一、【转载】一致性哈希算法的原理
一致性哈希算法,是分布式系统中常用的算法,比如有N台缓存服务器,你需要将数据缓存到这N台服务器上。一致性哈希算法可以将数据尽可能平均的存储到N台缓存服务器上,提高系统的负载均衡,并且当有缓存服务器加入或退出集群时,尽可能少的影响现有缓存服务器的命中率,减少数据对后台服务的大量冲击。
一致性哈希算法的基本原理,把数据通过hash函数映射到一个很大的环形空间里,如下图所示:
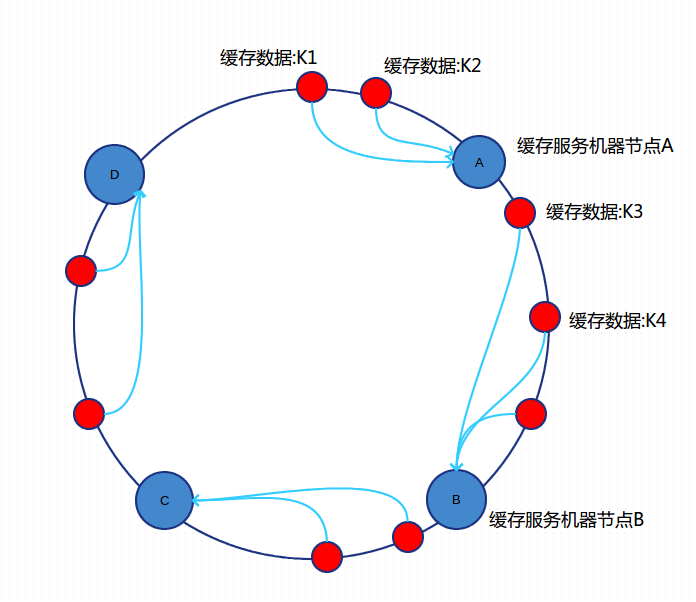
A、B、C、D 4台缓存服务器通过hash函数映射环形空间上,数据的存储时,先得到一个hash值,对应到这个环中的每个位置,如缓存数据:K1对应到了图中所示的位置,然后沿顺时针找到一个机器节点A,将K1存储到A节点上,K2存储到A节点上,K3、K4存储到B节点上。
如果B节点宕机了,则B上的数据就会落到C节点上,如下图所示:
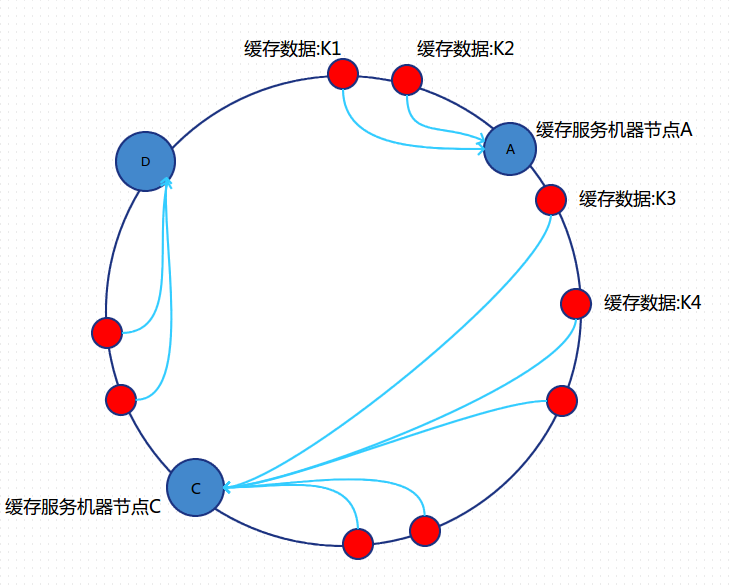
这样,只会影响C节点,对其他的节点A,D的数据不会造成影响。然而,这又会造成一个“雪崩”的情况,即C节点由于承担了B节点的数据,所以C节点的负载会变高,C节点很容易也宕机,这样依次下去,这样造成整个集群都挂了。
为此,引入了“虚拟节点”的概念:即把想象在这个环上有很多“虚拟节点”,数据的存储是沿着环的顺时针方向找一个虚拟节点,每个虚拟节点都会关联到一个真实节点,如下图所使用:
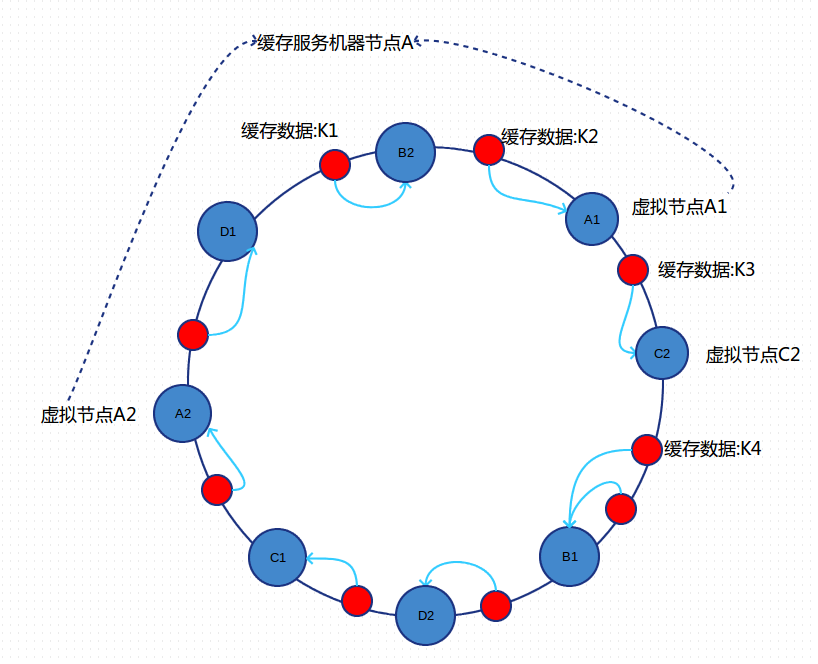
引入“虚拟节点”后,映射关系就从 {对象 ->节点 }转换到了 {对象 ->虚拟节点 }。图中的A1、A2、B1、B2、C1、C2、D1、D2都是虚拟节点,机器A负载存储A1、A2的数据,机器B负载存储B1、B2的数据,机器C负载存储C1、C2的数据。由于这些虚拟节点数量很多,均匀分布,提高了平衡性,因此不会造成“雪崩”现象。
二、项目实战
1、故事描述:
数据库集群中,有三台主库master1、master2、master3和三台从库slave1、slave2、slave3(主从备份关系)。
现有一业务需求,要求将客户信息Customr(idcardNo:身份证号,name:姓名)保存到数据库中,由于客户数据量特别大,所以要采用分库进行存储。分库的逻辑是:使用客户的身份证号,进行一致性hash运算后,分别存储在master1/2/3中的其中一台;同时要求,为提高服务器查询性能,要进行主从读写分离处理。
2、实现步骤:
- 在本地创建六个主从数据库,采用触发器模拟实现主从数据同步功能
- 修改数据库配置文件,增加以上六个数据源节点,增加动态数据源路由配置
- 实现一致性hash算法工具类:HashFunction、ConsistentHash<T>
- 重写DynamicDataSourceHolder、DynamicDataSource两个类,使用一致性hash算法,动态计算要查询的目标数据库,实现动态数据源切换:
- 编写Service层的业务代码
- 编写Controller和客户端代码
- 运行代码,测试结果
3、实现详情:
步骤一:在本地创建六个主从数据库,采用触发器模拟实现主从数据同步功能
(1)新建数据库:nb_master_01、nb_master_02、nb_master_03、nb_slave_01、nb_slave_02、nb_slave_03
(2)在六个数据库中,新建客户信息表customer
# 人员信息表 DROP TABLE IF EXISTS customer; CREATE TABLE customer( id varchar(25) not null comment '主键id', idcard_no VARCHAR(18) not null comment '身份证号', name VARCHAR(50) comment '姓名', sex CHAR(2) comment '性别', remark varchar(50) default '主库-master-01' comment '信息备注', );
(3)在三台主库中,分别创建“insert、update、delete”操作对应的触发器
触发器增加成功后,当主库通过insert/update/delete语句进行操作时,操作结果会同步更新到从库之中,从而实现从库自动同步主库数据的功能。
################################ 增加数据同步触发器
#######注意根据主从对应关系,修改sql中的主库和从库名称
use nb_master_01; create TRIGGER tr_insert_customer after INSERT on customer for EACH ROW BEGIN -- 向从库nb_slave_01中的customer表,插入一条数据 insert into nb_slave_01.customer (id,idcard_no,name,sex) values (new.id,new.idcard_no,new.name,new.sex); END; use nb_master_01; create TRIGGER tr_update_customer after UPDATE on customer for EACH ROW BEGIN -- 向从库中同步数据 update nb_slave_01.customer set id=new.id,idcard_no=new.idcard_no,name=new.name,sex=new.sex where id=new.id; END; use nb_master_01; create TRIGGER tr_delete_customer before DELETE on customer for EACH ROW BEGIN -- 向从库中同步数据 delete from nb_slave_01.customer where id=old.id; END;
步骤二:修改数据库配置文件,增加以上六个数据库节点
(1)修改db.properties,增加数据库的连接地址
#配置主从数据库的链接地址 #主库1 master1.jdbc.url=jdbc:mysql://localhost:3306/nb_master_01?useUnicode=true&characterEncoding=utf8 #主库 master2.jdbc.url=jdbc:mysql://localhost:3306/nb_master_02?useUnicode=true&characterEncoding=utf8 #主库 master3.jdbc.url=jdbc:mysql://localhost:3306/nb_master_03?useUnicode=true&characterEncoding=utf8 #从库1 slave1.jdbc.url=jdbc:mysql://localhost:3306/nb_slave_01?useUnicode=true&characterEncoding=utf8 #从库2 slave2.jdbc.url=jdbc:mysql://localhost:3306/nb_slave_02?useUnicode=true&characterEncoding=utf8 #从库 slave3.jdbc.url=jdbc:mysql://localhost:3306/nb_slave_03?useUnicode=true&characterEncoding=utf8
(2)在spring-mybatis.xml配置文件中,增加以上六个数据库的bean
<!--读取静态配置文件,获取相关数据库连接参数 --> <context:property-placeholder location="classpath:db.properties"/> <!-- 配置数据源 --> <bean id="abstractDataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource" abstract="true" destroy-method="close"> <property name="driverClass" value="${jdbc.driver}"/> <property name="user" value="${jdbc.username}"/> <property name="password" value="${jdbc.password}"/> <property name="maxPoolSize" value="${c3p0.maxPoolSize}"/> <property name="minPoolSize" value="${c3p0.minPoolSize}"/> <property name="autoCommitOnClose" value="${c3p0.autoCommitOnClose}"/> <property name="checkoutTimeout" value="${c3p0.checkoutTimeout}"/> <property name="acquireRetryAttempts" value="${c3p0.acquireRetryAttempts}"/> </bean>
<!-- 配置数据源:主库 --> <bean id="master1" parent="abstractDataSource"> <property name="jdbcUrl" value="${master1.jdbc.url}"/> </bean> <!-- 配置数据源:主库 --> <bean id="master2" parent="abstractDataSource"> <property name="jdbcUrl" value="${master2.jdbc.url}"/> </bean> <!-- 配置数据源:主库 --> <bean id="master3" parent="abstractDataSource"> <property name="jdbcUrl" value="${master3.jdbc.url}"/> </bean> <!-- 配置数据源:从库1 --> <bean id="slave1" parent="abstractDataSource"> <property name="jdbcUrl" value="${slave1.jdbc.url}"/> </bean> <!-- 配置数据源:从库2 --> <bean id="slave2" parent="abstractDataSource"> <property name="jdbcUrl" value="${slave2.jdbc.url}"/> </bean> <!-- 配置数据源:从库3 --> <bean id="slave3" parent="abstractDataSource"> <property name="jdbcUrl" value="${slave3.jdbc.url}"/> </bean>
<!-- 动态数据源配置,这个class要完成实例化 --> <bean id="dynamicDataSource" class="com.newbie.util.dbMultipleRouting.DynamicDataSource"> <property name="targetDataSources"> <!-- 指定lookupKey和与之对应的数据源,切换时使用的为key --> <map key-type="java.lang.String"> <entry key="master1" value-ref="master1"/> <entry key="master2" value-ref="master2"/> <entry key="master3" value-ref="master3"/> <entry key="slave1" value-ref="slave1"/> <entry key="slave2" value-ref="slave2"/> <entry key="slave3" value-ref="slave3"/> </map> </property> <!-- 这里可以指定默认的数据源 --> <property name="defaultTargetDataSource" ref="master1"/> </bean> <!-- 配置MyBatis创建数据库连接的工厂类 --> <bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean"> <!--数据源指定为:动态数据源DynamicDataSource --> <property name="dataSource" ref="dynamicDataSource"/> <!-- mapper配置文件 --> <property name="mapperLocations" value="classpath:com/newbie/dao/*.xml"/> </bean> <!-- 配置自动扫描DAO接口包,动态实现DAO接口实例,注入到Spring容器中进行管理 --> <bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"> <!-- 注入SqlSession工厂对象:SqlSessionFactoryBean --> <property name="sqlSessionFactoryBeanName" value="sqlSessionFactory"/> <!-- 指定要扫描的DAO接口所在包 --> <property name="basePackage" value="com.newbie.dao"/> </bean>
步骤三:实现一致性hash算法工具类:HashFunction、ConsistentHash<T>
(1)新建工具类HashFunction,使用MurMurHash算法,实现key的hash值计算。
一致性hash算法要计算数据库节点的hash值、客户身份证号的hash值,统一使用 HashFunction.hash(key)方法,来计算hash值。
package com.newbie.util.consistentHash; import java.nio.ByteBuffer; import java.nio.ByteOrder; /** * 使用MurMurHash算法,实现key的hash值计算 * MurmurHash是一种非加密型哈希函数,性能很高,碰撞率低,适用于一般的哈希检索操作。 */ public class HashFunction { public Long hash(String key) { ByteBuffer buf = ByteBuffer.wrap(key.getBytes()); int seed = 0x1234ABCD; ByteOrder byteOrder = buf.order(); buf.order(ByteOrder.LITTLE_ENDIAN); long m = 0xc6a4a7935bd1e995L; int r = 47; long h = seed ^ (buf.remaining() * m); long k; while (buf.remaining() >= 8) { k = buf.getLong(); k *= m; k ^= k >>> r; k *= m; h ^= k; h *= m; } if (buf.remaining() > 0) { ByteBuffer finish = ByteBuffer.allocate(8).order(ByteOrder.LITTLE_ENDIAN); finish.put(buf).rewind(); h ^= finish.getLong(); h *= m; } h ^= h >>> r; h *= m; h ^= h >>> r; buf.order(byteOrder); return h; } }
(2)新建一致性hash算法工具类:ConsistentHash
a. 定义构造方法,接收数据库节点对象,然后根据节点对象计算生成数据存储的节点;
b. 定义“public T get(String key)”方法,接收客户的身份证号,计算得出该客户信息存储的目标数据节点。
package com.newbie.util.consistentHash; import java.util.Collection; import java.util.SortedMap; import java.util.TreeMap; /**
* 实现一致性hash计算:实现保存数据库节点方法、实现根据身份证号key来查找存储的节点方法
* @param <T> : 数据库节点对象(此处使用数据源对应的key:master1、master2、master3) */ public class ConsistentHash<T> { //hash函数接口,调用该接口的hash(key)方法,计算hash值 private final HashFunction hashFunction; //每个机器节点,关联的虚拟节点个数 private final int numberOfReplicas; //环形虚拟节点 private final SortedMap<Long, T> circle = new TreeMap<Long, T>(); /** * @param hashFunction:hash 函数接口 * @param numberOfReplicas;每个机器节点关联的虚拟节点个数 * @param nodes: 真实机器节点 */ public ConsistentHash(HashFunction hashFunction, int numberOfReplicas, Collection<T> nodes) { this.hashFunction = hashFunction; this.numberOfReplicas = numberOfReplicas; //遍历真实节点,生成对应的虚拟节点 for (T node : nodes) { add(node); } } /** * 增加真实机器节点 * 由真实节点,计算生成虚拟节点 * @param node */ public void add(T node) { for (int i = 0; i < this.numberOfReplicas; i++) { long hashcode = this.hashFunction.hash(node.toString() + "-" + i); circle.put(hashcode, node); } } /** * 删除真实机器节点 * * @param node */ public void remove(T node) { for (int i = 0; i < this.numberOfReplicas; i++) { long hashcode = this.hashFunction.hash(node.toString() + "-" + i); circle.remove(hashcode); } } /** * * 根据数据的key,计算hash值,然后从虚拟节点中,查询取得真实机器节点对象 * @param key * @return */ public T get(String key) { if (circle.isEmpty()) { return null; } long hash = hashFunction.hash(key); if (!circle.containsKey(hash)) { SortedMap<Long, T> tailMap = circle.tailMap(hash);// 沿环的顺时针找到一个虚拟节点 hash = tailMap.isEmpty() ? circle.firstKey() : tailMap.firstKey(); } return circle.get(hash); // 返回该虚拟节点对应的真实机器节点的信息 } }
步骤四:使用一致性hash算法,动态计算要查询的目标数据库,实现动态数据源切换
(1)重写DynamicDataSourceHolder类的实现,实现以下功能:
- 属性 -- ThreadLocal<String> DATA_SOURCE_KEY :保存当前主从数据源标识-master/slave,由Service层的方法设置该属性,指定要操作的是主库,还是从库。
- 属性 -- ThreadLocal<String> CONSISTENT_HASH_KEY :保存要增加(查询)的客户身份证号,用于计算hash值,由Service层的方法设置该属性。
- 属性 -- ArrayList<String> dataSouceKeyList : 保存所有主库数据源对应的key值集合[master1、master2、master3],用于一致性hash算法中计算生成主机存储节点。在Spring容器实例化DynamicDataSource对象时,通过重写的afterPropertiesSet()方法,主动给本类的dataSouceKeyList、consistentHashDB进行赋值和实例化。
- 属性 -- ConsistentHash<String> consistentHashDB :一致性hash算法工具对象,用于根据身份证号,计算获取数据的存储节点,获取目标数据源的key。由DynamicDataSource对象的afterPropertiesSet()方法,进行实例化。
- 方法 -- public static String getDataSourceFinalKey():根据客户的身份证号【CONSISTENT_HASH_KEY】,计算数据存储的主库数据源key;再根据【DATA_SOURCE_KEY】属性的值,判断要操作的是主库还是从库,是否应该修改为从库的key,进行主从读写分离,最终实现数据源的动态切换。
package com.newbie.util.dbMultipleRouting; import com.newbie.util.consistentHash.ConsistentHash; import com.newbie.util.consistentHash.HashFunction; import java.util.ArrayList; import java.util.List; import java.util.concurrent.atomic.AtomicInteger; /** * 自定义类:用来保存数据源标识,从而在实例化DynamicDataSource时来指定要使用的数据源实例 */ public class DynamicDataSourceHolder { /** * 注意:数据源标识保存在线程变量中,避免多线程操作数据源时互相干扰 */ private static final ThreadLocal<String> DATA_SOURCE_KEY = new ThreadLocal<String>(); /** * 分库方案中,用于计算hash码的基值 */ private static final ThreadLocal<String> CONSISTENT_HASH_KEY = new ThreadLocal<String>(); /** * 所有主库对应的key值集合 * 在一致性hash算法中,用于生成主机虚拟节点 */ private static List<String> dataSouceKeyList = new ArrayList<String>(); /** * 一致性hash算法工具 */ private static ConsistentHash<String> consistentHashDB = null; public static String getDataSourceKey(){ return DATA_SOURCE_KEY.get(); } public static void setDataSourceKey(String dataSourceKey){ DATA_SOURCE_KEY.set(dataSourceKey); } public static void clearDataSourceKey(){ DATA_SOURCE_KEY.remove(); } public static String geConsistentHashKey(){ return CONSISTENT_HASH_KEY.get(); } public static void setConsistentHashKey(String consistentHashKey){ CONSISTENT_HASH_KEY.set(consistentHashKey); } public static void clearConsistentHashKey(){ CONSISTENT_HASH_KEY.remove(); } public static List<String> getDataSouceKeyList() { return dataSouceKeyList; } public static void setDataSouceKeyList(List<String> dataSouceKeyList) { DynamicDataSourceHolder.dataSouceKeyList = dataSouceKeyList; } /** * 向主库集合中,增加一个主库节点 * @param key */ public static void addDataSourceKey(String key){ dataSouceKeyList.add(key); } /** * 使用主库集合,实现一致性hash算法 */ public static void initConsistentHash(){ HashFunction hashFunction = new HashFunction(); consistentHashDB = new ConsistentHash<String>(hashFunction,100,dataSouceKeyList); } /** * 按照一致性hash分表方案,计算真实存储的数据源节点,返回对应的数据源的key * @return */ public static String getDataSourceFinalKey(){ //计算真实节点 String originalKey = consistentHashDB.get(CONSISTENT_HASH_KEY.get()); //判断要操作的是主库,还是从库 if(DATA_SOURCE_KEY.get() == null || DATA_SOURCE_KEY.get().startsWith("master")){ return originalKey; }else{ return originalKey.replace("master","slave"); } } }
(2)修改DynamicDataSource类的实现,重写父类的两个方法:
- public void afterPropertiesSet() :在Spring容器实例化本类对象时,利用反射机制,从父类中拿到数据源对应的key值集合。然后调用DynamicDataSourceHolder类的方法,给属性dataSouceKeyList进行赋值。
- protected Object determineCurrentLookupKey() :调用DynamicDataSourceHolder类的getDataSourceFinalKey()方法,动态设置数据源标识。
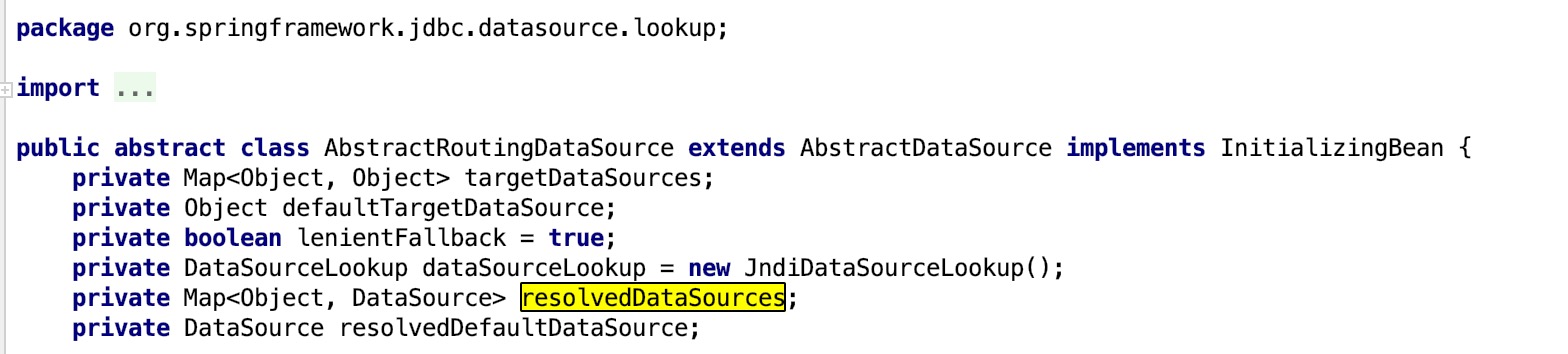
package com.newbie.util.dbMultipleRouting; import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource; import org.springframework.util.ReflectionUtils; import javax.sql.DataSource; import java.lang.reflect.Field; import java.util.*; import java.util.concurrent.atomic.AtomicInteger; /** * DynamicDataSource由自己实现,实现AbstractRoutingDataSource,数据源由自己指定。 */ public class DynamicDataSource extends AbstractRoutingDataSource { /** * 重写父类的方法 * 利用反射机制,从父类中拿到数据源的集合resolvedDataSources,以此设置主库的节点(设置 DynamicDataSourceHolder.dataSouceKeyList) */ @Override public void afterPropertiesSet() { super.afterPropertiesSet(); //由于父类的resolvedDataSources属性是私有的子类获取不到,需要使用反射获取 Field field = ReflectionUtils.findField(AbstractRoutingDataSource.class, "resolvedDataSources"); field.setAccessible(true); Map<String, DataSource> resolvedDataSources = null; try { resolvedDataSources = (Map<String, DataSource>) field.get(this); } catch (IllegalAccessException e) { e.printStackTrace(); } //根据数据源集合resolvedDataSources,来处理主库的集合 if (resolvedDataSources != null) { Set<Map.Entry<String, DataSource>> entrySet = resolvedDataSources.entrySet(); Iterator<Map.Entry<String, DataSource>> iterator = entrySet.iterator(); while (iterator.hasNext()) { //判断key是否以master开头,如果是则认为是主库,并将该key值保存到:ynamicDataSourceHolder.dataSouceKeyList String key = iterator.next().getKey(); if (key != null && key.startsWith("master")) { //将主库的key,加入到主库集合列表中 DynamicDataSourceHolder.addDataSourceKey(key); } } //根据主库集合列表,生成一致性hash算法节点 DynamicDataSourceHolder.initConsistentHash(); } } /** * 动态设置数据源标识 * @return */ @Override protected Object determineCurrentLookupKey() { return DynamicDataSourceHolder.getDataSourceFinalKey(); } }
步骤五:编写Service层的业务代码
package com.newbie.service.impl; import com.newbie.dao.CustomerMapper; import com.newbie.domain.Customer; import com.newbie.domain.CustomerExample; import com.newbie.domain.UserAccount; import com.newbie.service.IConsistentHashService; import com.newbie.util.dbMultipleRouting.DynamicDataSourceHolder; import com.newbie.util.dbMultipleRouting.annotation.AnnotationDBSourceKey; import org.springframework.stereotype.Service; import javax.annotation.Resource; import java.util.ArrayList; import java.util.Iterator; import java.util.List; import java.util.Random; /** * 使用一致性hash的方式,实现分库插入和查询 */ @Service public class ConsistentHashService implements IConsistentHashService { @Resource private CustomerMapper customerMapper; /** * 用于记录每次操作的客户信息,以方便查询和插入操作 */ private List<Customer> customerList = new ArrayList<Customer>(); private int countNumber = 10; //生成10个客户 /** * 批量生成一写用户,保存到List集合,用于插入数据库 和 查询数据库 * @return */ public void initCustomerList(String name) { for (int i = 0; i < countNumber; i++) { Customer customer = new Customer(); String idcardNo = getIdno(); //生成身份证号 customer.setId(idcardNo); customer.setIdcardNo(idcardNo); customer.setName(name + "-" + (countNumber - i)); customerList.add(customer); } } /** * 从客户集合中,随机抽取10个客户,用来查询数据库 */ public List<Customer> getTenCustomer(){ List<Customer> customers = new ArrayList<Customer>(); //设置要随机访问的客户总数 int tmpCoustomerNum = customerList.size() < countNumber ? customerList.size() : countNumber; for (int i = 0; i < tmpCoustomerNum; i++) { int randmoIndex = new Random().nextInt(customerList.size()); Customer customer = customerList.get(randmoIndex); customers.add(customer); } return customers; } /** * 使用随机数,生成身份证号ID * @return */ public String getIdno() { StringBuilder sb = new StringBuilder(""); for (int i = 0; i < 18; i++) { int random = new Random().nextInt(10); if (random == 0) { random = 4; } sb.append(random); } return sb.toString(); } /** * 向主库中,增加客户信息,插入十条数据,默认姓名为"简小六" * @return */ @AnnotationDBSourceKey("master") public String addConstomer() { String message = "<p>插入结束</p>"; message += "<p>插入信息如下:客户姓名 , 身份证号 , 原始数据源 , 最终数据源</p>"; //向属性customerlist中,添加客户信息 String name = "简小七"; initCustomerList(name); int customerListSize = customerList.size(); //向数据库中插入数据 Iterator<Customer> iterator = customerList.iterator(); while (iterator.hasNext()){ Customer customer = iterator.next(); DynamicDataSourceHolder.setConsistentHashKey(customer.getIdcardNo()); //设置用于一致性hash计算的key,以此来动态修改操作的数据源 customerMapper.insertSelective(customer); //执行数据库插入操作 message += "<p>"+customer.getName()+" , "+customer.getIdcardNo()+" , "+DynamicDataSourceHolder.getDataSourceKey()+" , "+DynamicDataSourceHolder.getDataSourceFinalKey(); } return message; } /** * 从主库库中查询客户信息 */ @AnnotationDBSourceKey("master") public String queryCustomerFromMater() { return queryData(); } /** * 从slave库中查询客户信息 */ @AnnotationDBSourceKey("slave") public String queryCustomer() { return queryData(); }
/** * 将查询数据的业务抽离成公共方法 */ public String queryData(){ String message = "<p>查询结束:</p>"; message += "<p>查询信息如下:客户姓名 , 身份证号 , 原始数据源 , 最终数据源</p>"; //从数据库中查询数据 Iterator<Customer> iterator = getTenCustomer().iterator(); while (iterator.hasNext()){ Customer customer = iterator.next(); String idcardNo = customer.getIdcardNo(); CustomerExample example = new CustomerExample(); example.createCriteria().andIdcardNoEqualTo(idcardNo); DynamicDataSourceHolder.setConsistentHashKey(idcardNo); //设置用于一致性hash计算的key,以此来动态修改操作的数据源 customerMapper.selectByExample(example); //执行数据库插入操作 message += "<p>"+customer.getName()+" , "+customer.getIdcardNo()+" , "+DynamicDataSourceHolder.getDataSourceKey()+" , "+DynamicDataSourceHolder.getDataSourceFinalKey(); } return message; } }
步骤六:编写Controller和客户端代码
package com.newbie.controller; import com.newbie.domain.Customer; import com.newbie.service.IConsistentHashService; import org.springframework.stereotype.Controller; import org.springframework.ui.Model; import org.springframework.web.bind.annotation.RequestMapping; import javax.annotation.Resource; @Controller public class ConsistentHashController { @Resource IConsistentHashService consistentHashService; /** * 插入十条数据,默认姓名为"简小六" */ @RequestMapping("/addCustomer") public String addCustomer(Model model) { String message = consistentHashService.addConstomer(); model.addAttribute("message", message); return "showQuery"; } /** * 从主库库中查询客户信息 */ @RequestMapping("queryCustomerFromMater") public String queryCustomerFromMater(Model model){ String message = consistentHashService.queryCustomerFromMater(); model.addAttribute("message", message); return "showQuery"; } /** * 从slave库中查询客户数据 */ @RequestMapping("queryCustomer") public String queryCustomer(Model model){ String message = consistentHashService.queryCustomer(); model.addAttribute("message", message); return "showQuery"; } }
<%@ page contentType="text/html;charset=UTF-8" language="java" %>
<html>
<head>
<title>测试:分库分表逻辑</title>
</head>
<body>
<h2>练习二:一致性hash算法分库方案</h2>
<h3> </h3>
<a href="addCustomer"> 插入十条数据,姓名为"简小六" </a><br/><br/>
<a href="queryCustomerFromMater">从master库中查询客户数据</a><br/><br/>
<a href="queryCustomer">从slave库中查询客户数据</a>
<br/><hr/><hr><hr/><br/>
</body>
</html>
步骤七:运行代码,测试结果

(1)插入五条数据,姓名为“简小六”,结果如下图所示:

(2)从master库中随机查询五条数据,结果如下图所示:

(3)从slave库中随机查询五条数据,结果如下图所示:
