我们在爬取网站的时候,都会遵守 robots 协议,在爬取数据的过程中,尽量不对服务器造成压力。但并不是所有人都这样,网络上仍然会有大量的恶意爬虫。对于网络维护者来说,爬虫的肆意横行不仅给服务器造成极大的压力,还意味着自己的网站资料泄露,甚至是自己刻意隐藏在网站的隐私的内容也会泄露,这也就是反爬虫技术存在的意义。
开始
先从最基本的requests开始。requests是一常用的http请求库,它使用python语言编写,可以方便地发送http请求,以及方便地处理响应结果。这是一段抓取敢闯网内容的代码。
import requests
from lxml import etree
url = 'https://www.darecy.com/'
data = requests.get(url).text
s=etree.HTML(data)
film=s.xpath('//*[@id="content"]/h1/span[1]/text()')
print(film)
这就是最简单的完整的爬虫操作,通过代码发送网络请求,然后解析返回内容,分析页面元素,得到自己需要的东西。
这样的爬虫防起来也很容易。使用抓包工具看一下刚才发送的请求,再对比一下浏览器发送的正常请求。可以看到,两者的请求头差别非常大,尤其requests请求头中的user-agent,赫然写着python-requests。这就等于是告诉服务端,这条请求不是真人发的。服务端只需要对请求头进行一下判断,就可以防御这一种的爬虫。

当然requests也不是这么没用的,它也支持伪造请求头。以user-agent为例,对刚才的代码进行修改,就可以很容易地在请求头中加入你想要加的字段,伪装成真实的请求,干扰服务端的判断。

import requests
from lxml import etree
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = { 'User-Agent' : user_agent }
url = 'https://www.darecy.com/'
data = requests.get(url,headers=headers).text
s=etree.HTML(data)
film=s.xpath('//*[@id="content"]/h1/span[1]/text()')
print(film)
提高
现阶段,就网络请求的内容上来说,爬虫脚本已经和真人一样了,那么服务器就要从别的角度来进行防御。
有两个思路,第一个,分析爬虫脚本的行为模式来进行识别和防御。
爬虫脚本通常会很频繁的进行网络请求,针对这种行为模式,服务端就可以对访问的 IP 进行统计,如果单个 IP 短时间内访问超过设定的阈值,就给予封锁。这确实可以防御一批爬虫,但是也容易误伤正常用户,并且爬虫脚本也可以绕过去。
这时候的爬虫脚本要做的就是ip代理,每隔几次请求就切换一下ip,防止请求次数超过服务端设的阈值。设置代理的代码也非常简单。
import requests
proxies = {
"http" : "http://108.108.108.108:8899" # 代理ip
}
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = { 'User-Agent' : user_agent }
url = 'https://www.darecy.com/'
res = requests.get(url = http_url, headers = headers, proxies = proxies)
第二个思路,通过做一些只有真人能做的操作来识别爬虫脚本。最典型的就是以12306为代表的验证码操作。
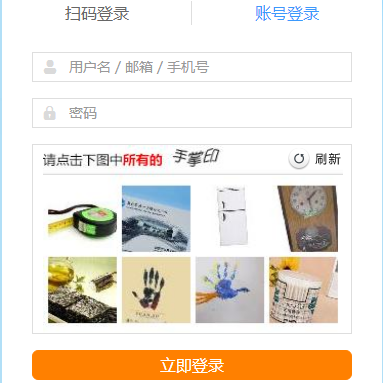
增加验证码是一个既古老又相当有效果的方法,能够让很多爬虫望风而逃。当然这也不是万无一失的。经过多年的发展,用计算机视觉进行一些图像识别已经不是什么新鲜事,训练神经网络的门槛也越来越低,并且有许多开源的计算机视觉库可以免费使用。

再专业一点的话,还可以加上一些图像预处理的操作,比如降噪和二值化,提高验证码的识别准确率。当然要是验证码原本的干扰线, 噪点都比较多,甚至还出现了人类肉眼都难以辨别的验证码,计算机识别的准确度也会相应下降一些。但这种方法对于真实的人类用户来说实在是太不友好了,属于是杀敌一千自损八百的做法。
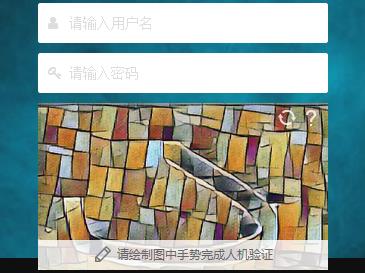
进阶
验证码的方法虽然防爬效果好,开发人员在优化验证操作的方面也下了很多工夫。如今,很多的人机验证操作已经不再需要输入验证码,有些只要一下点击就可以完成,有些甚至不需要任何操作,在用户不知道的情况下就能完成验证。这里其实包含了不同的隐形验证方法。

有些则更加高级一些,通过检测出用户的浏览习惯,比如用户常用 IP 或者鼠标移动情况等,然后自行判断人机操作。这样就用一次点击取代了繁琐的验证码,而且实际效果还更好。
