前言
没想到点赞这么快就到100了……
那就说到做到,说更就更!
今天就来把之前写的时候的一些坑,给大家填喽~
填坑
不知道大家有没有注意到啊,我们之前使用requests模块的时候,后面有时候跟的是get(),有时候跟的是post(),各位细心的小伙伴不会没注意到吧,不会吧不会吧,竟然没有一个人问这个问题,难道你们都懂了吗……



呐,看上面的三幅图,都是我们之前敲过的代码,聪明的你一定发现了requests.get()和requests.post()是不一样的!为什么呢?他俩长的都不一样。

今天,就让我们来说一说get和post的区别吧!
get()
子曰,学而时习之,不亦乐乎,学习使我快乐!我爱学习!谁也阻止不了我学习!我要学习!!!

刚才抒发了一下内心想学习的欲望,俗话说得好,首先要有想法,然后脚踏实地的去做,才能慢慢成功。
我真傻,真的,一开始学requests的时候,啥也没说,啪一下就拿出来了requests.get()这个东西,很快啊,那能咋整嘛,结果过了几天又给我蹦出来一个requests.post(),还跟我说年轻人你耗子尾汁,我再去看以前的东西,竟是迷糊了去,唉,如果我当初刚学的时候就好好百度一下,也不会到现在这般迷茫。

废话不多说,首先要知道一点,get()和post()都是对url发起的一种请求,那么什么时候用get()呢?这就要用到我们的抓包工具啦~相信细心的小伙伴已经发现了,

在url对应的Headers里有个GET,这就说明了这个页面是要用get方式请求的。
post()

同样,如果你发现url对应的Headers里有个POST的话,就说明我们要用post方法进行请求。
完了……
你以为到这里就结束了??
大错特错了!
之前看评论发现有些小伙伴不喜欢穿衣服就进去抢银行哈,headers都不带,保安立马把你打飞。

总结
我们之前爬那个翻译网站的时候,就用到了post(),不知道大家有没有注意,那一次我们不但发起了请求,还给服务器传递了几个参数:


之前小泽的data打错了,打成了date,就有小伙伴也跟着打错了,然后报错了,hhh
说明学好英语真的很重要!!!
大家可以看到,在post()里,我们有url=,还有headers=,还有一个data=,那么post()跟get()的区别到底在哪里呢??

直接上代码截图
通过截图大家会发现,get()里面有个params=,这就是它们的区别哦!
发给服务器的参数里面,在get()里要用params=,在post()里面要用data=,不是date!!
不知道起什么名字
你以为这就完了吗?
说实话本来是想偷懒的,但是转念一想,还是负责任一次叭,毕竟不能对大家蹭蹭进去就不管了!

相信大家安装模块的时候啊,总会遇到各种黄色的东西还有红色的东西,对我们幼小的心灵造成了极大的打击!
这里教给大家一个方便快捷的方法,从此跟下得慢、总报错说拜拜!
打开我的电脑,在地址栏中输入 %APPDATA% 按回车跳转到目标目录。在目录下创建一个pip文件夹,在里面创建一个pip.txt文件,然后把扩展名改成ini。


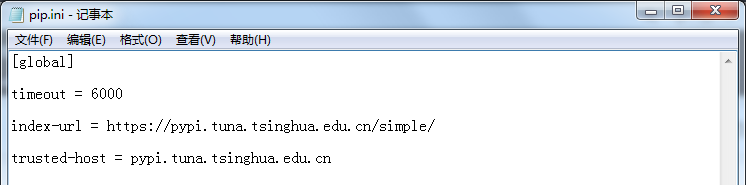
在里面输入呢,如下的东西啊:
[global]
timeout = 6000
index-url = https://pypi.tuna.tsinghua.edu.cn/simple/
trusted-host = pypi.tuna.tsinghua.edu.cn
从此以后下片 下模块就快的飞起啦!芜湖~
干
说干就干,水是不可能水的,看到这里的老铁还不感动的泪流满面然后给个赞吗!!为什么粉丝数量可以比赞的数量多!!小泽想要赞,呜呜……
干什么
打开它!
还记得我们学爬虫是为了什么吗?
爬 取 数 据 !
如果我们连高分的动作片都不能爬取到,那我们学爬虫还有什么意义。
所以今天的任务目标:爬取豆瓣电影中动作电影的排行。
怎么干
又到了紧张刺激的分析环节啦~
首先打开豆瓣电影主页:

去找右边的更多榜单

在弹出的页面里找到动作这两个字,没有岛国!

好的,跳到了这里。
开 始 分 析 !

大家试着往下拉,会不会发现一直拉不到最下面?
也就是说,这些数据是阿贾克斯!
不要问我阿贾克斯是什么…lol玩过没,武器大师啊!!
我们理想中的应该是把每一部电影的电影名字和相关主演还有地区,标签那些爬下来对吧,那我们先试着只爬一个!
按照之前学过的思路来:

用我们的金手指点一下第一个页面,然后我们就会发现我们要的东西都在这里面,接下来的操作,如果看不懂的话,就罚你回去看我之前写的内容一百遍哦,oh不对,这怎么能是惩罚呢~ 简直是美妙的福音!
# 导入模块
import requests
from lxml import etree
# get请求的url
get_url = 'https://movie.douban.com/typerank?type_name=%E5%8A%A8%E4%BD%9C&type=5&interval_id=100:90&action='
# 伪装头,穿衣服!谁不穿拉出去毙了!
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
# 发起get请求,把返回的数据text化存到response里
response = requests.get(url=get_url,headers=header).text
# 树化返回的网页数据
tree = etree.HTML(response)
movie_name = tree.xpath('//div[@id="content"]//span[@class="movie-name-text"]/a/text()')
print(movie_name)
如果根据之前学的,上面的代码应该是可以成功打印出第一部电影的名字的。
但是运行之后…

xpath表达式是没有错的,那说明了什么:
说明了这个数据,是不存在的!
你看到的,不一定是你看到的,也许你没看到的,才是你看到的!!

还记得之前说的阿贾克斯不,既然我们已经发现这个网站是动态的网站了,那就要用抓包工具去捕获信息对吧!
其实仔细一想,这么大的一个电影网站肯定不会直接把电影数据写在网页上让我们爬下来啊,就像我们看游戏的那些排名,都是动态从数据库里加载出来的,对吧!
所以这些电影排名如果是死的话,那程序员每过一段时间都要重新改一改排行,该多难受啊……
思路明确,我们打开抓包工具,去找一下服务器返回的数据在哪里!

记得刷新一下页面哦~
看到了嘛,XHR里面就可以找到我说的那个阿贾克斯请求!
不过有四个诶…
一一打开看一下好了:



最后一个跟第一个是一样的哦,通过抓包工具可以看到,这几个阿贾克斯请求都给服务器传递了有参数对吧。
接着我们再看response:


粗略的翻看一下,发现第三个里面包含了我们要的所有信息,对吧!
再把它给服务器传递的参数单独拿出来看一看:
params = {
'type':'5', # 很明显是分类
'interval_id':'100:90', # 还记得开头的好于100%-90%的动作片吗
'action':'',
'start': '0', #从第几个开始
'limit':'20' #每次读取多少个
}
那么如果改了type传递的参数,是不是就可以拿到不同分类的数据呢?是的!
那么如果改了start传递的参数,是不是就可以拿到不同开头的数据呢?是的!
那么如果改了limit传递的参数,是不是就可以拿到不同数量的数据呢?是的!
这可比我们之前的笨方法快多了!

还有一个点要注意,那就是服务器那边发来的是什么样的数据!
还记得之前我们用过json编码解析翻译网站吗,今天又要用到啦,看上图,返回的文件是json格式的吧,那我们就需要用json去解析,对吧!
接下来,让我们找到正确的url吧!

观察这行url,看到里面有type=,action=之类的,像不像我们之前找到的参数呢?没错,就是这样的,既然这样,我们是可以传递参数的,那是不是就是说可以在这串url上简化一下,把https://movie.douban.com/j/chart/top_list?后面的东西都给删掉呢?当然是可以的!
万事开头难,要学会接受。
# 导入模块
import json
import requests
get_url = 'https://movie.douban.com/j/chart/top_list?'
params = {
'type':'5',
'interval_id':'100:90',
'action':'',
'start': '0', #从第几个开始
'limit':'20' #每次读取多少个
}
# 穿衣服!
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
那么,上面的代码就是我们要提前准备好的东西了吧,然后……开干!
response = requests.get(url=get_url,params=params,headers=header).content.decode()
a = json.loads(response)
print(a)
这一类操作呢,之前在爬取翻译网站的时候也做过,所以不多解释,如果有人不会的话就留言哦,不要光关注不点赞!!!!!

求求各位关注的帅哥美女们每一篇都给来个赞吧T-T

回到主题,运行一下我们会发现:

果然被我们拦截到了!
看一下列表:

我们要的评分,是在列表里的字典里的’rating’键对应的值对吧,以此类推,我们来把得到的数据提取一下:
# 遍历a列表中的每一个字典
for i in a:
pingfen = i['rating'][0]
paiming = i['rank']
is_playable = i['is_playable']
fenlei = i['types']
fenleis = ''
for a in fenlei:
fenleis += a
fenleis += ' '
diqu = i['regions'][0]
mingzi = i['title']
riqi = i['release_date']
zhuyan = i['actors']
zhuyans = ''
for b in zhuyan:
zhuyans += b
zhuyans +=' '
if is_playable == True:
zhuangtai = '可播放'
dizhi = i['url']
print('电影名字:'+mingzi)
print('排名:',paiming)
print('状态::' + zhuangtai)
print('链接:' + dizhi)
print('评分:' + pingfen)
print('主演:' + zhuyans)
print('上映日期:' + riqi + '/上映地区:' + diqu +'/分类:' + fenleis)
print('-------------------------------------------------------------------')
else:
zhuangtai = '不可播放'
print('电影名字:' + mingzi)
print('排名:',paiming)
print('状态::' + zhuangtai)
print('评分:' + pingfen)
print('主演:' + zhuyans)
print('上映日期:' + riqi + '/上映地区:' + diqu + '/分类:' + fenleis)
print('-------------------------------------------------------------------')
上述操作呢,都属于基础哈,如果不懂的话留言问~

这就是效果图喽!
呼呼,好累鸭。
看到这里了你还不给个赞嘛~~
下一期200赞再更新哦!!
200赞!!

各位姥爷们早点睡觉哦,今天就搞到这里了,顶不住了……
200赞!!!!!!
