ACID理论
原⼦性(Atomicity)
⼀致性(Consistency)
隔离性(Isolation)
持久性(Durability)
CAP理论
(1) ⼀致性Consistency
“all nodes see the same data at the same time”
⼀旦数据更新完成并成功返回客户端后,那么分布式系统中所有节点在同⼀时间的数据完全⼀致。
特点
1. 由于存在数据同步的过程,写操作的响应会有⼀定的延迟。
2. 为了保证数据⼀致性会对资源暂时锁定,待数据同步完成释放锁定资源。
3. 如果请求数据同步失败的结点则会返回错误信息,⼀定不会返回旧数据。
(2) 可⽤性(Availability)
“Reads and writes always succeed”
服务⼀直可⽤,⽽且是正常响应时间。

特点 所有请求都有响应,且不会出现响应超时或响应错误
(3) 分区容错性(Partition tolerance)
“the system continues to operate despite arbitrary message loss or failure of part of the system”
分布式系统中,尽管部分节点出现任何消息丢失或者故障,系统应继续运⾏。
通常分布式系统的各各结点部署在不同的⼦⽹,这就是⽹络分区,不可避免的会出 现由于⽹络问题⽽导致结点之间通信失败,此时仍可对外提供服务。
特点 分区容忍性分是布式系统具备的基本能⼒。
CAP的3选2的特性
CA 放弃 P:如果不要求P(不允许分区),则C(强⼀致性)和A(可⽤性)是可以保证的。这样 分区将永远不会存在,因此CA的系统更多的是允许分区后各⼦系统依然保持CA。
CP 放弃 A:如果不要求A(可⽤),相当于每个请求都需要在Server之间强⼀致,⽽P(分区)会导 致同步时间⽆限延⻓,如此CP也是可以保证的。很多传统的数据库分布式事务都属于这种模式。
场景: 跨⾏转账,⼀次转账请求要等待 双⽅银⾏系统都完成整个事务才 算完成。
AP 放弃 C:要⾼可⽤并允许分区,则需放弃⼀致性。⼀旦分区发⽣,节点之间可能会失去联系,为了 ⾼可⽤,每个节点只能⽤本地数据提供服务,⽽这样会导致全局数据的不⼀致性。现在众多的NoSQL 都属于此类。
场景1: 淘宝订单退款。今⽇退款成功, 明⽇账户到账,只要⽤户可以接 受在⼀定时间内到账即可。
场景2: 12306的买票。都是在可⽤性和 ⼀致性之间舍弃了⼀致性⽽选择 可⽤性。
分布式的BASE理论
Basically Available(基本可⽤)
对响应上时间的妥协
对功能损失的妥协
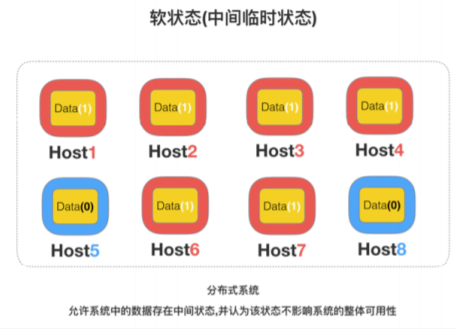
Soft state(软状态)
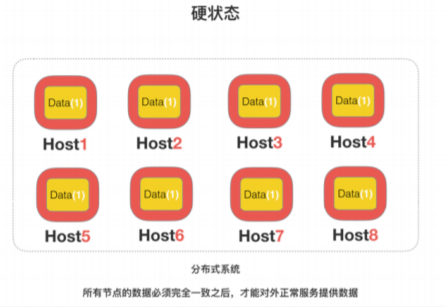
硬状态
要求多个节点的数据副本都是⼀致的,这是⼀种"硬状态"
软状态:
允许系统中的数据存在中间状态,并认为该状态不影响系统的整体 可⽤性,即允许系统在多个不同节点的数据副本存在数据延迟。
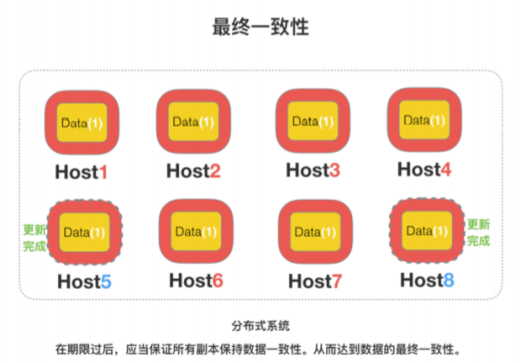
Eventually consistent(最终⼀致性)
系统能够保证在没有其他新的更新操作的情况下,数据最终⼀定能够达到⼀致 的状态,因此所有客户端对系统的数据访问最终都能够获取到最新的值
base是和ACID对⽴的:
ACID 传统数据库 追求强⼀致性模型
BASE ⼤型分布式系统 通过牺牲强⼀致性获得⾼可⽤性