架构及简介
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
Scrapy 使用了 Twisted(其主要对手是Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
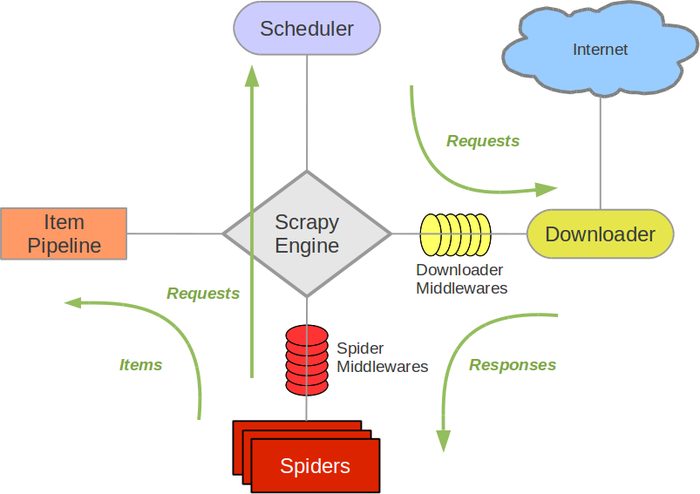
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
开发流程
开发一个简单爬虫步骤:
- 新建项目
scrapy startproject demo
-
编写spider
- 种子url (请求)
- 解析方法
-
编写item
结果数据模型 -
持久化
编写pipelines
生成目录介绍
scrapy.cfg :项目的配置文件
mySpider/ :项目的Python模块,将会从这里引用代码
mySpider/items.py :项目的目标文件
mySpider/pipelines.py :项目的管道文件
mySpider/settings.py :项目的设置文件
mySpider/spiders/ :存储爬虫代码目录
使用命令创建爬虫类
scrapy genspider gitee "gitee.com"
解析
通常我们解析都会涉及到 xpath csspath 正则,有的时候可能还有jsonpath(python中json访问基本不用使用复杂的jsonpath,字典访问就可以)
scrapy 内置xpath、csspath以及 正则支持
Selector
而解析器本身也可以单独使用
- xpath()
- extract_first()
- extract() #返回一个列表
- 索引访问,因为scrapy.selector.unified.SelectorList继承list,可以通过索引访问
from scrapy import Selector
if __name__ == '__main__':
body = """<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<p>hello</p>
<p class="big">hello</p>
</body>
</html>"""
s = Selector(text=body)
title=s.xpath("//title/text()").extract_first();#抽取
print(title)
#Title
pe = s.xpath("//p")
print(s.xpath("//p").extract())
#['<p>hello</p>', '<p class="big">hello</p>']
print(pe)
#[<Selector xpath='//p' data='<p>hello</p>'>, <Selector xpath='//p' data='<p class="big">hello</p>'>]
print(type(pe))
#<class 'scrapy.selector.unified.SelectorList'>
print(type(pe[0])) #通过索引访问
#<class 'scrapy.selector.unified.Selector'>
print(type(pe.pop()))
#<class 'scrapy.selector.unified.Selector'>
p=s.xpath("//p").extract_first()
print(p)
- css()
css选择器我们::text选择内容,用::attr() 选择属性
print(s.css("title").extract_first())
print(s.css("title::text").extract_first())
print(s.css("title::text").extract())
print(s.css("p.big::text").extract_first())
print(s.css("p.big::attr(class)").extract_first())
# <title>Title</title>
# Title
# ['Title']
# hello big
# big
- css()和xpath()混用
scrapy.selector.unified.SelectorListscrapy.selector.unified.Selector本身有css和xpath方法,所以可以组合使用
print(s.xpath("//body").css("p.big").extract_first())
print(s.css("body").xpath("//p[@class='big']").extract_first())
# <p class="big">hello big </p>
# <p class="big">hello big </p>
- re()和re_first()
scrapy.selector.unified.SelectorListscrapy.selector.unified.Selector拥有re()方法,支持通过正则来过滤
print(s.xpath("//p/text()").re_first("big"))
print(type(s.xpath("//p/text()").re("big")))
# big
# <class 'list'>
但re()返回列表,.re_first返回str,所以不能再继续调用其他的选择方法
在爬虫中使用解析器
response对象已经
class GiteeSpider(scrapy.Spider):
name = 'gitee'
allowed_domains = ['gitee.com']
start_urls = ['https://gitee.com/haimama']
def parse(self, response):
print(type(response))
t=response.xpath("//title/text()").extract_first()
print(t)
##启动爬虫执行后的结果
# 执行结果省略日志
# <class 'scrapy.http.response.html.HtmlResponse'>
# 码马 (haimama) - Gitee
response对象类型为 scrapy.http.response.html.HtmlResponse,该类继承TextResponse 。拥有xpath()和css()方法如下
所以response 可以直接使用前文中的Selector 的方式来解析
def xpath(self, query, **kwargs):
return self.selector.xpath(query, **kwargs)
def css(self, query):
return self.selector.css(query)
配置文件
settings.py是爬虫的配置文件,要正常启动爬虫的话,一定注意将robo协议限制 修改为 ROBOTSTXT_OBEY = False
其他相关配置,我们下节再介绍
启动爬虫
在爬虫目录编写run.py方法,添加如下脚本,这样就可以直接执行爬虫了。如果命令行执行的话scrapy crawl gitee。其中gitee为爬虫名,对应GiteeSpider中的name字段
# coding: utf-8
from scrapy import cmdline
if __name__ == '__main__':
cmdline.execute("scrapy crawl gitee".split())
# scrapy crawl gitee
完整参考代码 https://gitee.com/haimama/scrapy_demo001
xpath参考 我的博客python使用xpath