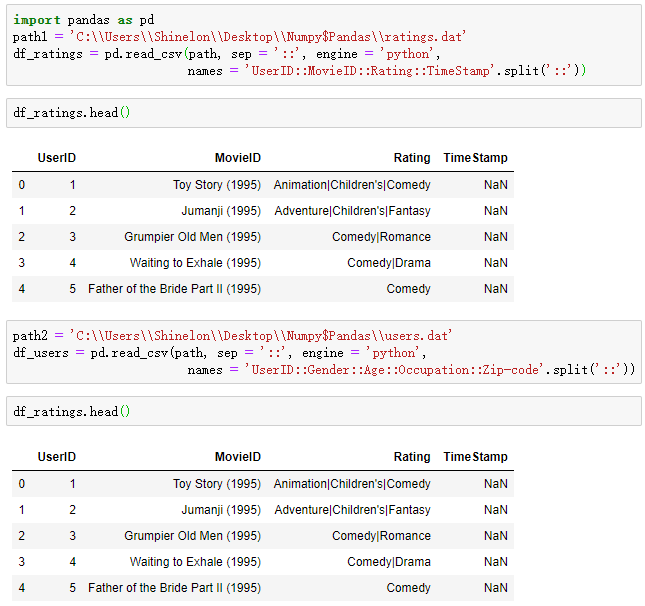
一、Pandas中的表连接Merge语法
1.merge的语法
pd.mergel(eft, right, how="inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=True, suffixes=('_x','_y'), copy=True, indicator=False, valldate=None)
●left, right: 要merge的dataframe或者有name的Series
●how: join类型, left', 'right, 'outer', 'inner'
●on: join的key, left和right都需要有这个key
●left_on: left的df或者series的key
●right_on: right的df或者seires的key
●left_index, right_index: 使用index而不是普通的column做join
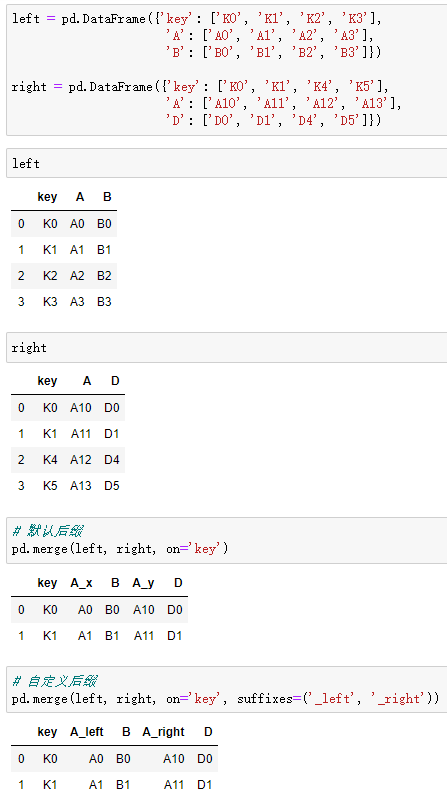
●sufixes:两个元素的后缀,如果列有重名,自动添加后缀,默认是('_X','_Y')
数据
表连接

merge时数量的对齐关系
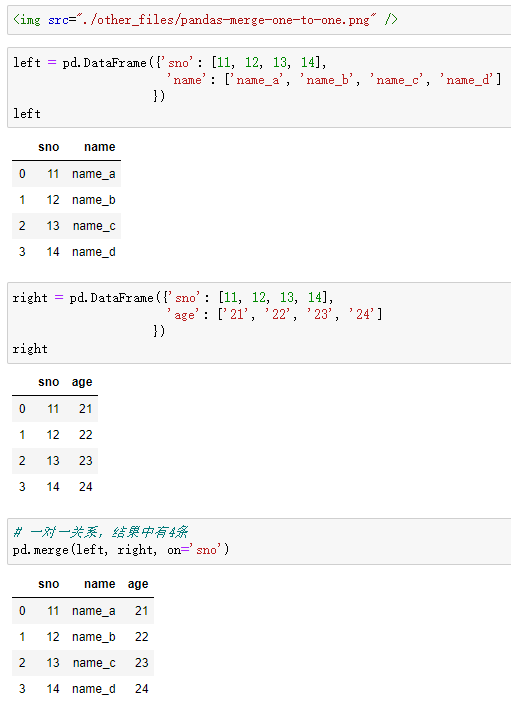
one-to-one:一对一关系,关联的key都是唯一的
比如(学号,姓名) merge (学号,年龄)
结果条数为:1*1
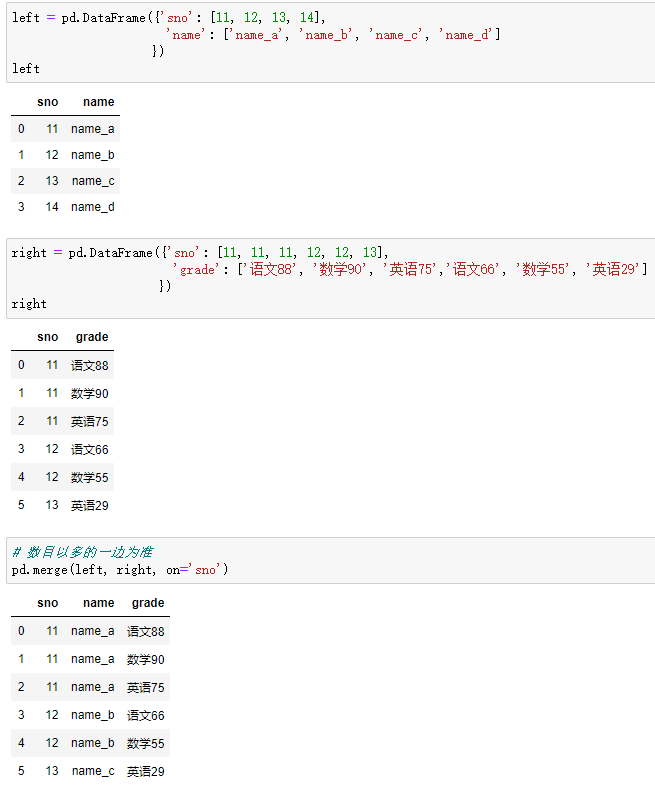
one-to-many:一对多关系,左边唯一key,右边不唯一key
比如(学号,姓名) merge (学号,[语文成绩、数学成绩、英语成绩])
结果条数为:1*N
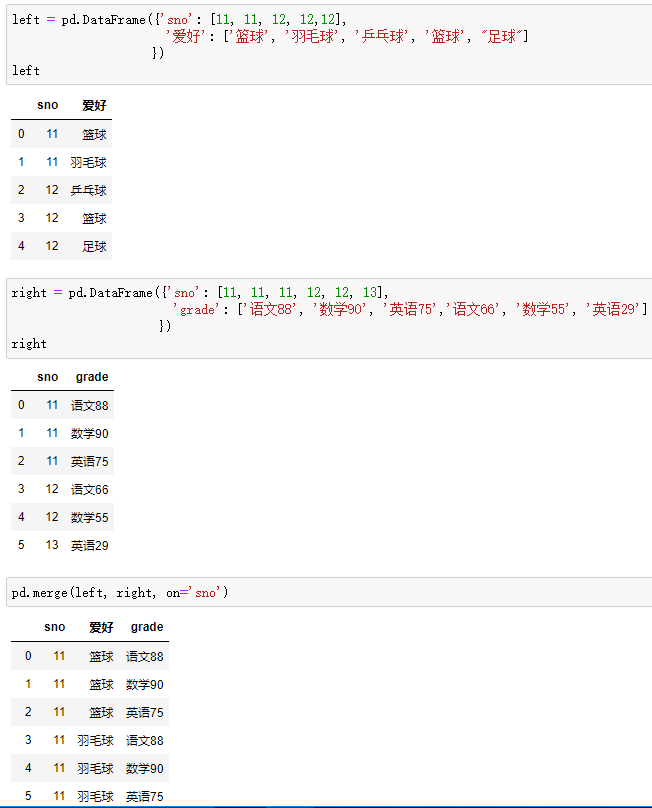
many-to-many:多对多关系,左边右边都不是唯一的
比如(学号,[语文成绩、数学成绩、英语成绩]) merge (学号,[篮球、足球、乒乓球])
结果条数为:M*N
非Key字段重名时
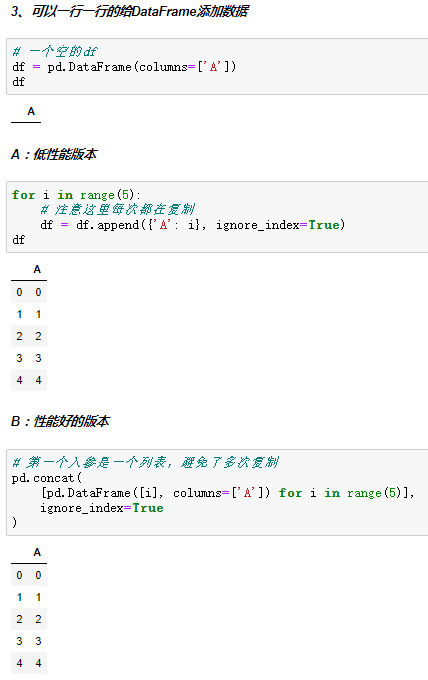
二、Pandas数据合并 concat
使用场景:
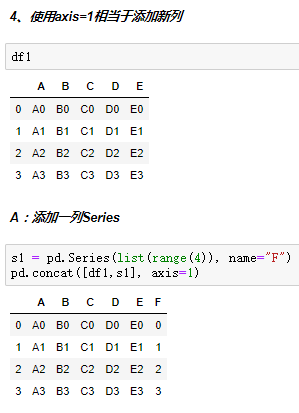
批量合并相同格式的Excel、给DataFrame添加行、给DataFrame添加列
一句话说明concat语法:
使用某种合并方式(inner/outer)
沿着某个轴向(axis=0/1)
把多个Pandas对象(DataFrame/Series)合并成一个。
concat语法:pandas.concat(objs, axis=0, join='outer', ignore_index=False)
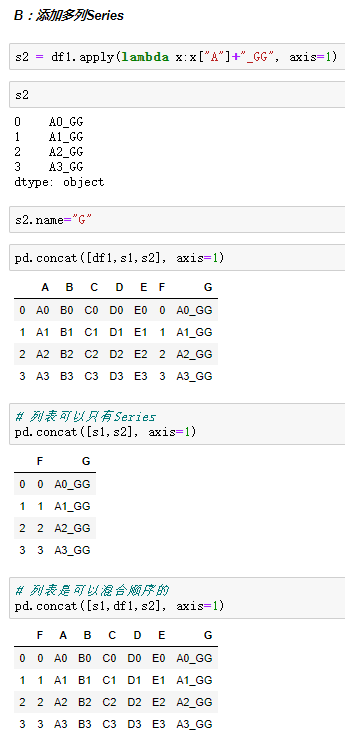
objs:一个列表,内容可以是DataFrame或者Series,可以混合
axis:默认是0代表按行合并,如果等于1代表按列合并
join:合并的时候索引的对齐方式,默认是outer join,也可以是inner join
ignore_index:是否忽略掉原来的数据索引
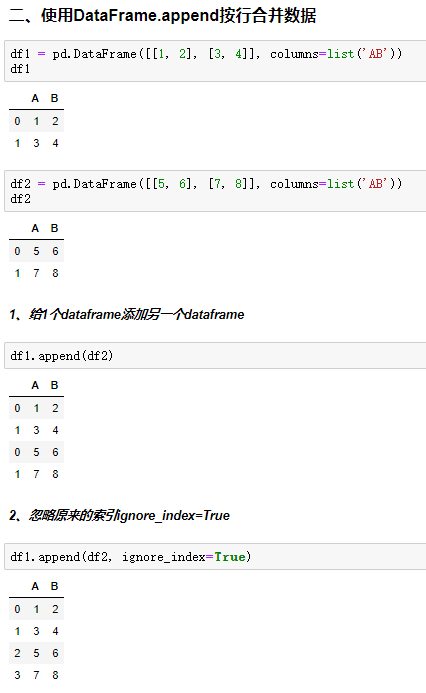
append语法:DataFrame.append(other, ignore_index=False)
append只有按行合并,没有按列合并,相当于concat按行的简写形式
other:单个dataframe、series、dict,或者列表
ignore_index:是否忽略掉原来的数据索引


三、Pandas批量拆分Excel并合并Excel
1.读取数据源Excel到Pandas

2.将一个大Excel等份拆成多个Excel
使用df.iloc方法,将一个大的dataframe,拆分成多个小dataframe
将使用dataframe.to_excel保存每个小Excel

3.合并多个小Excel到一个大Excel


四、Pandas实现分组统计
1.制作数据源
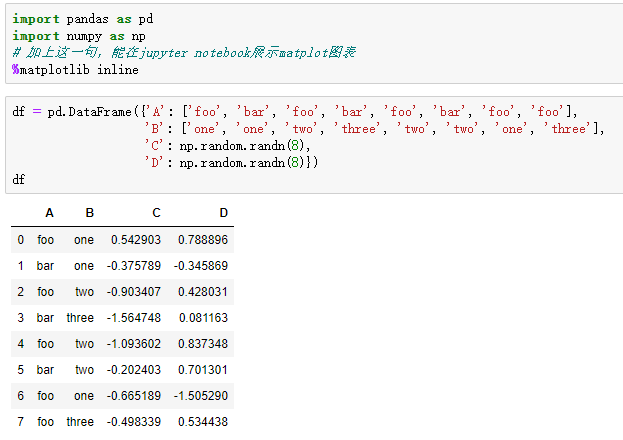
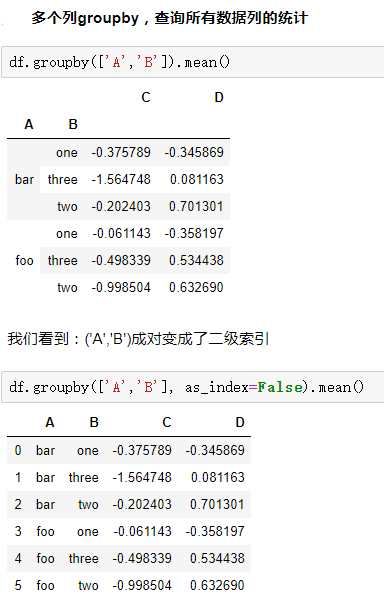
2.分组使用聚合函数做数据统计



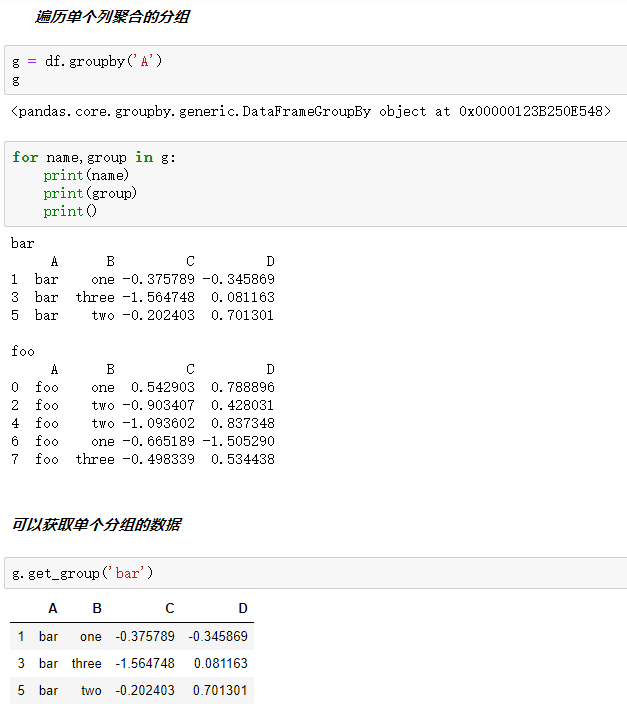
3.遍历groupby的结果
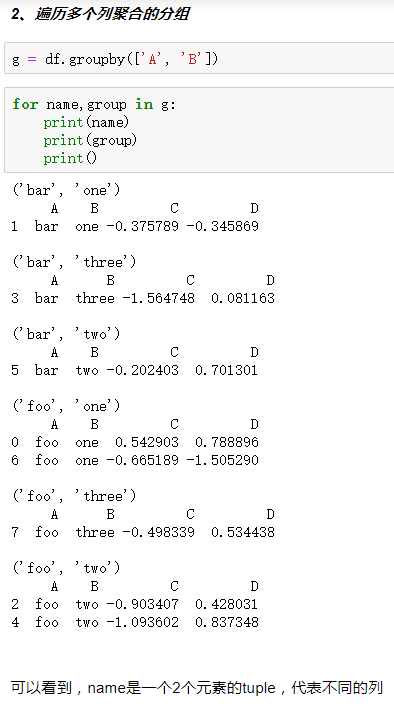
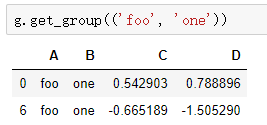
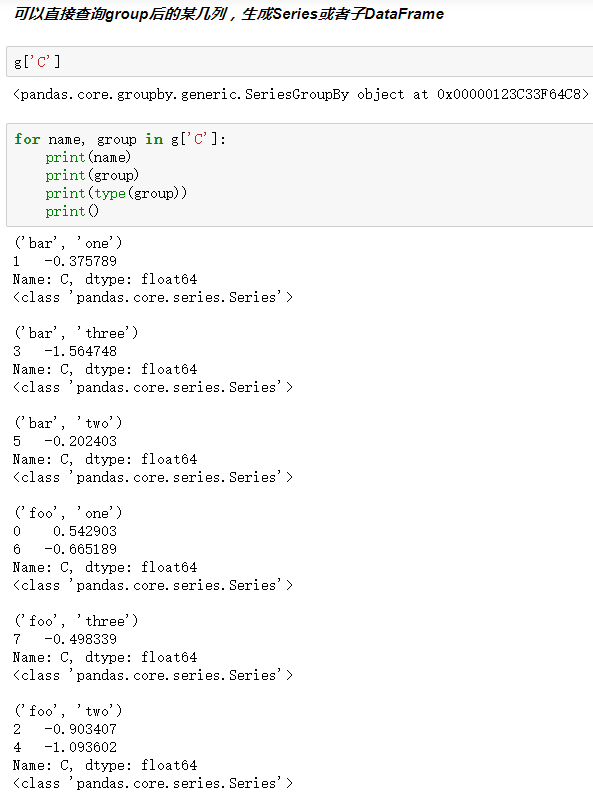
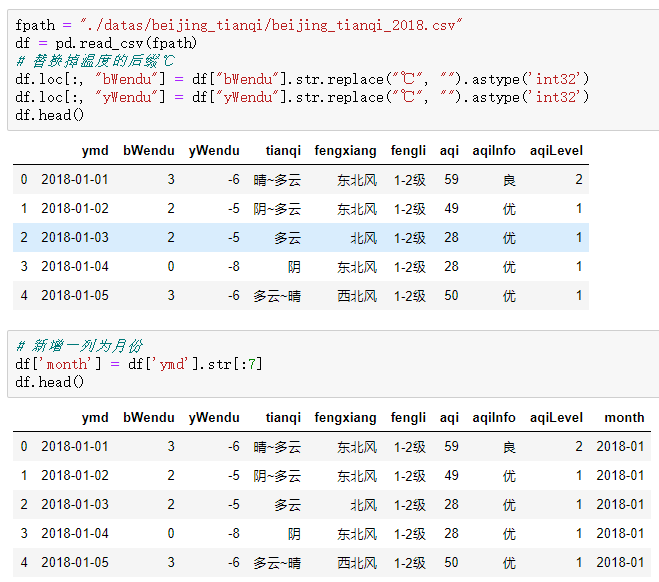
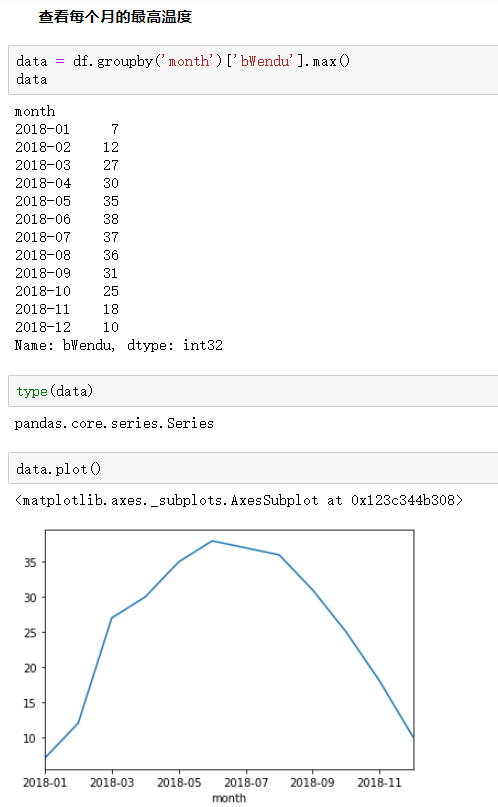
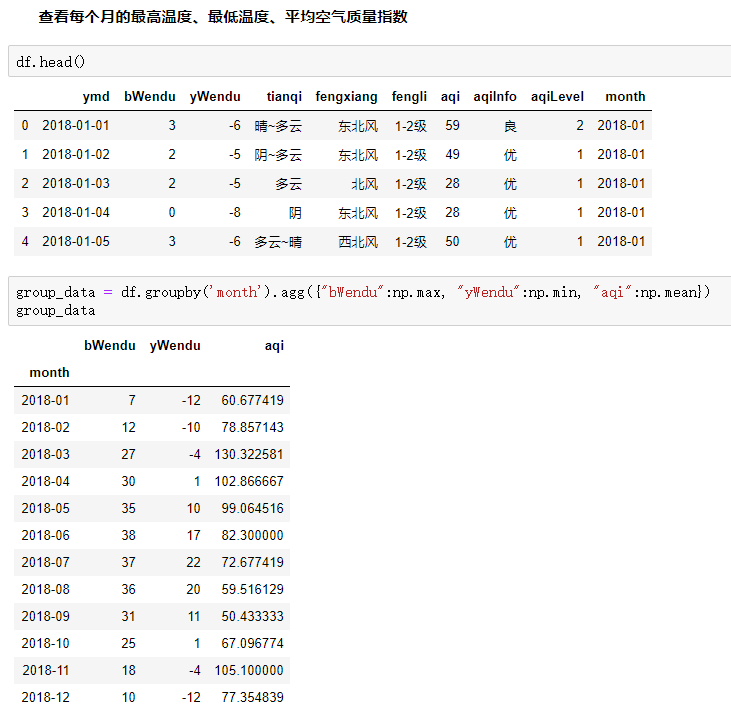
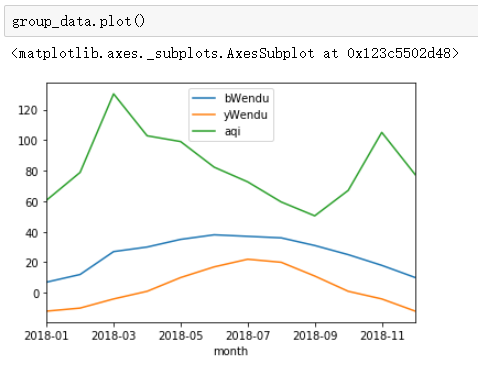
4.分组探索天气数据
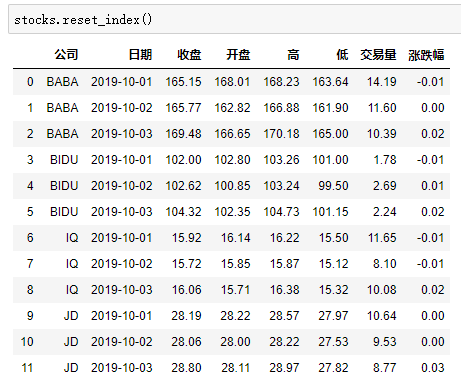
五、Pandas的分层索引MultiIndex
●分层索引:在一个轴向上拥有多个索引层级,可以表达更高维度数据的形式;
●可以更方便的进行数据筛选,如果有序则性能更好;
●groupby等操作的结果,如果是多KEY,结果是分层索引,需要会使用
●一般不需要自己创建分层索引(MultiIndex有构造函数但一般不用)
1.导入数据
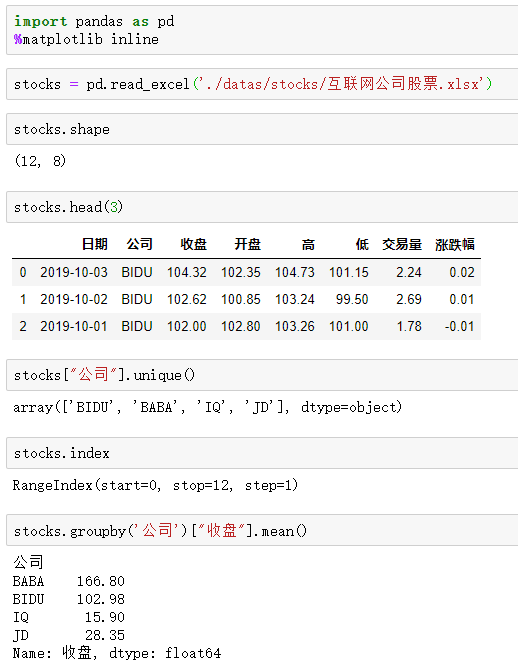
2.Series的分层索引MultiIndex
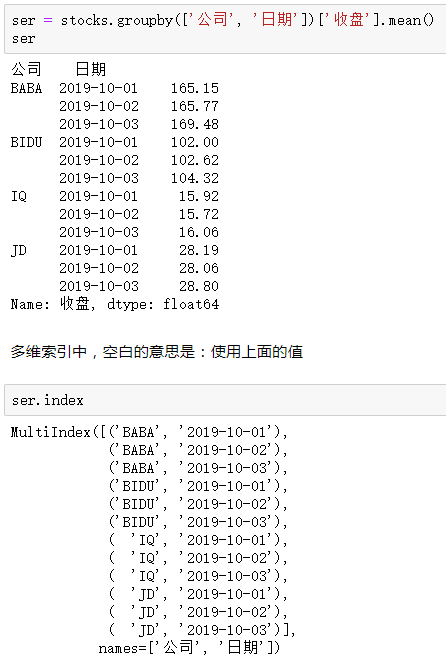
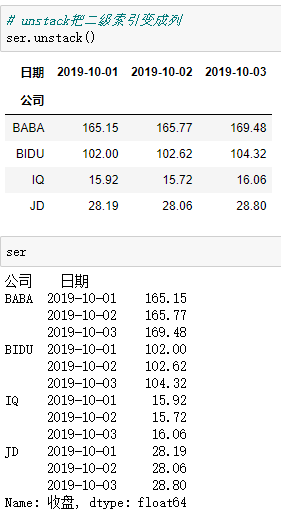
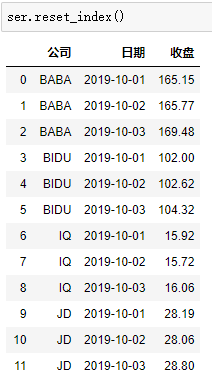
3.MultiIndex筛选有多层索引的数据
4.DataFrame的多层索引MultiIndex
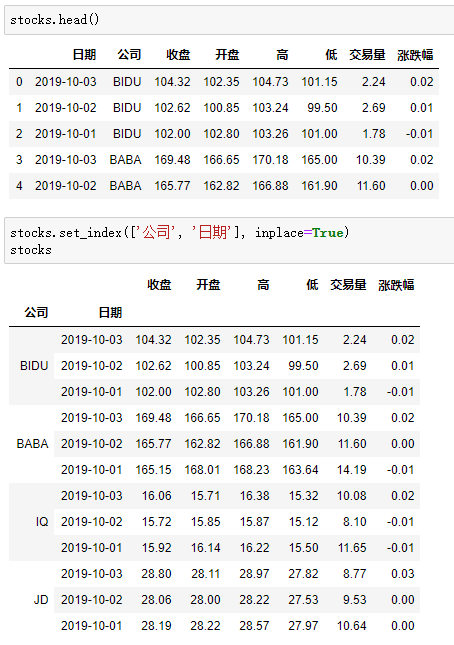
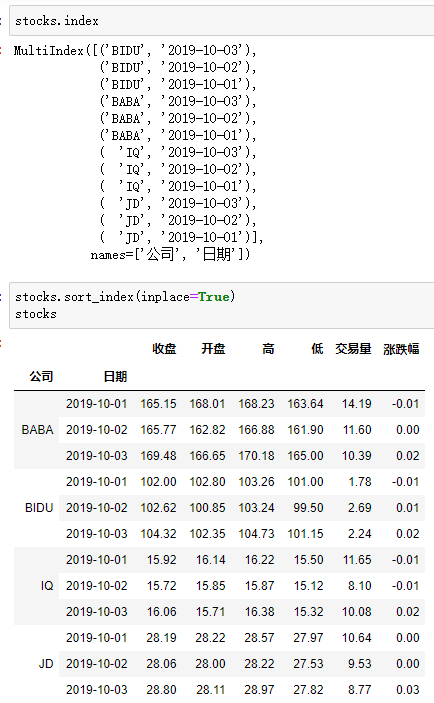
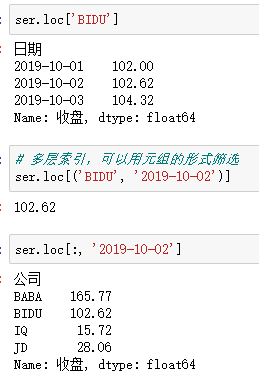
5.MultiIndex筛选多层索引数据
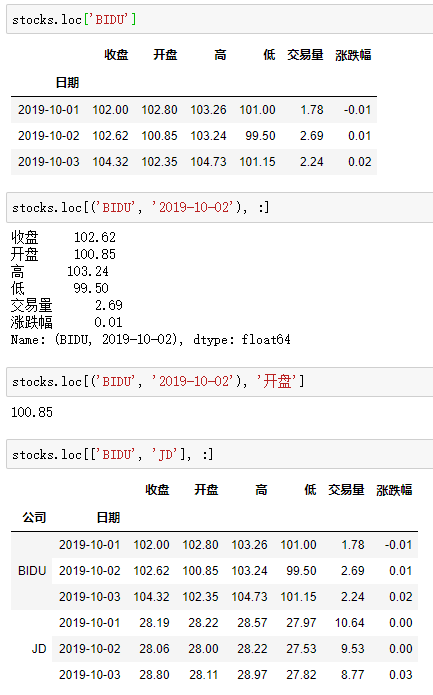
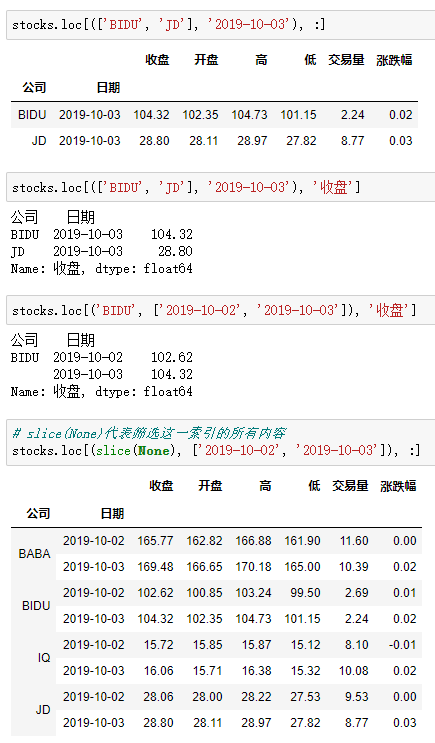
【重要知识】在选择数据时:
●元组(key1,key2)代表筛选多层索引,其中key1是索引第一级,key2是第二级,比如key1=JD, key2=2019-10-02
●列表[key1,key2]代表同一层的多个KEY,其中key1和key2是并列的同级索引,比如key1=JD, key2=BIDU