缘由
公司使用的是Docker+微服务,服务拆分差不多41个了,然后过完年来就接到这个需求,把指定业务功能的业务基线整理出来,比如,登录这个操作会经过哪些微服务,把登录这个操作的链条列出来,从api--途径的服务--DB这样一个链条。接到这个需求后,我就傻逼似的一个一个去问开发,然而开发每个人只负责自己开发的模块,具体途径的他们也不知道;然后一直拖一直拖,拖到了现在,总得找个办法把这个给完成了,刚好公司有用到Zipkin这个,但是并不了解,只知道有这么个东西,那就先了解他,然后根据他的数据库和我们自己的ELK操作日志找到这些个调用链路。
思路
ELK日志会记录操作日志,日志里会把Zipkin的三个ID打印出来,比如我做一个登陆操作,通过Kibana显示的ELK里会有登陆这个操作的日志,那我获取这个登陆操作的SpanId,通过Zipkin的API接口和SpanId可以获取所有和这个SpanId有关的信息;然后根据获取的信息把调用链给整理出来。
Zipkin的相关了解
主要是根据写篇博文学习;参考地址:https://juejin.im/post/5c3d4df0f265da61307517ad
一、Zipkin的由来
在单机系统使用过程中,如果某个请求响应过慢或者响应出错,通过查看日志就可以清楚的知道某个请求出了问题;如果在分布式系统中,客户端一个请求到达服务器后,由多个服务协作完成。如服务A调用服务B,服务B调用服务C,服务C调用服务D,那么想要知道哪个服务处理时间过长或是处理异常导致的话,就需要一个服务一个服务的去机器查看日志,先定位出问题的服务,再定位出问题的地方。随着系统越来越壮大,服务越来越多,一个请求对应处理的服务调用链就越长,这种排查方式很艰难,为了解决这个问题,便诞生了各种分布式场景中追踪问题的解决方案,zipkin就是其中之一。
二、什么是ZipKin
一个独立的分布式追踪系统,客户端存在于应用中(各个服务中),应具备追踪信息生成,采集发送等功能,而服务端应该包含以下基本的三个功能
1)信息收集:用来收集各服务端采集的信息,并对这些信息进行梳理存储、建立索引
2)数据存储:存储追踪数据
3)查询服务:提供查询请求链路信息的接口
三、 它的整体结构图
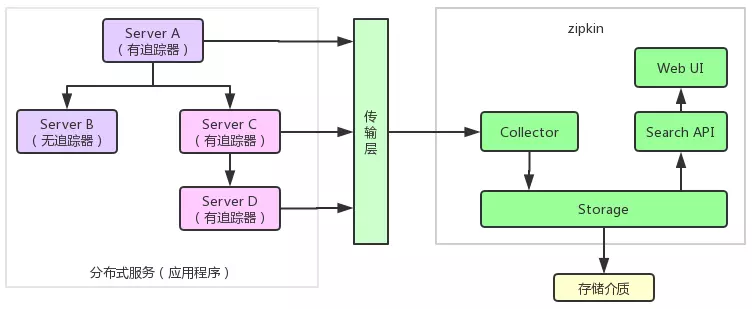
Zipkin(服务端)包含四个组件,分别是collector,storage,search,Web UI
1)collector信息收集器,作为一个守护进程,它会时刻等待着客户端传递过来的追踪数据,对这些数据进程验证,存储以及创建查询需要的索引
2)storage是存储组件,zipkin默认直接将数据存储在内存中,此外支持使用Cassandra、Elasticsearch和Mysql
3)search是一个查询进程,它提供了简单的JSON API来提供外部调用查询
4)Web UI是zipkin的服务端展示平台,主要调用search提供的接口,用图标将链路信息清晰的展示
四、基本概念
Trace:一个请求达到应用后所调用的所有服务组成的调用链就像一个树结构(如图),我们追踪这个调用链路得到的这个数结构可以称之为Trace
Span:在一次Trace中,每个服务的每一次调用,就是一个基本工作单元(如图中的每一个树节点),称之为span

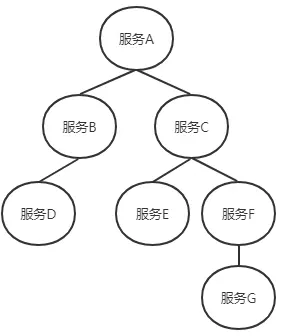
每一个span都有一个id作为唯一标识,同样每一次Trace都会生成一个traceID在span中作为追踪评标识,另外再通过一个parentId标明本次调用的发起者(就是发起者的span-id)。当span有了上面三个标识后,就可以很清晰的将多个span进行梳理串联,最终归纳出一条完整的跟踪链路。
五、实战
1)根据指定的trace_id获得返回值,然后根据返回值分析调用链
curl http://localhost:9411/api/v2/trace/2e0d4019eb7aae31
2)获取所有的服务
curl http://localhost:9411/api/v2/services
3)span数据结构详解
一次追踪链路会包含很多的span,因此一个span便是一个数组,标准的json为:
[ { "traceId": "string", // 追踪链路ID "name": "string", // span名称,一般为方法名称 "parentId": "string", // 调用者ID "id": "string", // spanID "kind": "CLIENT", // 替代zipkin v1的注解中的四个核心状态,详细介绍见下文 "timestamp": 0, // 时间戳,调用时间 "duration": 0, // 持续时间-调用的服务所消耗的时间 "debug": true, "shared": true, "localEndpoint": { // 本地网络节点上下文 "serviceName": "string", "ipv4": "string", "ipv6": "string", "port": 0 }, "remoteEndpoint": { // 远端网络节点上下文 "serviceName": "string", "ipv4": "string", "ipv6": "string", "port": 0 }, "annotations": [ // value通常是缩写代码,对应的时间戳表示代码标记事件的时间 { "timestamp": 0, "value": "string" } ], "tags": { // span的上下文信息,比如:http.method、http.path "additionalProp1": "string", "additionalProp2": "string", "additionalProp3": "string" } } ]
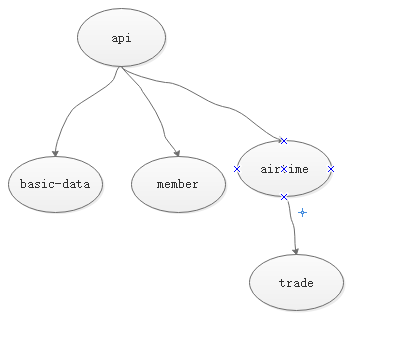
我的根据返回的json信息,并根据traceId、parentId、id、kind(CLINET、CLIENT)把谁调用谁,哪个服务到哪个服务整理出来:

六、有关Cassandra数据库相关操作
1)连接数据库
cqlsh 172.10.0.5
2)查看所有的库
cqlsh> describe keyspaces;
3)使用指定的库
cqlsh> use zipkin2;
4)查看所有的表
cqlsh> describe tables;
5)根据指定条件查询
#查询前得对查询列建立索引 cqlsh:zipkin2> create index on span(trace_id); cqlsh:zipkin2> select * from trace_by_service_span where trace_id='f81a638649326474';