结对情况
-
自己
- 学号后三位:612
- 名:章鹏
-
**队友 **
- 学号后三位:621
- 少
- 博客链接
项目链接
设计说明
接口设计(API)
读取json文件中的学生信息,需要传递三个参数:student类指针,学生数量,部门数量
toStudent(student*, int,int)
读取json文件中的部门信息,需要传递三个参数:department类指针,学生数量,部门数量
toDepartment(department*, int, int)
将结果输出到json文件,需要传递6个参数:list
void write(list<int>* , list<int>* , student* , department* ,int, int )
内部实现设计(类图)
创建student和department类,通过read读取json数据给student对象department对象,通过matched进行匹配,通过write将结果输出为json格式。

匹配算法设计(思想/流程等)
通过权值来衡量部门和学生的之间的匹配程度,对于匹配程度高的,优先加入此部门,权值计算方法如下:
对于第x个部门,分析学生的四个方面的信息
- 分析学生部门意愿,是否包含此部门
- 分析学生兴趣标签,与部门所希望学生拥有的兴趣标签的吻合度
- 分析学生有空时间,与部门常规活动安排表的吻合度
- 分析学生绩点
对于上面四个方面设置对应的权值
- 部门意愿占7分,若学生部门意愿含有此部门则拿到此7分。
- 兴趣标签占2分,学生的兴趣标签与部门所希望学生拥有的兴趣标签的吻合度越高,拿到的分数越多(最多两分)。
- 有空时间占2分,学生的有空时间与部门常规活动安排表的吻合度越高,拿到的分数越多(最多两分)。
- 学生绩点占2份,学生的绩点越高,拿到的分数越多(最多两分)。
权值计算方法如下
权值 = 7(学生意愿此部门)+( 兴趣匹配数量 / 部门标签数量)* 2 + 时间匹配数量 / 部门活动时间数量 * 2 + (绩点 / 5 )* 2
对于每个部门,将所有学生的分数从高到低排序,其中分数小于7的(即部门意愿不包含第x个部门)的学生不作为部门挑选成员对象,由部门根据分数高低顺序挑选学生,直到挑选到的人数等于部门纳新限制人数时,结束挑选。
测试数据生成
测试时部门与学生之间的匹配算法时,需要使用大量的json格式的部门和学生的数据。
通过人工编辑这些数据不可行,需要计算机程序生成。利用rapidjson中writer接口和随机数生成函数,随机生成测试数据并以json格式保存。部分代码如下:
Value object(kObjectType);
//设置学号
object.AddMember("student_no", student_no, allocator);
//设置学生姓名
object.AddMember("student_name", Value(student_name.c_str(), document.GetAllocator()).Move(), allocator);
//设置学分
object.AddMember("score", score, allocator);
//添加兴趣
randArray(tag_count, 10, arra);//生成随机数数组
Value array4(kArrayType);
for (int i = 0; i < tag_count; i++)
{
array4.PushBack(Value(tag_hub[arra[i]].c_str(), document.GetAllocator()).Move(), allocator);//将兴趣写入json数组
}
object.AddMember("tags", array4, allocator);
上述代码为创建一个学生对象的部分代码,展示了如何将随机生成的数据添加进json对象。Value object()为创建一个json对象,Value array()创建一个json数组,object.AddMember()为对象增加成员。利用生成随机姓名字符串,赋值给“student_name"。为了避免生成的随机数的重复,生成随机数数组,利用其将兴趣字符串数组tag_hub[]中的值随机写入json数组,通过这种方法完成实验数据的随机生成。
评价自己的匹配算法
优点:
- 保证部门纳新到的学生,都是想加入此部门的(意愿表中含有此部门)。
- 采用计算每个学生四个信息与部门的要求的吻合程度,来供部门挑选,比较合理。
- 可以通过修改绩点、标签等的权值比重,来灵活挑选学生 。
缺点:
- 由于部门意愿占分数的比例大,加上部门人数有限制,会出现大量学生没有加入部门。
- 需要双重循环每个部门和每个学生,比较耗时。
代码规范要求
| 规范 | 要求 | 备注 |
|---|---|---|
| 变量、函数命名 | 使用驼峰命名法 | 如:FirstName |
| 空格、缩进使用 | 使用4个空格来缩进代码 | 不使用TAB来缩进 |
| 注释使用 | 标注函数功能,标注变量、复杂的过程 | 尽量详细 |
| 类命名 | 首字母大写 | |
| 语句规则 | 通常运算符前后加空格 | 如:i = j + k; |
| 其他 | 每行代码字符数小于80个 |
**关键代码解释 **
对于第i个部门,第j个学生,关于匹配算法四个信息与部门要求的吻合度的计算:
判断学生是否愿意加入此部门,如果愿意,权值加7,代码如下:
/*根据学生选择部门的意愿计算权值 */
for (m = 0; m < sw; m++)
{ //循环第j个学生的意愿数组
if (*(stu[j].getDep_will() + m) == dep[i].getDep_no())
{
q += 7; //计算权值(累加)
break;
}
}
计算绩点的权值,代码如下:
/*根据学生的绩点来计算权值*/
q += (stu[j].getScore() / 5.0) * 2;
通过计算学生空闲时间与部门活动时间的吻合程度计算权值,代码如下:
/*根据学生的空闲时间段和部门活动时间段来计算权值*/
//timeConvert()将用字符串表示的时间转换成用stime类表示
temp = 0;
for (m = 0; m < da; m++)
{ /*对于每个部门的时间段循环学生有空时间数组*/
for (n = 0; n < sa; n++)
{
if (stuTime[n].week != depTime[m].week) continue;
if (stuTime[n].start > depTime[m].start) continue;
if (stuTime[n].end < depTime[m].end) continue;
temp++;
break;
}
}
q += temp*1.0 / da * 2; //计算权值(累加)
通过计算学生兴趣与部门标签的吻合程度计算权值,代码如下:
/*根据学生的兴趣爱好和部门想要的兴趣tags来计算权值*/
temp = 0;
for (m = 0; m < dt; m++)
{
/*对于每个部门的兴趣要求段循环学生的兴趣*/
for (n = 0; n < st; n++)
{
if (*(stu[j].getTags() + n) != *(dep[i].getTags() + m)) continue;
temp++;
break;
}
}
q += temp*1.0 / dt * 2; //计算权值(累加)
将所有学生对某个部门按权值从大到小排序,权值小于7不加入排序,代码如下:
/*将第x个学生计算后的权值保存在stu_dep[x]中*/
stu_dep[j] = q;
/*将学生的权值进行排序,权值大的学生的下标,优先排在数组stu_dep_sort的前面*/
if (q < 7)continue; //权值小于7,无需记录此学生
stu_dep_sort[k] = j;
for (n = k - 1; n > -1; n--)
{
if (stu_dep[stu_dep_sort[n + 1]] > stu_dep[stu_dep_sort[n]])
{
temp = stu_dep_sort[n + 1];
stu_dep_sort[n + 1] = stu_dep_sort[n];
stu_dep_sort[n] = temp;
}
}
k++;
**运行及测试结果展示 **
测试200位同学,20个部门的情况
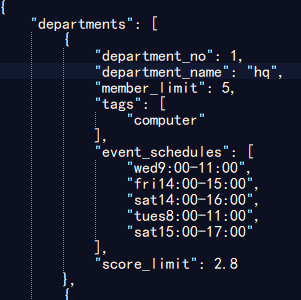
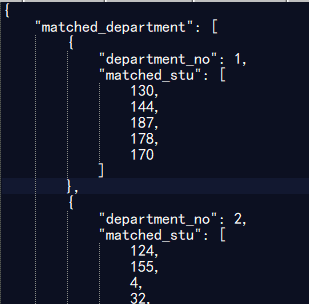
测试500位同学,30个部门的情况
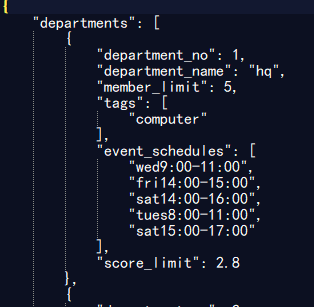
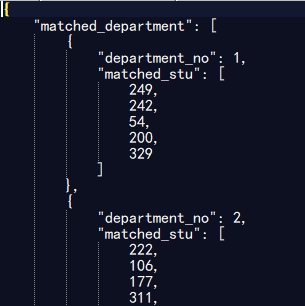
测试1000位同学,50个部门的情况
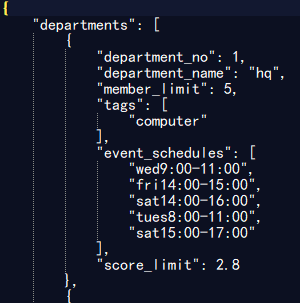
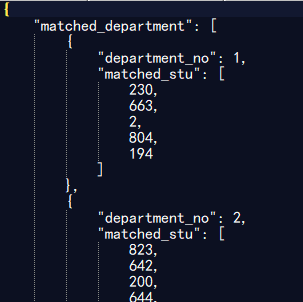
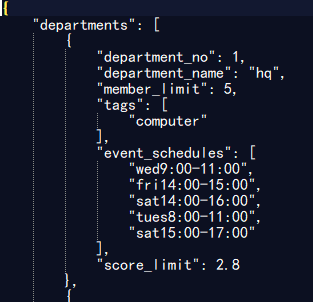
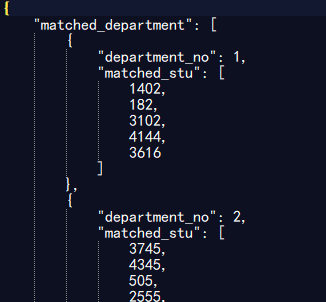
测试5000位同学,100个部门的情况
效能分析报告
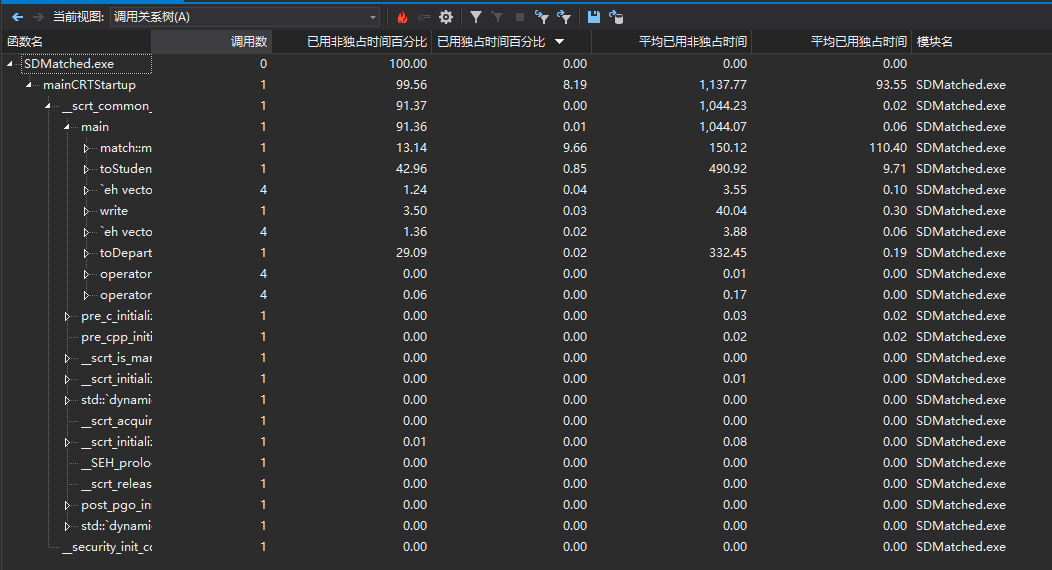
从下图可以看出,读json文件花费时间最多,非独占时间占用了72.05%;其次是匹配算法,非独占时间占用了13.14%,写json非独占时间占用了3.50%。可以从读json文件和匹配算法方面考虑优化程序。
遇到的困难及解决方法
- 遇到的困难
- 第一次接触JSON格式文件,对其不了解,解析和生成JSON格式的学生和部门信息遇到困难。
- 接口的概念理解不够深刻,输入输出的接口设计遇到问题。
- 对于代码规范缺乏经验。
- 做过的尝试
- 搜索JSON文件的相关文档,理解其格式与结构。查找现在主流的解析及生成JSON的C++库,并学习其使用方法。
- 搜寻相关代码,参考别人的设计方式。
- 查阅主流的代码规范,并针对自己的项目,作出适当修改。
- 是否解决
根据实际情况,我们选择使用rapidjson对JSON文件进行解析和生成,通过阅读官方的文档和参考现有的代码,成功得解决了相关问题。但是对于接口的设计,仍然很困惑。不懂得如何设计,能够为该匹配程序模块后期可能的整合入系统提供便利。至于代码规范,参考了很多文档,找到了最适合我们的规范。 - 收获
- 熟悉了json格式的文件。本次作业中,大量练习了使用rapidjson解析和生成json文件,比如随机生成大量规定的学生和部门信息并读取,基本掌握了该文件的使用方法。
- 首次设计了代码规范。
- 了解了接口的使用。
- 算得上是第一次真正意义上的结对编程。
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 40 |
| · Estimate | · 估计这个任务需要多少时间 | 20 | 10 |
| Development | 开发 | 200 | 150 |
| · Analysis | · 需求分析 (包括学习新技术) | 40 | 30 |
| · Design Spec | · 生成设计文档 | 30 | 40 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 30 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| · Design | · 具体设计 | 30 | 30 |
| · Coding | · 具体编码 | 200 | 300 |
| · Code Review | · 代码复审 | 60 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 40 | 60 |
| Reporting | 报告 | 20 | 20 |
| · Test Report | · 测试报告 | 30 | 40 |
| · Size Measurement | · 计算工作量 | 15 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 795 | 860 |
学习进度条
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 300 | 300 | 5 | 5 | 主要写了数独代码熟悉了算法,学习javascript语法 |
| 2 | 70 | 370 | 6 | 11 | 继续习javascript语法、熟悉了原型设计,用到工具Axure RP,学习了NABCD |
| 3 | 200 | 570 | 8 | 19 | 学习php |
| 5 | 500 | 1070 | 14 | 33 | 了解json,完成结对作业 |