Spark运行模式有Local,STANDALONE,YARN,MESOS,KUBERNETES这5种,其中最为常见的是YARN运行模式,它又可分为Client模式和Cluster模式。这里以Spark自带的SparkPi来说明这些运行模式。
本文作为第一篇,先结合SparkPi程序来说明Yarn Client方式的流程。
以下是Spark中examples下的SparkPi程序。
1 // scalastyle:off println 2 package org.apache.spark.examples 3 4 import scala.math.random 5 6 import org.apache.spark.sql.SparkSession 7 8 /** Computes an approximation to pi */ 9 object SparkPi { 10 def main(args: Array[String]) { 11 val spark = SparkSession 12 .builder 13 .appName("Spark Pi") 14 .getOrCreate() 15 val slices = if (args.length > 0) args(0).toInt else 2 16 val n = math.min(100000L * slices, Int.MaxValue).toInt // avoid overflow 17 val count = spark.sparkContext.parallelize(1 until n, slices).map { i => 18 val x = random * 2 - 1 19 val y = random * 2 - 1 20 if (x*x + y*y <= 1) 1 else 0 21 }.reduce(_ + _) 22 println(s"Pi is roughly ${4.0 * count / (n - 1)}") 23 spark.stop() 24 } 25 } 26 // scalastyle:on println
这个是Spark用于计算圆周率PI的scala程序,思想很简单,就是利用以坐标轴原点为中心画一个边长为2的正方形,原点距离正方形的上下左右边距离均为1,然后再以原点为中心画一个半径为1的圆,此时正方形的面积是4,圆的面积是PI,上面程序所做的就是在正方形里随机取若干个点(比如上面程序默认的20万),计算有多少个点落在圆形里面,那么可以认为这个等式是成立的,即:“圆面积” / “正方形面积” = “落在圆内的点数” / “正方形内的点数”,也就是,PI / 4 = count / (n-1),所以PI = 4 * count / (n-1)。
Spark程序可以分为Driver部分和Executor部分,Driver可以认为是程序的master部分,具体而言1~16行和22~25行都是Driver部分,其余的17~21行是Executor部分,即执行具体逻辑计算的部分,上面程序slices默认是2,也就是说,默认会有2个Task来执行计算。
下面来以yarn client方式来执行这个程序,注意执行程序前先要启动hdfs和yarn,最好同时启动spark的history server,这样即使在程序运行完以后也可以从Web UI中查看到程序运行情况。
输入以下命令:
[root@BruceCentOS4 spark]# $SPARK_HOME/bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client $SPARK_HOME/examples/jars/spark-examples_2.11-2.3.0.jar
以下是程序运行输出信息部分截图,
开始部分:

中间部分:
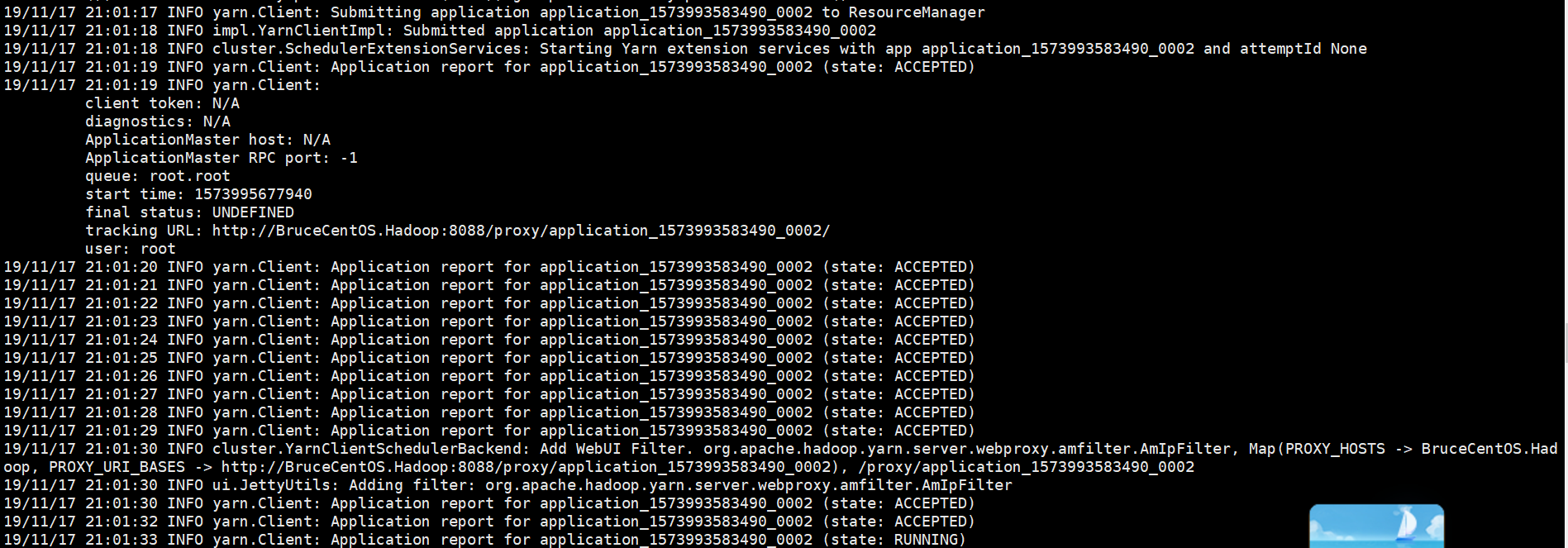
结束部分:
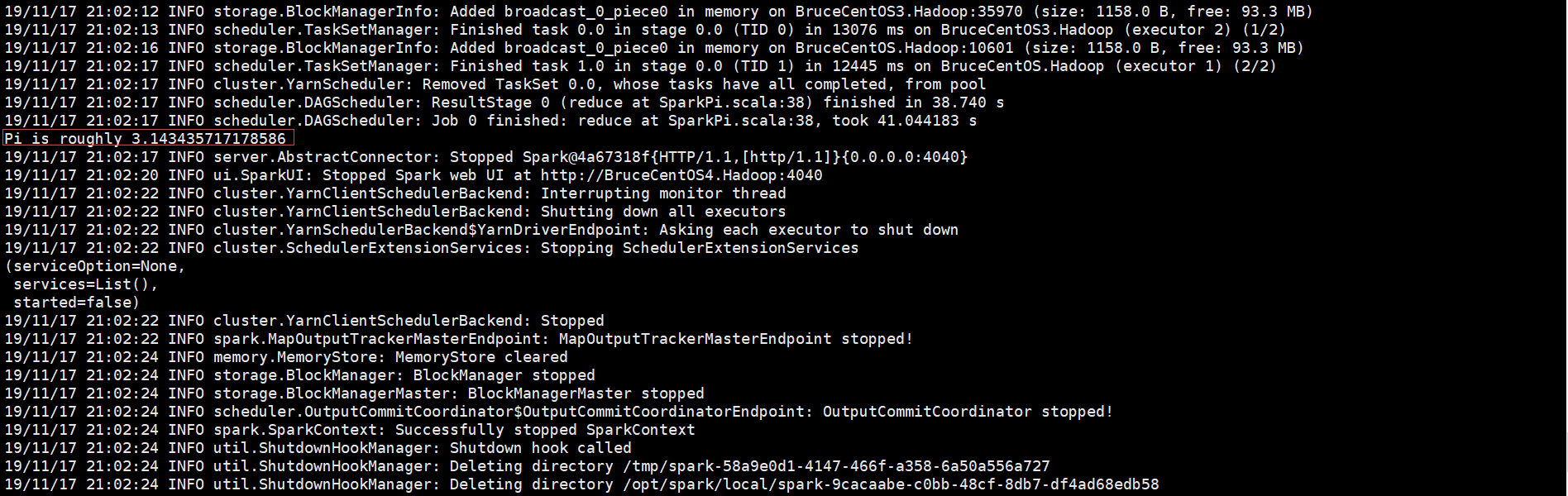
由于程序是以yarn client方式运行的,因此Driver是运行在客户端的(BruceCentOS4上的SparkSubmit进程),同时在BruceCentOS和BruceCentOS3上各运行了1个Executor进程(进程名字:CoarseGrainedExecutorBackend),另外在BruceCentOS上还有1个名字为ExecutorLauncher的进程,这个进程主要是作为Yarn程序中的ApplicationMaster,因为Driver运行在客户端,它仅仅作为ApplicationMaster为运行Executor向ResourceManager申请资源。
SparkUI上的Executor信息:

BruceCentOS4上的客户端进程(包含Spark Driver):
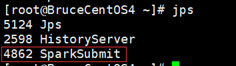
BruceCentOS上的ApplicationMaster和Executor:

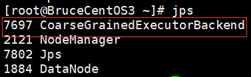
BruceCentOS3上的Executor:
下面具体描述下Spark程序在yarn client模式下运行的具体流程。
这里是一个流程图:
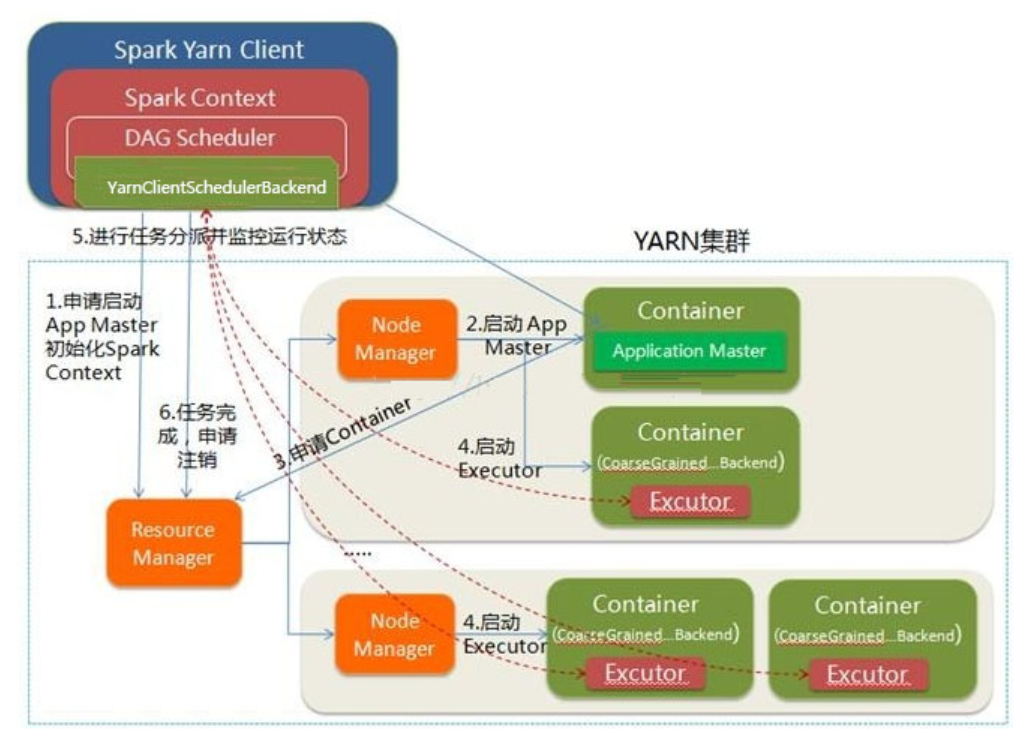
- Spark Yarn Client向YARN的ResourceManager申请启动ApplicationMaster。同时在SparkContent初始化中将创建DAGScheduler和TASKScheduler等,由于我们选择的是Yarn-Client模式,程序会选择YarnClientSchedulerBackend。
- ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,对应进程名字是ExecutorLauncher。与YARN-Cluster区别的是在该ApplicationMaster不运行SparkContext,只与SparkContext进行联系进行资源的分派。
- Client中的SparkContext初始化完毕后,与ApplicationMaster建立通讯,向ResourceManager注册,根据任务信息向ResourceManager申请资源(Container)。
- 一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,要求它在获得的Container中启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向Client中的SparkContext注册并申请Task。
- client中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向Driver汇报运行的状态和进度,以让Client随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。
- 应用程序运行完成后,Client的SparkContext向ResourceManager申请注销并关闭自己。
以上就是个人对Spark运行模式(yarn client)的一点理解,其中参考了“求知若渴 虚心若愚”博主的“Spark(一): 基本架构及原理”的部分内容(其中基于Spark2.3.0对某些细节进行了修正),在此表示感谢。