一、安装selenium2library库
如果已经安装了pip,则使用管理员模式打开windows命令行,输入pip install robotframework-selenium2library,安装完成后在命令行输入pip list查看python的安装列表,列表中出现了robotframework-selenium2library及对应的版本号,说明安装完成。
二、导入selenium2library库
添加完成,黑色示添加的库正常,红色表示库不存。如果为红色,请检查C:Python27Libsite-packages 目录下是否有 Selenium2Library 目录

按F5可调出关键字查询窗口。source选择Selenium2Lilrary,然后输入关键字,点击搜索。选择关键字可以查看关键字的说明

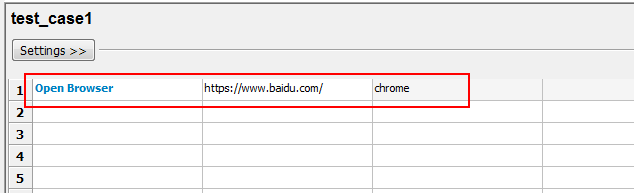
三、第一个例子
比如打开百度,输入一个Open Browser关键字,如果关键字为蓝色说明它是一个合法的关键字,后面有一个方框是红色的,表示这个参数不能缺省的。通过说明信息中,我发现它需要一个 url 地址是必填的,当然还需要指定 browser (默认不填为 friefox)
四、元素定位
Web 自动化测试其实就是找到元素(定位元素)并操作元素。
Selenium2Library 提供了非常丰富的定位器:
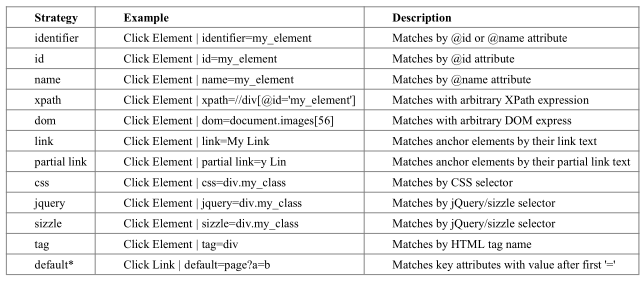
最常用的其实是id、name、xpath、css。 id 和 name两种定位方式非常简单且实用, xpath 和 css两种定位方式足够强大,可以满足几乎所有定位需求。
1、id和name定位
以百度为例。我们可看到输入框input元素有id和name属性,百度一下按钮有id属性。


输入框:id=kw name=wd,在 Robot framework 中就是这样写的:

Input text 用于输入框的关键字 ,后面两个参数,一个是元素的定位,一个是输入框输入的值。
百度一下按钮:id=su,在 Robot framework 中就是这样写的:

click button用户点击按钮的关键字,后面跟着一个必填参数。
2、xpath定位
XPath 是一种在 XML 文档中定位元素的语言。因为 HTML 可以看做 XML 的一种实现,所以 selenium用户可是使用这种强大语言在 web 应用中定位元素。如果一个元素没有id和name或没有唯一标识可以使用xpath 通过层级关系找到元素。
(1)xpath绝对路径
比如百度页面的搜索输入框xpath=/html/body/div[2]/div[1]/div/div[1]/div/form/span[1]/input。绝对路径的用法往往是在我们迫不得已的时候才用的。大多时候用相对路径更简便
(2)xpath的相对路径
使用元素本身定位:比如百度页面的搜索输入框xpath=//*[@id="kw"],可以利用元素自身的属性。//表示某个层级下,*表示某个标签名。@id=kw表示这个元素有个 id 等于 kw
当然,一般也可以制定标签名:xpath=//input[@id="kw"]元素本身,可以利用的属性就不只局限为于 id 和 name ,如:Xpath = //input[@autocomplete=’off’],但要保证这些元素可以唯一的识别一个元素。
找上级:如果一个元素找不到可以先找到他的上级。比如:xpath = //span[@class='bg s_btn_wr’]/input,如果父级没有唯一标识,还可以继续往上找:
xpath = //form[@id=’form1’]/span/input
布尔值写法:
Xpath = //input[@id=’kw1’ and @name=’wd’]
总结:使用过程中发现xpath定位有时候语法并没有任何问题也定位不到元素,比如xpath = //span[@class='bg s_btn_wr’]/input。
3、css 定位
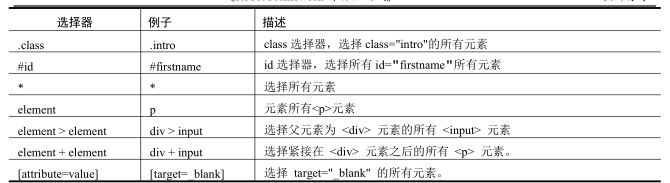
CSS(Cascading Style Sheets)是一种语言,它被用来描述 HTML 和 XML 文档的表现。CSS 使用选择器来为页面元素绑定属性。这些选择器可以被 selenium 用作另外的定位策略。CSS 可以比较灵活选择控件的任意属性,一般情况下定位速度要比 XPath 快。
CSS 选择器的常见语法:

五、Selenium2Library 常用关键字
1、浏览器驱动

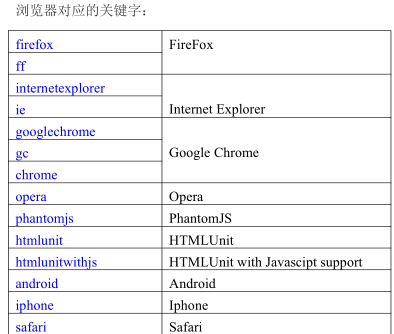
open browser也可以打开本地的文件,比如:

2、关闭浏览器
(1)关闭当前页面

(2)关闭所有页面

3、浏览器最大化

4、设置浏览器窗口宽、高

5、获取浏览器窗口尺寸

6、文本输入
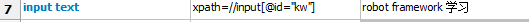
7、点击元素

8、等待元素出现
Arguments:[ locator | timeout=None | error=None ],Xpath=//* [@] :表示元素定位,这里定位出现的元素。42 : 表示最长等待时间。Error : 表示错误提示,自定义错误提示,如:“元素不能正常显示”

9、获取 title
Returns title of current page.我们通常会将获取的 title 传递给一个变量,然后与预期结果进行比较。从而判断当前脚本执行成功

10、获取元素的text
Arguments:[ locator ],Returns the text value of element identified by `locator`.

11、获取元素的属性值
id=kw@name:id=kw 表示定位的元素。@nam 获取这个元素的 name 属性值。

12、cookie处理

get cookies 获得当前浏览器的所有 cookie 。
get cookie value 获得 cookie 值。key_name 表示一对 cookie 中 key 的 name 。
add cookie 添加 cookie。添加一对 cooke (key:value)
delete cookie 删除 cookie。删除 key 为 name 的 cookie 信息。
delete all cookies 删除当前浏览器的所有 cookies。
13、验证should contain
例子:先获取页面的title,赋值给${tt};然后去对比是否等于百度一下你就知道了。

14、表单嵌套

15、下拉框选择
Arguments:[ locator | *values ]。 locator 为定位下拉框;Vlaue 为选择下拉框里的属性值。

16、执行 JavaScript
Execute Javascript 关键字用于使用 JavaScript 代码,参数就是JavaScript 代码
