优化应贯穿整个产品开发周期中,比如编写复杂SQL时查看执行计划,安装MySQL服务器时尽量合理配置(见过太多完全使用默认配置安装的情况),根据应用负载选择合理的硬件配置等。
1、性能分析
性能分析包含多方面:CPU、Memory、磁盘/网络IO、MySQL服务器本身等。
1.1 操作系统分析
常规的操作系统分析,在Linux中通常包含一些性能监控命令,如top、vmstat、iostat、strace、iptraf等。
1、内存:内存是大项,高查询消耗大量的查询缓存,内存必须足够,并且给系统本身要预留一些。
2、磁盘:配备高速磁盘+RAID会有更好的读写速度,并且SSD成本逐渐降低,升级成本会在可接受范围。
3、网络:目前市场上千兆万兆网卡已很常见。
4、CPU:虽然很多情况下CPU用不完,但也不能让它成为瓶颈。
生产环境的MySQL多数情况部署在Linux系统中,Linux系统本身可以优化的配置并不多。硬件的选型是复杂,涉及计算机组成的原理性知识,需要额外了解。
1.2 MySQL服务性能分析
MySQL服务器的性能通常通过监控命令查看系统工作状态,确定哪些因素成为瓶颈。
1.2.1 SHOW GLOBAL STATUS
显示了目前MySQL的工作状态,包含很多参数,下面对一些参数进行说明,其余的参考官方说明:
====================================
1. Aborted_clients
如果该值随时间增加,检查是否优雅关闭连接,检查max_allowed_packet配置变量是否被超过导致强制中断。
2. Aborted_connections
接近于0,检查网络问题,如果有少量是正常的,比如鉴权失败等。
3. Binlog_cache_disk_use和Binlog_cache_use
大部分事务应该在缓冲中进行,如果disk cache很大,可考虑增加内存缓存。
4. Bytes_recevied和Bytes_sent
如果值很大,检查是否查询超过需要的数据。
5. Com_*
尽量让如Com_rollback这些不常见的变量超过预期,用innotop检查。
6. Create_tmp_tables
优化查询降低该值。
7. Handler_read_rnd_next
Handler_read_rnd_next / Handler_read_rnd显示全表扫面大致平均值,如果很大,只能优化查询。
8. Open_files
不应该接近于open_files_limit,如果接近就应该适当增加open_files_limit。
9. Qcache_*
查询缓存相关。
10. Select_full_join
全联接无索引联接,尽量避免,优化查询。
11. Select_full_range_join
值过高说明使用了范围查询联接表,范围查询比较慢,可优化。
12. Sort_meger_passes
如果值较大可考虑增加sort_buffer_size,查明是那个查询导致使用文件排序。
13. Table_locks_waited
表被锁定导致服务器锁等待,InnoDB的行锁不会使得该变量增加,建议开启慢查询日志。
14. Threads_created
如果值在增加,可考虑增加thread_cache_size。
====================================
1.2.2 SHOW ENGINE INNODB STATUS
暂时的数据包含了太多InnoDB核心信息,并且需要比较深的了解InnoDB引擎工作原理,这里不做过多说明,请查阅针对此的专项文档。
注: 通常包含SEMAPHORES、TRANSACTIONS、FILE I/O、LOG、BUFFER POOL AND MEMORY等一些详细值,有些参数是上一次执行以来的平均值,所以建议隔一段时间再打印一次得到这段时间的统计,有点类似iostat的统计磁盘平均读写一样。
1.2.3 开启慢查询日志配置
排查导致MySQL运行缓慢的问题SQL,开启慢查询日志配置,可能有很有帮助:
slow_query_log=1 slow_query_log_file=/YOUR_DIR/mysql_slow.log
配合慢查询日志分析工具(如mysqlsla)
2、查询性能优化
一般来说在编写SQL时,注意查询是否能使用到索引,是否在大表中或者高频率查询中引起全表扫描,这些主要通过经验分析配合execution plan得到比较理想的查询消耗。
2.1 查询基础
了解查询过程,才能知道哪些步骤可能出现瓶颈,execution plan结果也会有所体现,MySQL查询的一般过程:
1. Client往服务器发送查询指令。
2. 服务器查询缓存,如果存在则直接返回,否则下一步。
3. 服务器解析、预处理和优化查询,生成执行计划。
4. 执行引擎调用存储引擎API执行查询。
5. 服务器将结果返回至客户端。
用图表示如下:
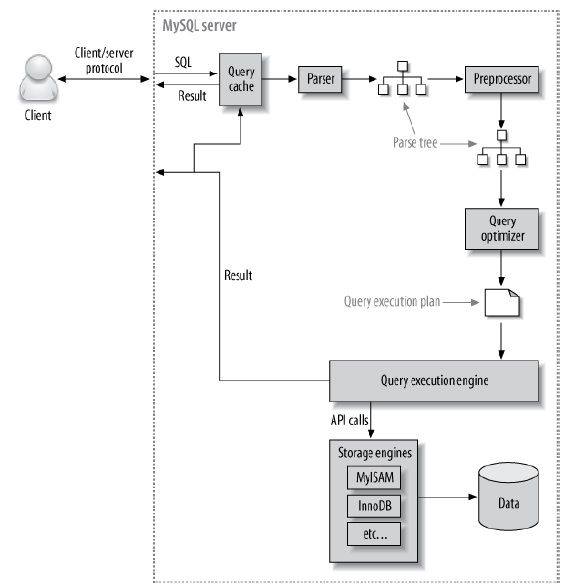
解析与预处理过程:
- 解析器将查询分解后构造解析树,进行语法解析与验证查询,检查SQL是否有效。
- 预处理器解析语义:如检查表和列是否存在,是否存在歧义等。
- 预处理器检查权限。
查询优化器:
该过程比较复杂,将解析树的结果变成执行计划,优化器的任务是寻找最好的方式(但并不是总能选择最好的方案),MySQL使用基于开销的优化器,预测不同执行计划的开销。
- MySQL不考虑不受它控制的开销,如用户存储过程与用户自定义的函数
- 不考虑正在运行的其他查询
2.2 优化数据访问 (这一点很重要)
1. 应用程序是否获取超过需要的数据量?(PS: 多次遇到过查询表所有数据然后再程序中只读取10行之类的代码)
2. MySQL 服务器是否分析了超过需要的行?数据是否没有在存储引擎层被过来掉?(Using index , Using where)
典型的错误如下:
1. 提取超过需要的行,然后在程序中只要一部分 (应该使用limit限制数据量)。
2. 多表join提取所有的列 (应该只读取需要的列)。
3. 提取所有的列(提取不需要的列可能导致优化索引失效,增加磁盘IO,浪费内存等, 但如果是知道这个影响并利用查询缓存,简化设计等也是可以考虑的)。
访问类型:
Full Table Scan > Index Scan > Range Scan > Unique Index Lookup > Constant.
访问速度以此递增。
对于使用where语句来过滤数据的话,最好到最坏的情况是:
1. 对索引查找用where来消除不匹配的数据行,在存储引擎层。
2. 使用覆盖索引 (Extra 为Using Index) 来避免访问行,取得索引数据后过滤行,发生在MySQL服务器层,但不需要读取行数据。
3. 从表中查询数据,然后过滤 (Using Where), 发生在服务器端并且要读取行数据。
后面会针对执行计划结果做详细介绍。
2.3 关于执行计划
执行计划结果样例如下图(也可用其他的可视化工具,如mysql workbench):
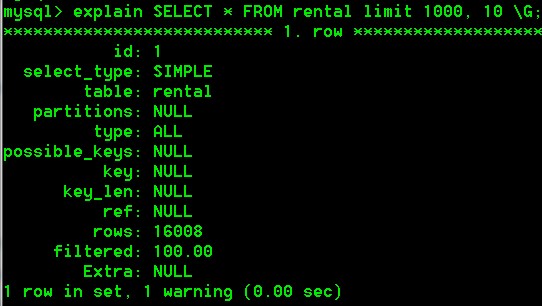
所代表的含义可在官方文档中找到详细说明 ( https://dev.mysql.com/doc/refman/5.5/en/explain-output.html ),
这里说明一些比较重要的结果:
TYPE字段的值:
前面所说的访问速度依次递增就和这个有关:
Full Table Scan > Index Scan > Range Scan > Unique Index Lookup > Constant.
这里列出一些常见的说明:
1、const: 最多匹配一行, 如 SELECT * FROM rental where rental_id=1。
2、eq_ref: 读取的行依次匹配前一个表。
3、ref: 连接仅使用左索引或者索引不是PRIMARY或UNIQUE(或者说得到的不是一行的结果),如果得到的几行数据,这是个比较好的类型。
4、range: 使用索引的范围扫描,如使用了 =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, IN()等条件。
5、index: 除了索引树被扫描之外,索引连接类型与ALL相同。这有两种方式:
**************
1. 如果索引是查询的覆盖索引,并满足表中所需的所有数据,则仅扫描索引树。 在这种情况下,Extra列为Using index。 仅索引扫描通常比ALL更快,因为索引的大小通常小于表数据。
2. 使用索引来执行全表扫描,以按索引顺序查找数据行。 在Extra列张则没有Using index,这种情况与ALL的区别是ALL是按行扫描。
**************
6、ALL: 全表扫描,比较糟糕 (但有时候数据比较少的情况下,MySQL会直接进行全表扫描读取数据,效率更高)。
2.4 优化特定的查询
查询优化的一个办法是迁移旧数据,腾出内存空间重新平衡索引结构,使得更快的查询速度,很多应用保留半年或三个月的数据都能满足需求,对于旧数据,额外提供平台访问或者在应用层做路由。
2.4.1 优化COUNT (遇到过一知半解的使用,导致想优化却适得其反)
COUNT有两种不同的工作方式:统计值的数量和统计行的数量。
值是一个非空(Non-NULL)的表达式(NULL则表示没有值),如果在COUNT()中定义了列名或其他表达式,COUNT则会统计这个表达式有值(Non-NULL)的次数。
COUNT另外一种工作方式就是统计行数,当MySQL知道括号中的表达式不会为NULL的时候,则使用这种方式,COUNT(*)是个例子,它不会展开成所有列,则是忽略所以的列并统计。
2.4.2 优化limit和offset
偏移量很大的查询代价很高,如LIMIT 10000, 10, 则会产生10010数据,然后只截取10行。解决办法:
1. 限制分页能读取的数据页数。
2. 可考虑使用覆盖索引,如 select id, name, description from book limit 100,10;
在ID上有索引改进为:select id, name, description from book inner join (select id from book limit 100, 10) as b;