
在生产环境中,运维工作强度随着集群中表的数量,数据规模增加而急剧增强。为了缓解云上 ClickHouse 用户运维压力,将 ClickHouse 数据均衡运维工作自动化是非常有价值的。
本文将带大家了解腾讯云 ClickHouse 是如何实现无人值守的数据均衡服务,希望与大家一同交流。
二、ClickHouse集群数据均衡功能缺失
在生产环境中,通常 ClickHouse 通常以集群模式部署。在 ClickHouse 集群中,用户根据业务需求将集群节点划分为若干子集合。每个集合存储若干数据集,在使用层面,用户通过分布式表( Distributed Engine )来查询整个数据集。
在 ClickHouse 的语义中,有一个 Cluster 概念,它是一个节点的集合,并且定义了存储在该 Cluster 上的数据集的分片数量,以及分片的副本数量,以及其存储节点。
如上图 1 所示,一个名为 cluster-dataset 的 Cluster, 定义了 4 个分片( SHARD ), 每个分片有 2 个副本。当存储在这个 Cluster 上的数据集,通常会分散存储在 4 个分片中,并且每个分片数据会存储 2 个副本。
为 Cluster 增加分片是非常容易,分配机器,修改配置即可。如下图所示,给 cluster-dataset 增加一个分片。但是已存的数据数据集仍然在分片 SHARED1-4 上。很明显,新增的节点存在资源浪费的问题,包括计算资源和存储资源。
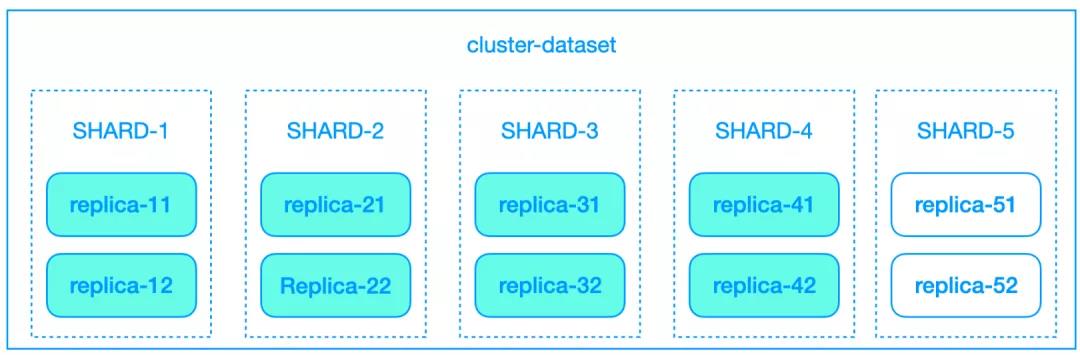
图2:扩容节点示意图
为了解决这样问题,有若干方案解决:
-
将数据全部删除掉,从后备数据源重新导入数据到 ClickKhouse;
-
增加新节点的权重,过一定时间后待数据均衡后,重新调整新增节点权重;
-
其他,如人工搬运数据到新增节点
但是无论使用上述哪一种种方法,都存在缺陷。比如对于第一个方案而言,如果 ClickHouse 中数据并无后备数据源,那么该方案不可行。即使有后备数据源,重新导入数据耗时,且停服时间与数据量成正比,代价大。
对于第二种方案,需要对新节点进行多次权限调整。在调整期间,数据存储压力向新增节点倾斜,无法充分利用集群优势。且容易导致新近数据集中在新增节点上,导致集群资源浪费,降低查询效率。
对于第三种方案而言,操作繁杂,在表多,数据量大的情况下,易出错。
三、云上ClickHouse解决方案
为了解决 ClickHouse 集群数据均衡功能缺失,带来的运维压力,腾讯云 ClickHouse 提供了数据自动均衡功能。
简而言之,在获得用户授权后,用户在控制台上简单配置,填写数据迁移网络带宽上限,即可启动数据均衡任务。
后台管控系统根据机器当期磁盘可用容量,合理安排数据迁移计划。然后,根据网络带宽上限,执行迁移计划。最终,使得数据在节点上分布趋于均衡。
举一个例子来进行说明,在云上申请一个 ClickHouse 实例,2 个节点。在其中一个节点上创建一个名为 lineorder 的表,并导入测试数据。查看该表在该节点上的存储容量,结果如下所示:

另外一个节点上没有该表的数据,也没有表的 schema。我们通过数据迁移功能完成数据均衡。接下来通过控制台,我们完成数据迁移。具体步骤如下:
1. 选择Cluster
选择 Cluster,选择 ClickHouse 实例,点击集群服务,选择 ClickHouse 组件,在"操作"下拉列表中,选择数据迁移菜单项。选择数据均衡模式。

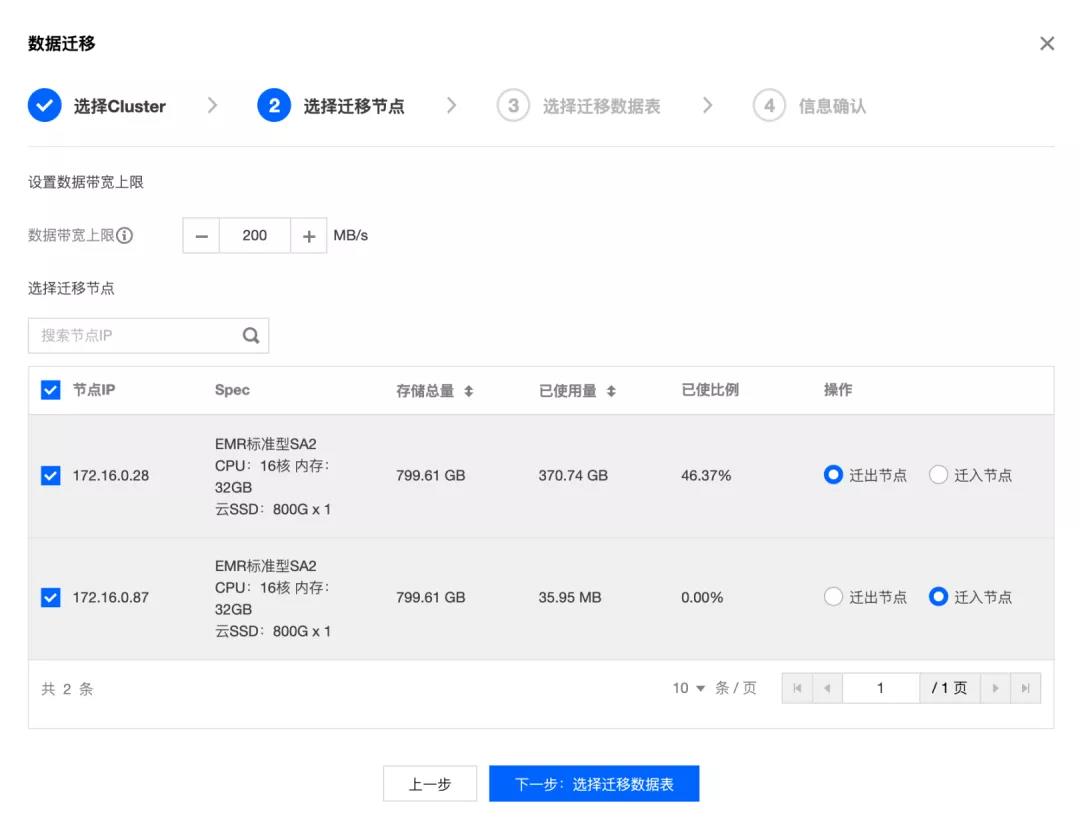
2. 选择迁移节点
在确定 Cluster 后,可以选择数据迁出与迁入节点。
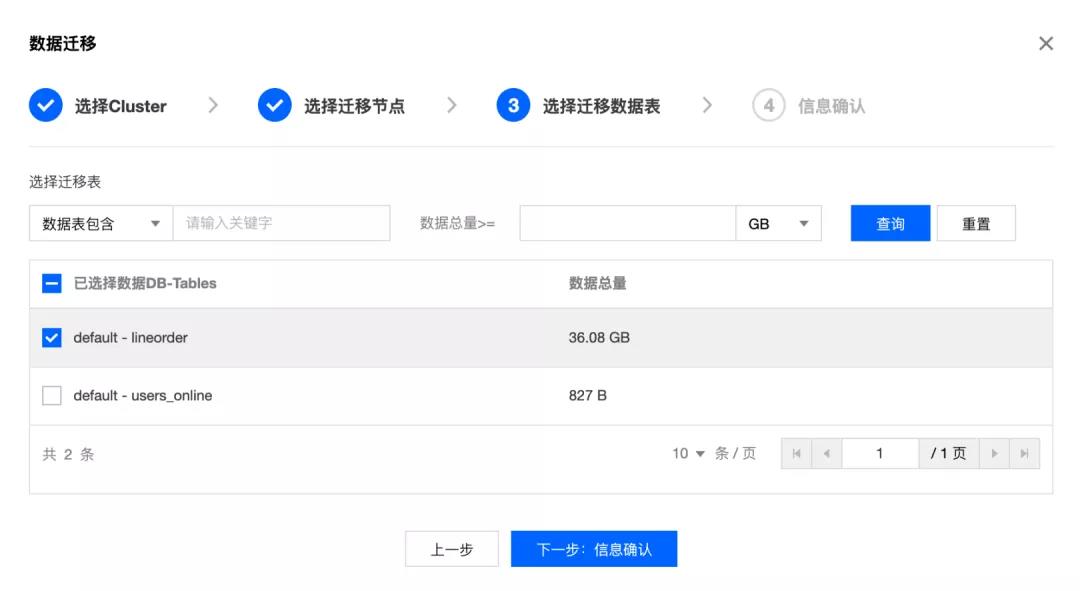
3. 选择迁移数据表
在确定了迁移节点后,我们可以选择待迁移的表。
4. 确认信息
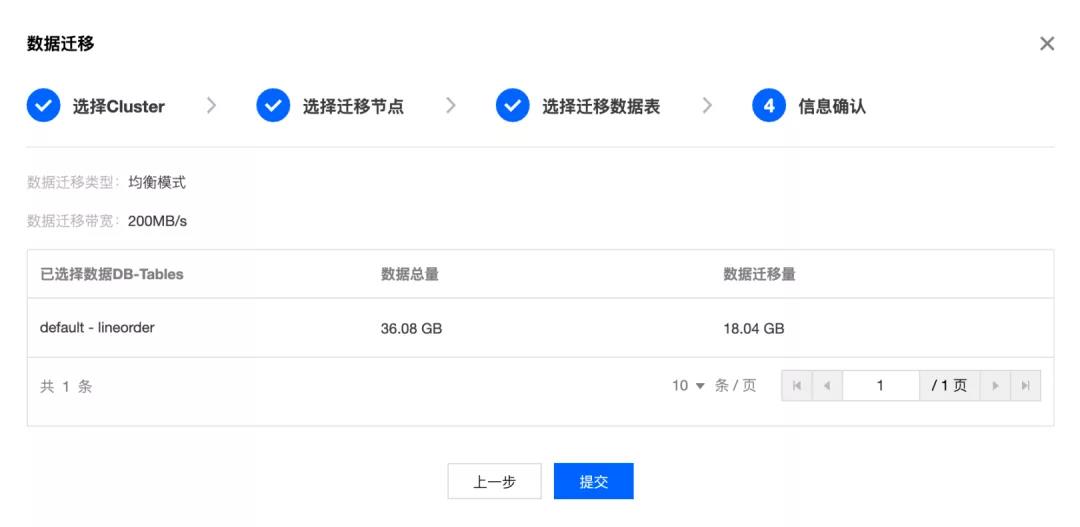
最后,提交任务。ClickHouse 就开始数据迁移工作。在任务中心可以看到数据迁移进度。

任务结束时候,也可以查看迁移任务详情信息。
待数据迁移完成后,我们可以查看数据在两个节点上数据分布情况。在集群节点上数据量情况如下:

可以看到,数据迁移完成后,数据条数和数据量是完全吻合的。
四、结语
云上数据迁移功能旨在解决 ClickHouse 弹性伸缩时数据迁移问题。使用场景包括:
-
新扩容节点后,使用数据迁移功能,迁移部分数据至新节点,让数据在集群节点上趋于均衡;
-
缩容节点前,将待下线节点上的数据迁移到其他节点,避免数据丢失。
数据迁移功能极大的缓解了集群版 ClickHouse 运维压力。需要注意的是,数据均衡任务运行过程中,被迁移的表无法被业务访问。