本篇博客将带领大家梳理爬虫中的requests模块,并结合Github的自动登入验证具体讲解requests模块的参数。
一.引入:
我们先来看如下的例子,初步体验下requests模块的使用:
response = requests.get("http://dig.chouti.com/")
print(type(response))
print(response.status_code)
print(response.encoding)
print(response.cookies)
打印结果如下:
<class 'requests.models.Response'>
200
UTF-8
<RequestsCookieJar[<Cookie gpsd=b2ee6ddbe10a221eef5fb6584f9c6752 for .chouti.com/>, <Cookie JSESSIONID=aaaqP27NfnSMk7BRn76cw for dig.chouti.com/>, <Cookie route=37316285ff8286c7a96cd0b03d38e13b for dig.chouti.com/>]>
以上代码我们请求了本站点的网址,然后打印出了返回结果的类型,状态码,编码方式,Cookies等内容。
二.Get请求
1.基本get请求:只需要传入待访问的url地址即可访问,response.text返回的是网页的字符串源代码
import requests
response=requests.get('http://dig.chouti.com/')
print(response.text, type(response.text))
如果我们需要访问图片,音频,视频等二进制数据,那么就使用response.content即可。
2.带参数的GET请求->params
#在请求头内将自己伪装成浏览器,否则百度不会正常返回页面内容,这里使用headers参数;
# 在实际生产环境下,我们通常使用一个开源的库:fake-useragent;
使用方法如下:
pip install fake-useragent或者pip3 install fake-useragent
使用该库可以伪装成各大浏览器的请求:
from fake_useragent import UserAgent
ua = UserAgent()
# ie浏览器的user agent
print(ua.ie)
# opera浏览器
print(ua.opera)
# Chrome浏览器
print(ua.chrome)
# firefox浏览器
print(ua.firefox)
# safri浏览器
print(ua.safari)
最实用的
但我认为写爬虫最实用的是可以随意变换headers,一定要有随机性。在这里我写了三个随机生成user agent,三次打印都不一样,随机性很强,十分方便。
from fake_useragent import UserAgent
ua = UserAgent()
print(ua.random)
print(ua.random)
print(ua.random)
爬虫中具体使用方法
import requests
from fake_useragent import UserAgent
ua = UserAgent()
headers = {'User-Agent': ua.random}
url = '待爬网页的url'
resp = requests.get(url, headers=headers)
#省略具体爬虫的解析代码,大家可以回去试试
...
如果查询关键词是中文或者有其他特殊符号,则不得不进行url编码,例如我在百度中输入关键词美女,那么就要使用urllib模块的urlencode方法对文中进行编码了,如下所示:
from urllib.parse import urlencode
params = {
'wd': '美女',
}
url = 'https://www.baidu.com/s?%s' % urlencode(params, encoding='utf-8')
print(url) # 打印结果:https://www.baidu.com/s?wd=%E7%BE%8E%E5%A5%B3
我们去浏览器中观察下,看是否满足我们的预期:
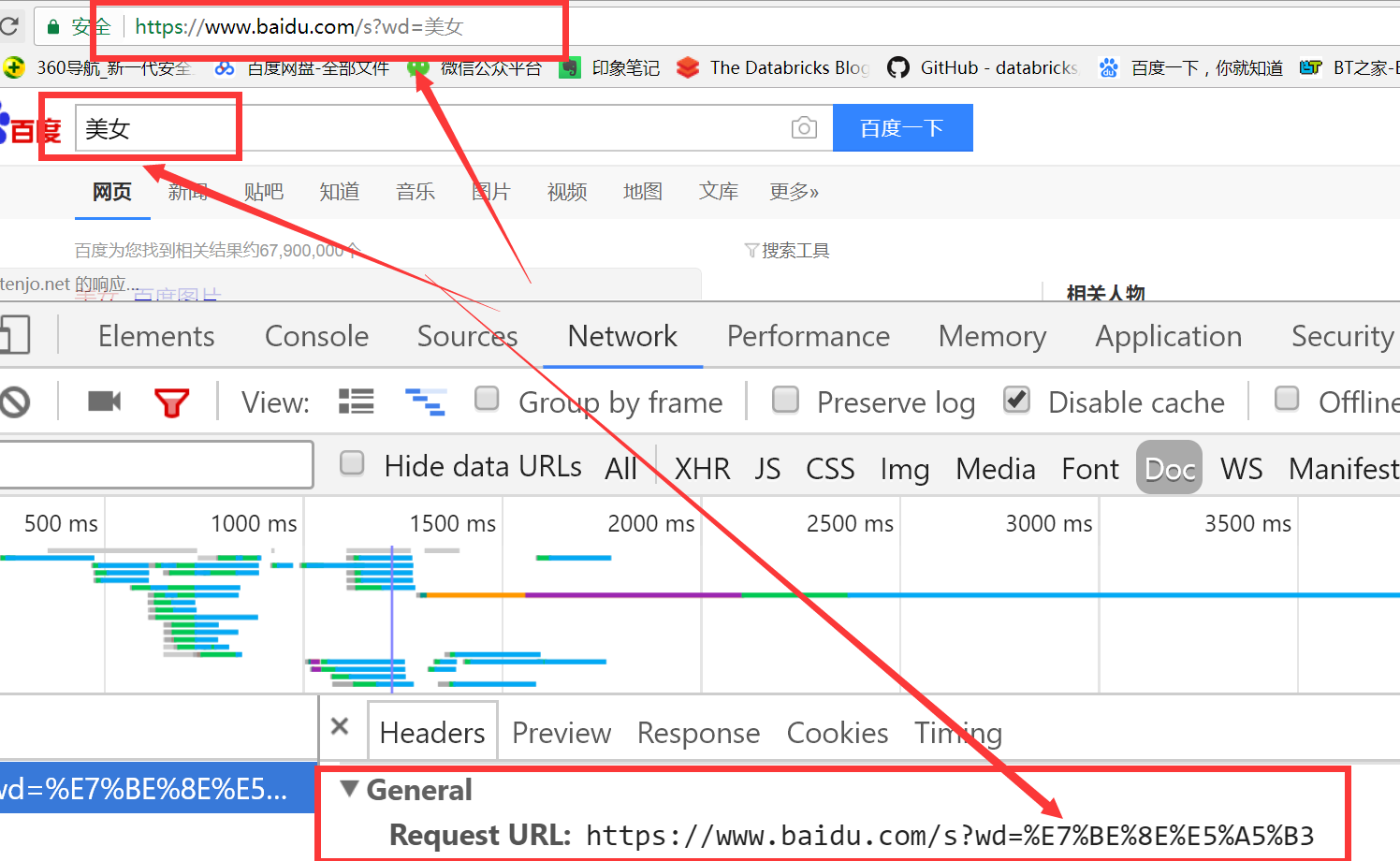
实际上,requests模块已经帮我们封装好了上面的过程,直接使用params参数即可,继续看下面的代码,我们在百度中输入美女,然后向后翻页,观察此时浏览器中的地址变化:
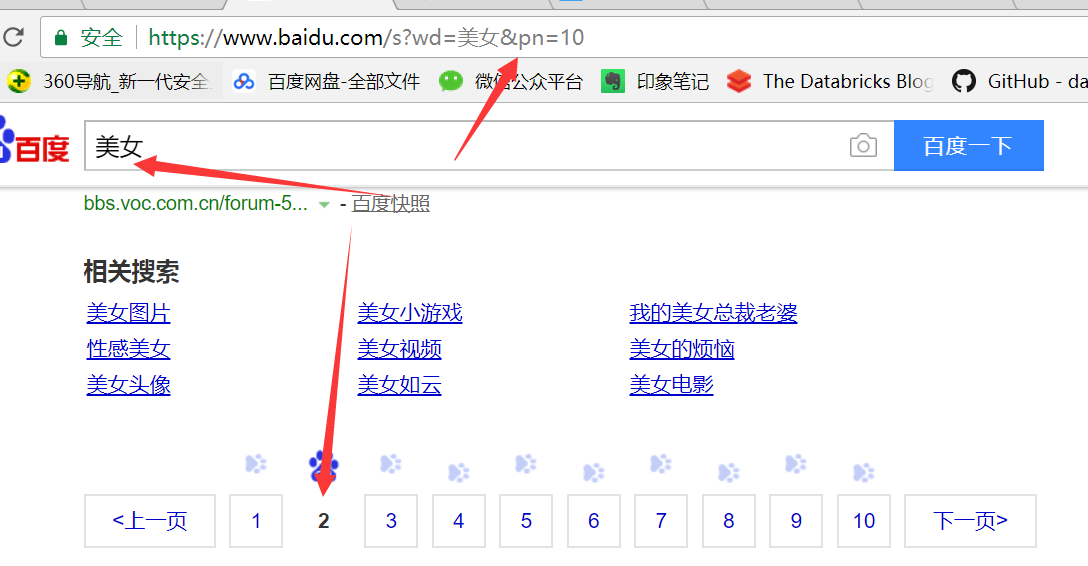
同时观察Chrome浏览器中Network的变化:
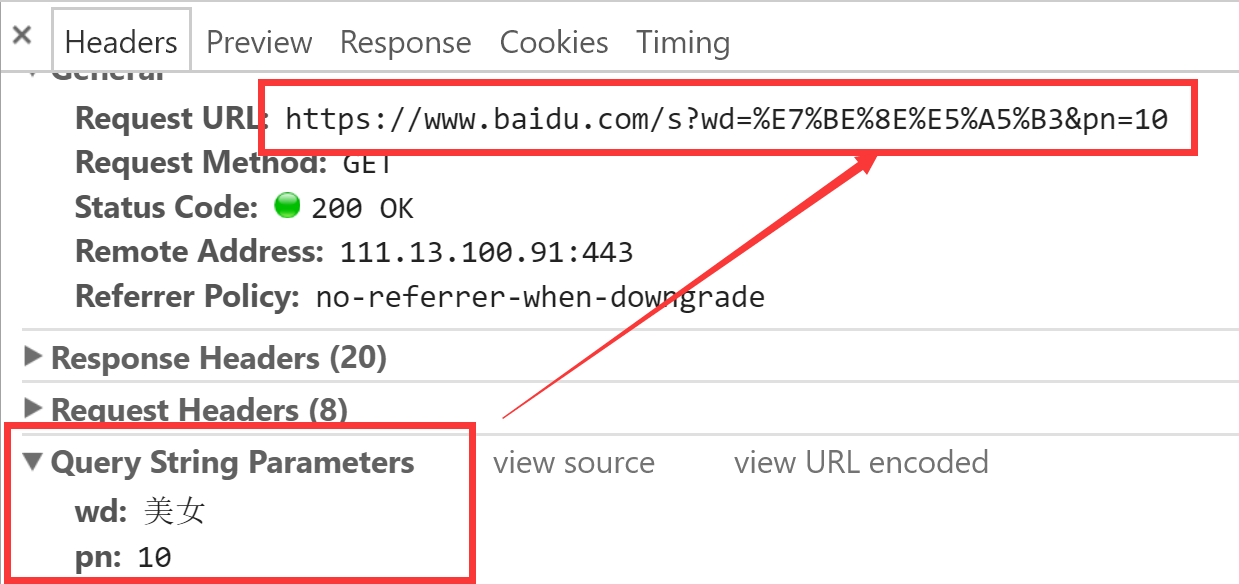
通常在Query String Parameters里面的参数都是需要跟在url地址栏中的,这就是为什么我们刚才在浏览器中看到如下的地址:
https://www.baidu.com/s?wd=%E7%BE%8E%E5%A5%B3&pn=10;pn=10表示我们向后翻到了第2页,针对这种情况,我们直接使用
params参数,代码如下:
import requests
url = 'https://www.baidu.com/s?'
response = requests.get(url, params={
'wd': '美女',
'pn': '10'
}, headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36'
})
print(response.text)
# 在这里将网页的源代码写入到文件中即可,然后我们打开test.html,结果证明与我们上面的截图是类似的
with open("test.html", "w", encoding="utf-8") as file_obj:
file_obj.write(response.text)
3、带参数的GET请求->headers # 注意清楚掉Chrom浏览器的cookie:Ctrl+Shift+Delete 快捷键
#通常我们在发送请求时都需要带上请求头,请求头是将自身伪装成浏览器的关键,常见的有用的请求头如下:
以下参数在Request Headers中:
Host
Referer #大型网站通常都会根据该参数判断请求的来源,主要是为了防止盗链
该参数表示你访问我这个网站,那你是从哪个链接跳转过来的,一般通过该参数防止盗链接
User-Agent #客户端,上面已经说过
Cookie #Cookie信息虽然包含在请求头里,但requests模块有单独的参数来处理他,headers={}内就不要放它了
代码示例如下:
#添加headers(服务器会识别请求头,不加可能会被拒绝访问,比如访问https://www.zhihu.com/explore)
import requests
response=requests.get('https://www.zhihu.com/explore')
response.status_code #500
#自己定制headers
headers={
'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36',
}
respone=requests.get('https://www.zhihu.com/explore',
headers=headers)
print(respone.status_code) #200
4、带参数的GET请求->cookies
我们以Github为例进行说明,输入正确的用户名和密码后,会跳转到github的首页,我们查看github.com的network选项,发现cookie中存在一个user_session,那么之后再进入github进行其他的操作就不用输入用户名和密码了。这里登入后,我们来查看笔者主页下面的star项目,然后判断知道创宇的爬虫题目在不在里面,只要能够正常拿到登入的cookie,那么我们就可以使用requests模块进行请求了,来看看如下的代码:
reponse = requests.get('https://github.com/scalershare?tab=stars',
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36',
},
cookies={
'user_session': 'Ep7pf6npoofRzwWjUIFt7u8plrmYjFVPoOVy0-j8e9KtkvCM'
}
)
print('知道创宇爬虫题目 持续更新版本' in reponse.text) # 打印结果为True
表示我们直接拿到了正确登入的cookie,从而可以直接访问笔者的star项目
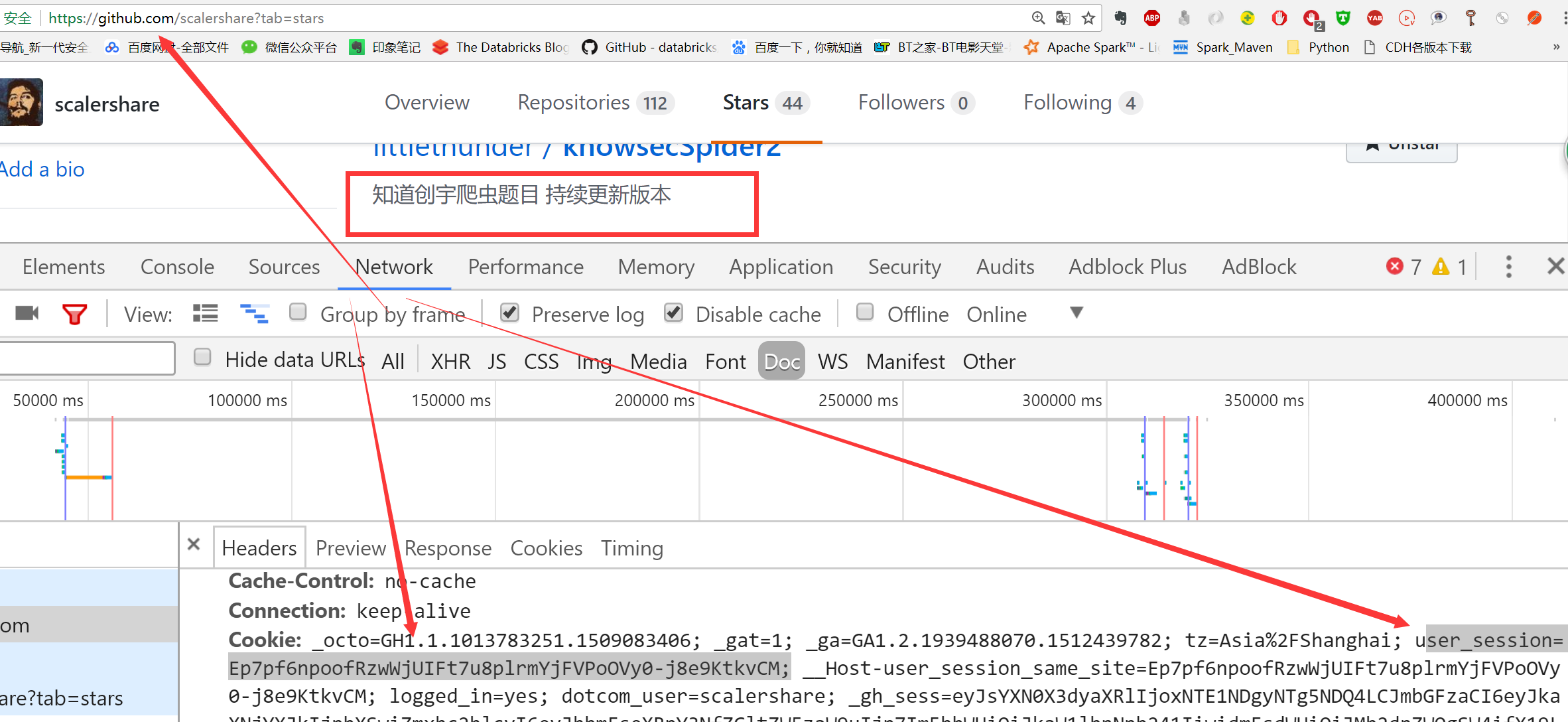
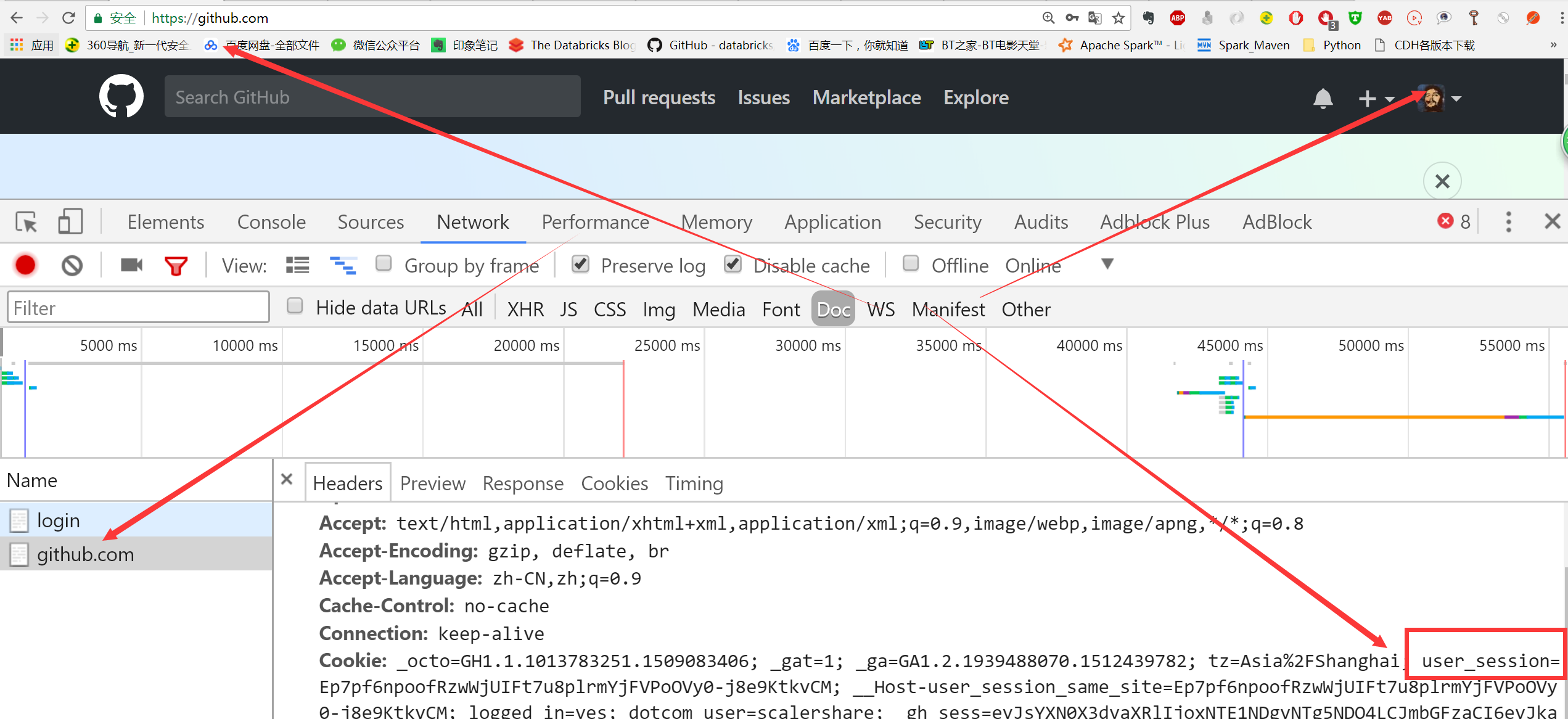
那我们能不能借助于requests模块实现自动登入呢?这就需要使用到requests模块的post方法了。
三.post请求
1.我们首先来看看get请求与post请求的区别:
#GET请求
HTTP默认的请求方法就是GET
* 没有请求体
* 数据必须在1K之内!
* GET请求数据会暴露在浏览器的地址栏中
GET请求常用的操作:
1. 在浏览器的地址栏中直接给出URL,那么就一定是GET请求
2. 点击页面上的超链接也一定是GET请求
3. 提交表单时,表单默认使用GET请求,但可以设置为POST
#POST请求
(1). 数据不会出现在地址栏中
(2). 数据的大小没有上限
(3). 有请求体
(4). 请求体中如果存在中文,会使用URL编码!
#!!!requests.post()用法与requests.get()完全一致,特殊的是requests.post()有一个data参数,用来存放请求体数据
2、发送post请求,模拟浏览器的登录行为
这里有一个非常重要的思路:对于模拟登入请求,我们采取的策略是先输入错误的信息,观察浏览器的包的具体情况,如果输对了正确的用户名和密码,那就无法分析包了,因为页面就直接跳转了。
在上一步的基础上,我们首先退出github,同时清除掉Chrome浏览器的缓存,然后来一步步分析具体的登入流程:
一 目标站点分析
浏览器输入https://github.com/login
然后输入错误的账号密码,抓包
发现登录行为是post提交到:https://github.com/session,如下图所示:
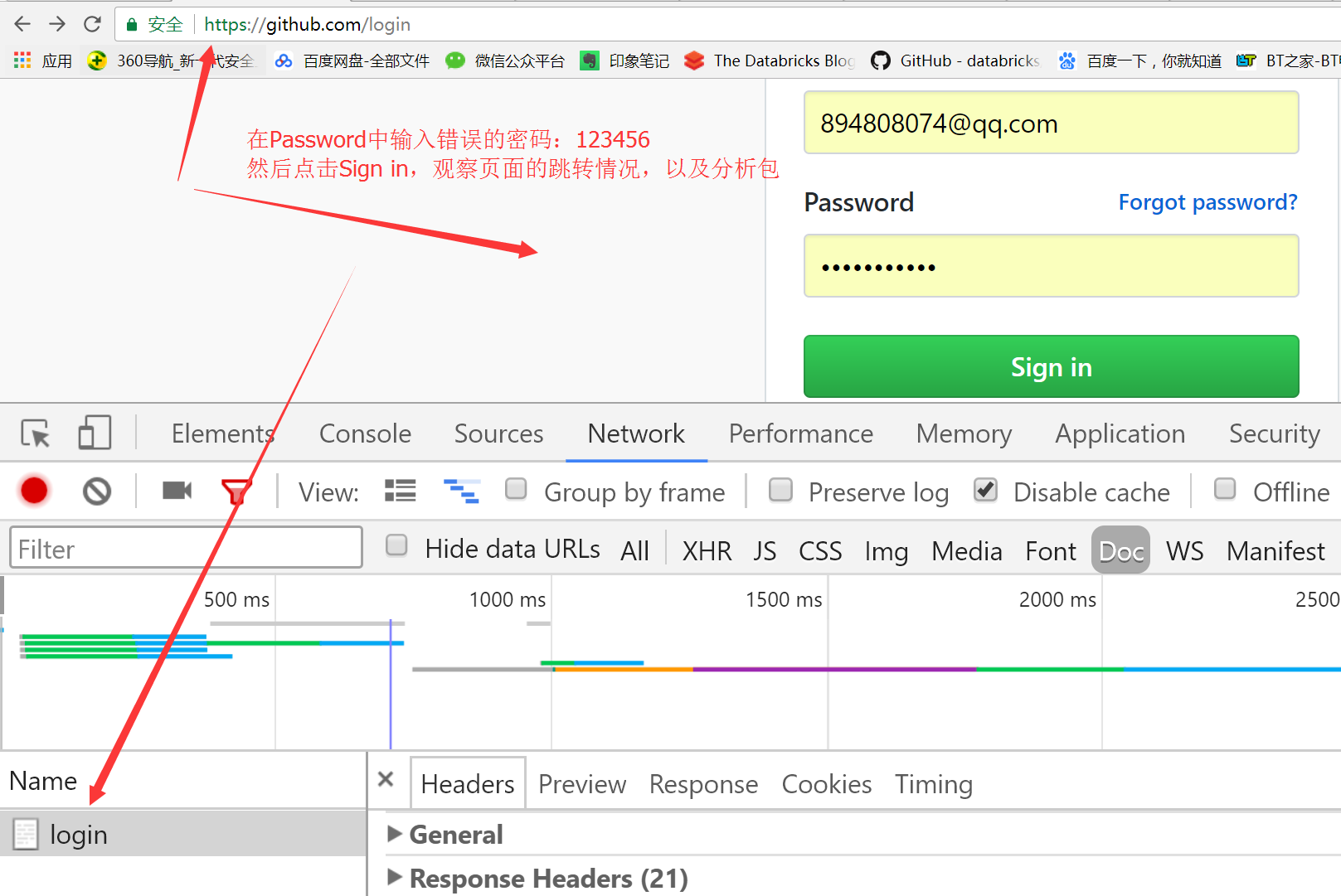
当输入错误的密码后,发现页面跳转到了session,请求头中而且带有cookie;并且抓包分析出有formdata,这是我们在form表单中输入的数据,如下:
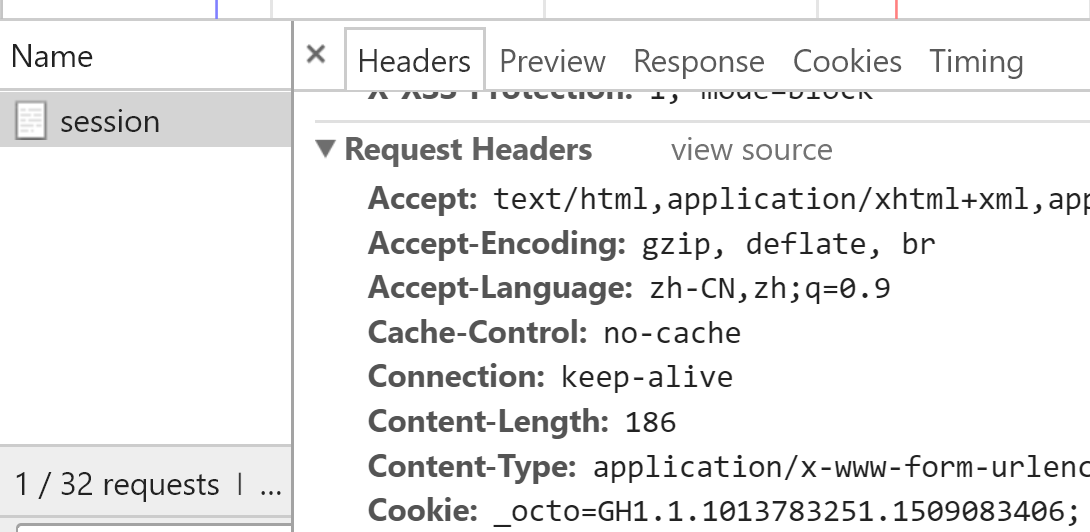
Formdata中的数据如下:
commit:Sign in
utf8:✓
authenticity_token:Oiw0M00t+MhRG6ICWsQlDB8bjjqGq04zrOcXTmvSR2lHwmw+mf9yVshF4OIYh0SZJOa4u7CR6q0tc9bjEDqvhw==
login:894808074@qq.com
password:123456
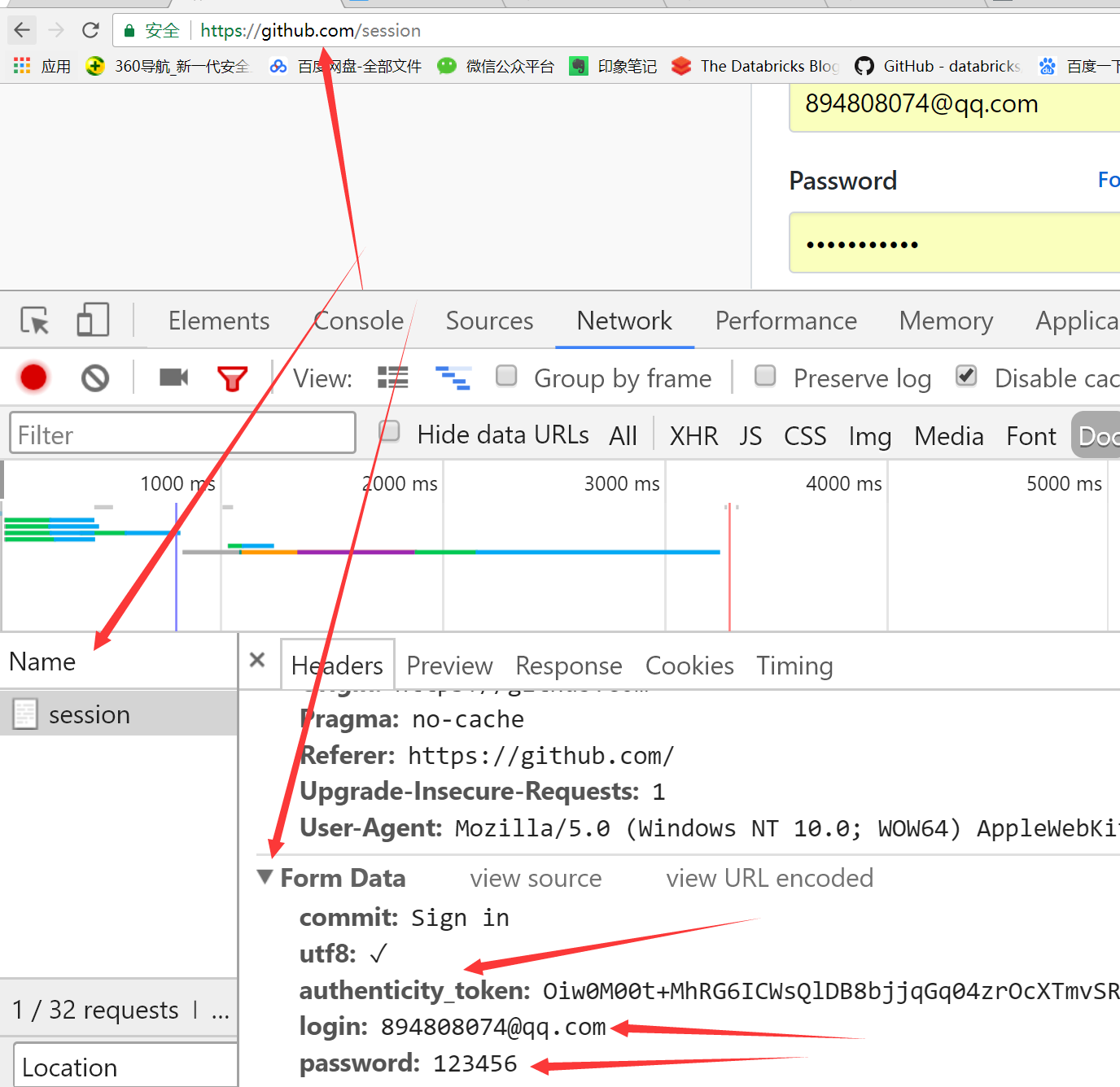
二 根据上面的流程,我们可以做出如下的分析:
先GET:https://github.com/login拿到初始cookie与authenticity_token;这是我们的猜测,我们可以去login网页中搜寻下authenticity_token,看这个参数是否是服务器中给我们的,如下图所示:
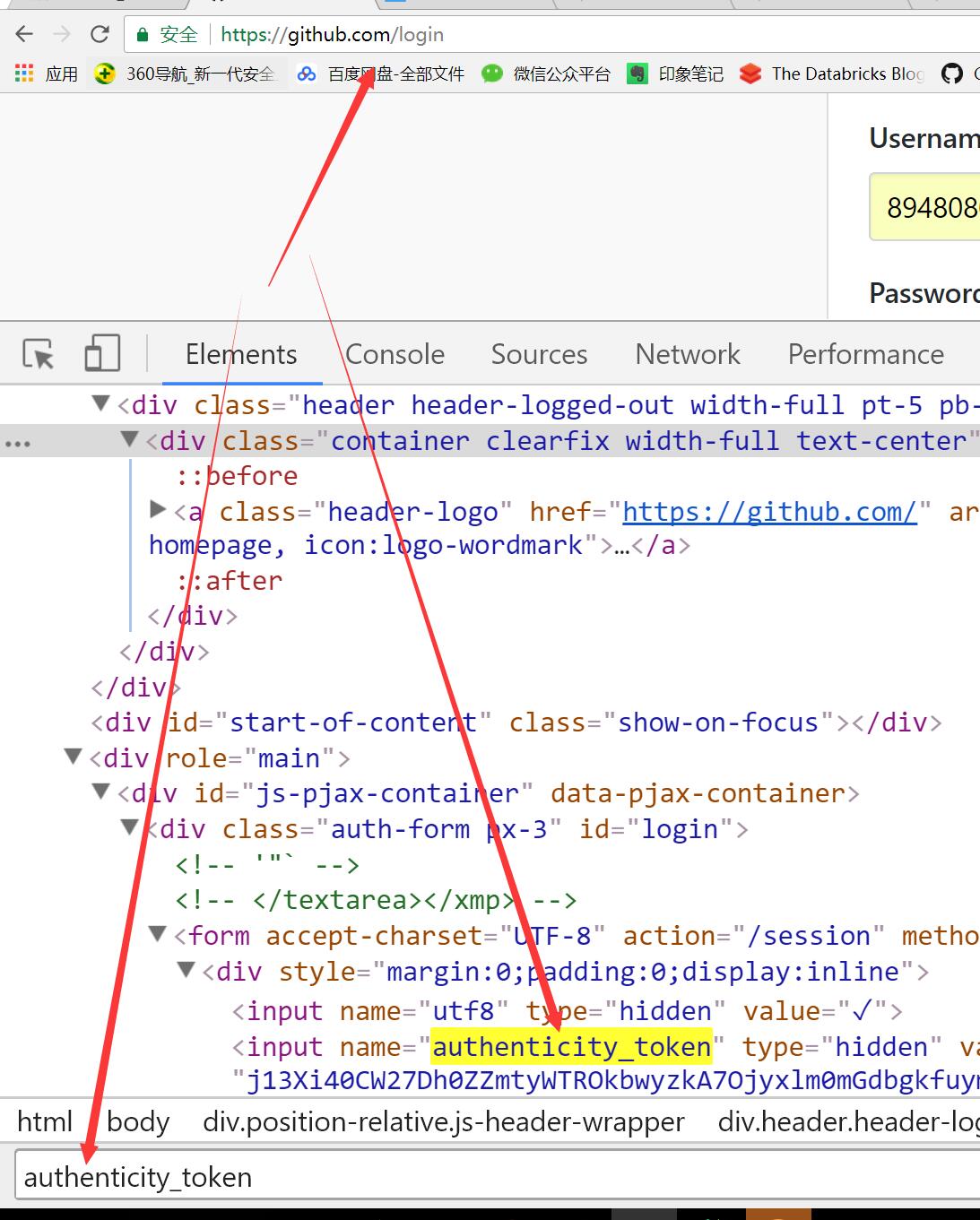
因此这里的authenticity_token就类似于我们Django中的csrf——token一样的作用,在客户端第一次访问登入页面时,服务器会返回给客户端浏览器;然后之后客户端再输入正确的用户名和密码,并且带上服务端返回给我们的authenticity_token参数一起发送给服务端。
然后正常情况下,我们应该输入正确的用户名和密码,但是为了分析具体的页面走向,所以在这里我们故意输错密码,看页面具体往哪走,当输入错误密码后,返回POST:https://github.com/session;因此我们可以分析出来,当我们正确输入密码后,post提交数据的地址就是:https://github.com/session。
第三步:我们输入正确的用户名和密码,然后点击登入,实际上,最终服务器判断时,会将先前的初始cookie,authenticity_token,用户名,密码等一起进行判断,只有都满足条件
才会跳转到笔者github的首页,于是乎我们就可以拿到登入的cookie了,如下所示:
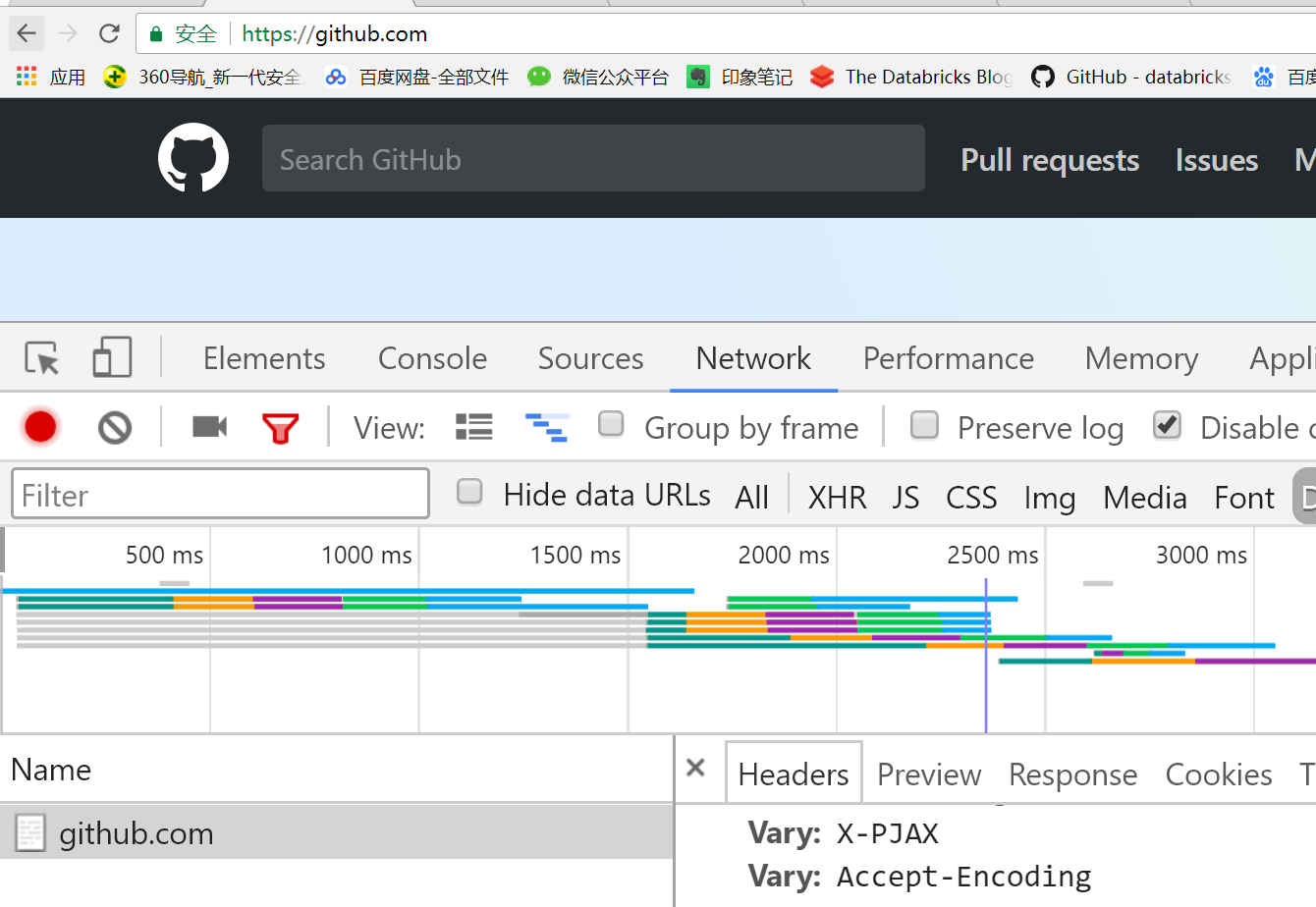
注意:很多人在分析登入流程时,都喜欢输入正确的用户名和密码,然后分析网站的登入流程,实际上这种方法比较笨拙,一旦输入正确,页面就跳转了,我们无法观察。
另外我们观察到当输入错误的密码后,页面除了跳转到session,而且请求头中出现了Refer参数,所以我们伪造时也要加上:
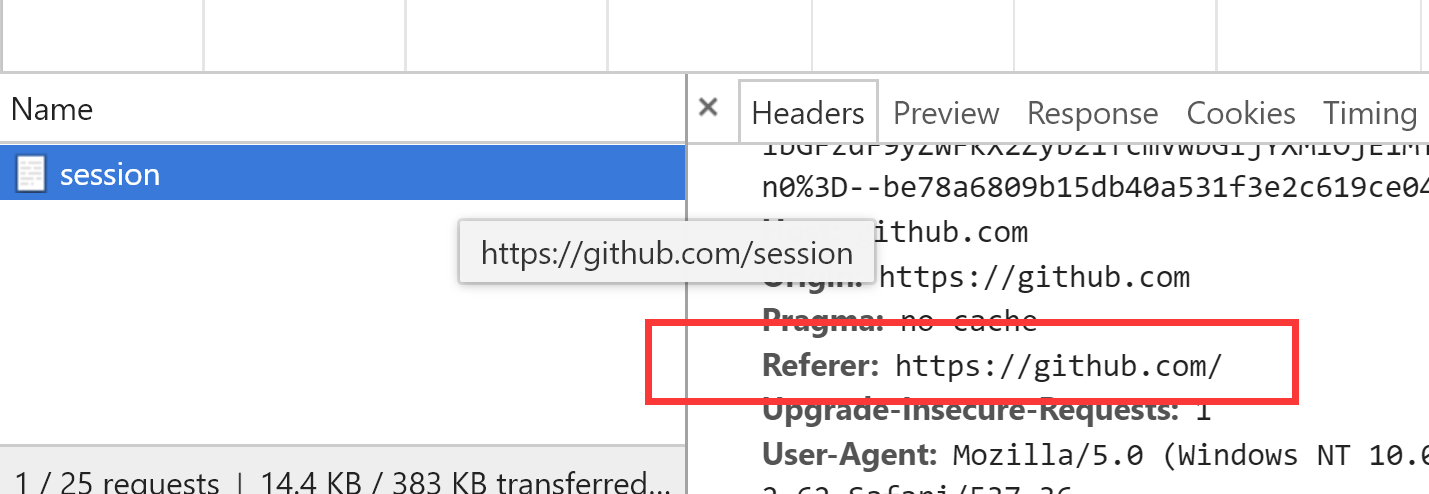
根据上面的分析,我们通过requests模块来实现自动登入:
import requests
import re
# 第一步:向https://github.com/login发送GET请求,拿到未授权的cookie,拿到服务器返回的authenticity_token
response = requests.get('https://github.com/login',
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36',
},
)
print(response.cookies)
cookies = response.cookies.get_dict() # 将cookie转换为字典
print(cookies)
authenticity_token = re.findall('name="authenticity_token".*?value="(.*?)"', response.text, re.S)[0]
print(authenticity_token)
# 第二步:带着未授权的cookie,authenticity_token,账号密码,向https://github.com/session发送POST请求,拿到输入正确用户名和密码后的授权的cookie
response = requests.post('https://github.com/session',
cookies=cookies,
headers={
'Referer': 'https://github.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36',
},
# 注意Form表单中的数据,我们通过requests模块中的data参数来封装
data={
'commit': 'Sign in',
'utf8': '✓',
'authenticity_token': authenticity_token,
'login': '894808074@qq.com',
'password': 'xxxxxxx' # 输入你正确的github账号和密码
},
# allow_redirects=False
)
# 因为cookies是浏览器返回给客户端的,所以我们可以从Http响应中拿到正确的cookie,
# 当我们输入完正确的账号和密码后,服务端会生成一个cookie给我们,并将cookie绑定在response响应中返回给我们,
# 所以我们可以使用response.cookies拿到服务端返回给我们的cookie
login_cookies = response.cookies.get_dict()
# print(response.status_code)
# # print('Location' in response.headers)
# # print(response.text)
# print(response.history)
# 第三步:带着cookie访问
reponse = requests.get('https://github.com/scalershare?tab=stars',
cookies=login_cookies,
headers={
'Referer': 'https://github.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36',
},
)
print('知道创宇爬虫题目 持续更新版本' in reponse.text)
打印结果如下:
print(response.cookies)打印结果:
<RequestsCookieJar[<Cookie logged_in=no for .github.com/>, <Cookie _gh_sess=eyJzZXNzaW9uX2lkIjoiOGU4YmM3NzFmZTI4ZmUyZjRlMDNlZTM1ZjE5ODdkZmQiLCJsYXN0X3JlYWRfZnJvbV9yZXBsaWNhcyI6MTUxNTQ4NjU3NTczNiwiX2NzcmZfdG9rZW4iOiJzem90U3hyNUpOUnJxcDdrWWJpRGcwWGtTTmtBQ0xUN1RMUTg4UkkyQy84PSIsImZsYXNoIjp7ImRpc2NhcmQiOltdLCJmbGFzaGVzIjp7ImFuYWx5dGljc19sb2NhdGlvbl9xdWVyeV9zdHJpcCI6InRydWUifX19--bccd9d2bde98b098f853735b0f2d47115c9d9f94 for github.com/>]>
print(cookies)打印结果:
{'_gh_sess': 'eyJzZXNzaW9uX2lkIjoiOGU4YmM3NzFmZTI4ZmUyZjRlMDNlZTM1ZjE5ODdkZmQiLCJsYXN0X3JlYWRfZnJvbV9yZXBsaWNhcyI6MTUxNTQ4NjU3NTczNiwiX2NzcmZfdG9rZW4iOiJzem90U3hyNUpOUnJxcDdrWWJpRGcwWGtTTmtBQ0xUN1RMUTg4UkkyQy84PSIsImZsYXNoIjp7ImRpc2NhcmQiOltdLCJmbGFzaGVzIjp7ImFuYWx5dGljc19sb2NhdGlvbl9xdWVyeV9zdHJpcCI6InRydWUifX19--bccd9d2bde98b098f853735b0f2d47115c9d9f94', 'logged_in': 'no'}
False
print(authenticity_token)打印结果
QIYMXDRZNFNke3UkzLbKU79zR6B0GvZ6x+SkYKTVYWjKRxM/61wdH2coc1KPpvy43wAfNC39CpDdjnG7V7A08Q==
根据上面的分析流程,我们来总结下整个Github的自动登入流程如下:
1.浏览器中输入github的登入地址:https://github.com/login,向该地址发送一个GET请求,
之所以要发送Get请求,是因为我们观察分析包的时候发现,第一次Request Headers中并没有cookie值;
但是第二次当我们点击登入时候,发现Request Headers中居然有一个cookie值,既然我们都没有登入,居然有cookie
我们就只能猜测这是服务器在我们第一次访问https://github.com/login时,随机发送给我们的;
我们可以认为这是一个未授权的cookie,因为我们还没有登入,但是我们必须要拿到,下次我们向服务端
请求登入时,会带着这个未经授权的cookie,这就是为什么要在第一步向https://github.com/login发送get请求的地址
2.为了分析包的具体情况,我们首先错误的密码,观察浏览器中网址的跳转:https://github.com/session
接着分析Request Headers中我们重点关注的三个参数:cookie,UA,Refer发现存在UA和Refer,因此得出结论
我们在向https://github.com/session发送Post请求时,需要构造UA和Refer;同时发现观察到了
form表单中的数据:Form Data,而且Form Data中多了一个authenticity_token的参数;因此猜想
该参数应该是我们第一次向登入界面发送请求时,服务端发送给我们的,所以我们去login网页中搜寻authenticity_token参数,
果然发现存在该参数,因此我们也需要将该参数封装到data参数中
3.经过第二步,我们再输入正确的密码,然后点击登入即可跳转到笔者的Github首页,为了验证我们是否成功登入,所以我们让requests去请求
https://github.com/scalershare?tab=stars地址,最终证明可以成功访问
注意在做这个登入的实验时,一定要彻底清除掉cookie,要不然我们是无法实际看到Request Headers中的参数的,可以发现第一次访问login时,Request Headers中根本没有cookie,但是第二次我们还没有登入成功,它里面居然有cookie,所以我们才会认为这个cookie是服务端第一次发送给我们的。
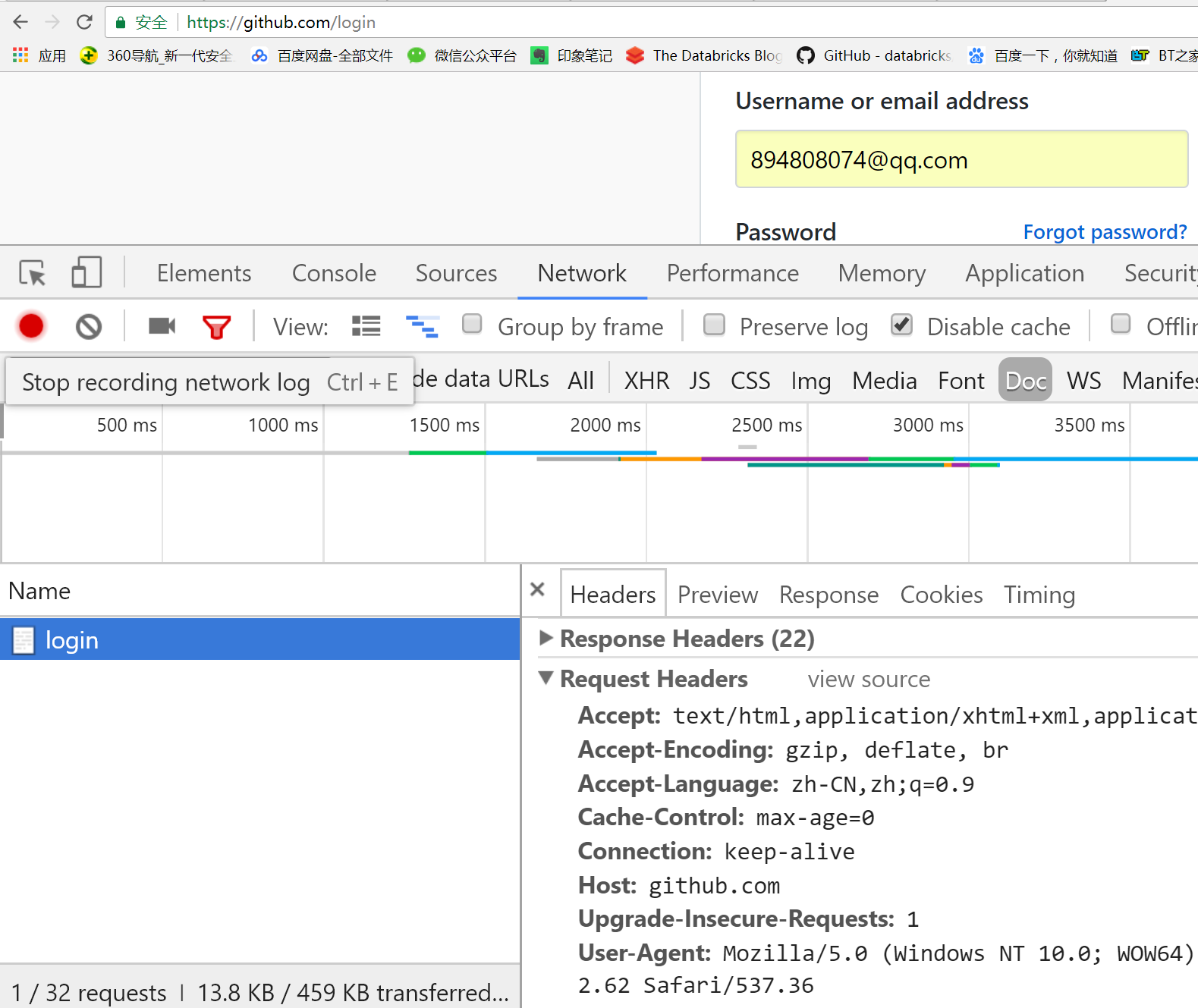
上面我们仔细分析了Github的自动登入流程,主要是怎么拿到cookie,其实requests已经帮我们封装好了,我们接着来看requests模块是怎么帮我们封装的:
# requests帮我们处理cookies与session
import requests
import re
session = requests.session()
# 第一步:向 https://github.com/login发送GET请求,拿到未授权的cookie,拿到authenticity_token
r1 = session.get('https://github.com/login',
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36',
},
)
authenticity_token = re.findall('name="authenticity_token".*?value="(.*?)"', r1.text, re.S)[0]
# 第二步:带着未授权的cookie,authenticity_token,账号密码,向https://github.com/session发送POST请求,拿到授权的cookie
r2 = session.post('https://github.com/session',
headers={
'Referer': 'https://github.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36',
},
data={
'commit': 'Sign in',
'utf8': '✓',
'authenticity_token': authenticity_token,
'login': '894808074@qq.com',
'password': 'xxxxxxxxxx'
},
allow_redirects=False
)
# 第三步:带着cookie访问
r3 = session.get('https://github.com/settings/emails',
headers={
'Referer': 'https://github.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36',
},
)
print('知道创宇爬虫题目 持续更新版本' in r3.text)
三.Requests中的编码问题
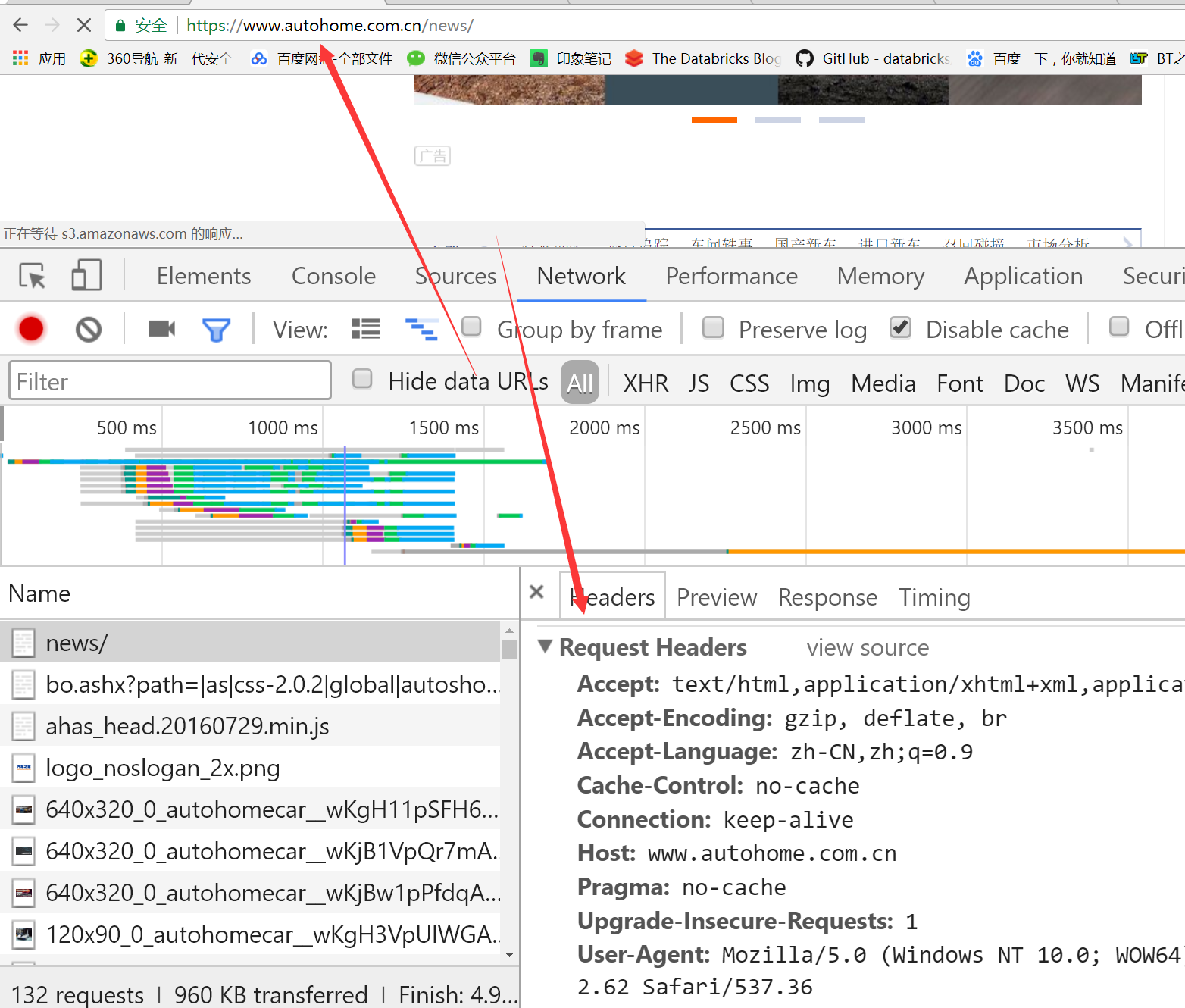
import requests
response = requests.get('http://www.autohome.com/news')
with open("autohome.html", 'w') as file_obj:
file_obj.write(response.text)
# 如果直接爬取汽车之家,会报错
那是因为汽车之家网站返回的页面内容为gb2312编码的,而requests的默认编码为ISO-8859-1,如果不设置成gbk则中文乱码
UnicodeEncodeError: 'gbk' codec can't encode character 'xa1' in position 76: illegal multibyte sequence
因此我们设置爬取下来的response对象的编码类型为gbk
import requests
response = requests.get('http://www.autohome.com/news')
response.encoding='gbk'
# print(response.text)
with open("autohome.html", 'w') as file_obj:
file_obj.write(response.text)
然后打开autohome.html即可正常访问汽车之家的信息!
四. requests中的二进制数据获取
前面笔者提到过如果需要获取图片,视频,音频等二进制文件我们可以使用response.content来获取,但是如果视频比较大,例如10G,用response.content然后一下子写到文件中是不合理的,所以我们在这里需要借助于一个参数:stream;看如下的例子:
import requests
response = requests.get(
'https://gss3.baidu.com/6LZ0ej3k1Qd3ote6lo7D0j9wehsv/tieba-smallvideo-transcode/1767502_56ec685f9c7ec542eeaf6eac93a65dc7_6fe25cd1347c_3.mp4',
stream=True)
with open(r'D:/b.mp4', 'wb') as f:
for line in response.iter_content(): # 这里主要借助于iter_content方法,配合stream参数使用
f.write(line)
五.Requests中解析JSON
先来看如下的例子:
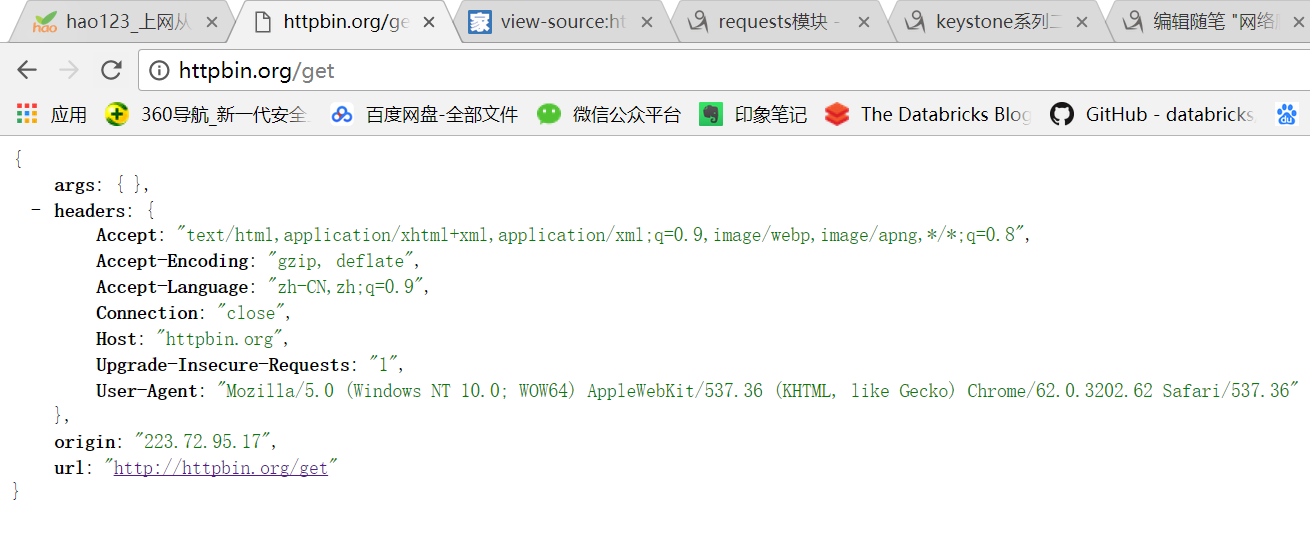
import requests
response = requests.get('http://httpbin.org/get')
print(response.text)
打印结果如下,可以看到其是json格式的字符串
{
"args": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Connection": "close",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.18.4"
},
"origin": "223.72.95.17",
"url": "http://httpbin.org/get"
}
如果我们想要使用,必须要使用json来反序列化,如下:
import requests
response = requests.get('http://httpbin.org/get')
print(response.text, type(response.text)) # json字符串
import json
#
res1 = json.loads(response.text) # 太麻烦
print(res1, type(res1)) # Python中的字典
requests为我们提供了一种更加方便的操作:
import requests
response = requests.get('http://httpbin.org/get')
import json
res1 = json.loads(response.text) # 太麻烦
res2 = response.json() # 直接获取json数据
print(res1 == res2) # True
今天暂时整理到这里,后面我们继续整理!