2.1 Hadoop概论
创始人:Doug Cutting
1.简介:
开源免费;
操作简单,极大降低使用的复杂性;
Hadoop是Java开发的;
在Hadoop上开发应用支持多种编程语言、不限于Java;
Hadoop两大核心:HDFS+MapReduce
HDFS:海量数据存储
MapReduce:海量数据的处理
2.起源:
原本是文本搜索库,模仿谷歌的搜索引擎;
融入了谷歌相关技术:分布式文件系统GFS;分布式并行编程框架MapReduce;
3.成名史:数据排序 的傲人成绩
4.特性:
1.高可靠性
2.高效性
3高可扩展性
4.高容错性
5.低成本
6.运行在Linux平台上
7.支持多种编程语言
5.应用现状:
例如:Facebook

2.2 Hadoop项目结构
HDFS:分布式文件存储
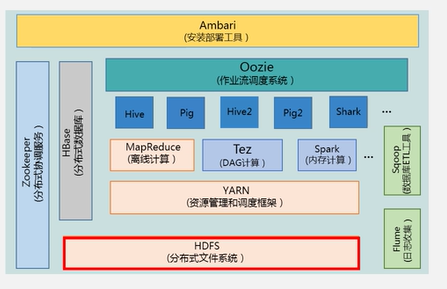
MapReduce:数据处理,基于磁盘
Spark(性能比MapReduce高一个数量级):数据处理,基于内存
Hive:数据仓库;做决策分析;支持SQL语句(把SQL语句转成MapReduce作业,再去执行);
Pig:流数据处理,轻量级数据;提供类似SQL的查询语句Pig Latin;
Oozie:作业流调度系统
Zookeeper:分布式协调服务;分布式锁;集群管理;
HBase:列族数据库,随机读写
Flume:日志收集
Sqoop:数据导入导出,关系型数据库到HDFS、HBase、Hive互导
Ambari:快速部署工具
2.3 Hadoop安装与使用

1.Linux选择:
选择Linux版本:Ubuntu
内存选择:看电脑。内存大于4G,选择64位
2.系统安装 虚拟机还是双系统:
看电脑配置
电脑比较新,装虚拟机
3.关于Linux基础知识
1.Shell:命令解析器
2.sudo命令:权限管理机制,管理员可以授权普通用户去执行一些需要root权限执行的操作
3.输入密码:看不见自己输入的密码
4.输入法中英文切换:使用“shift”键
5.Ubuntu终端赋值黏贴快捷键:ctrl+shift+V
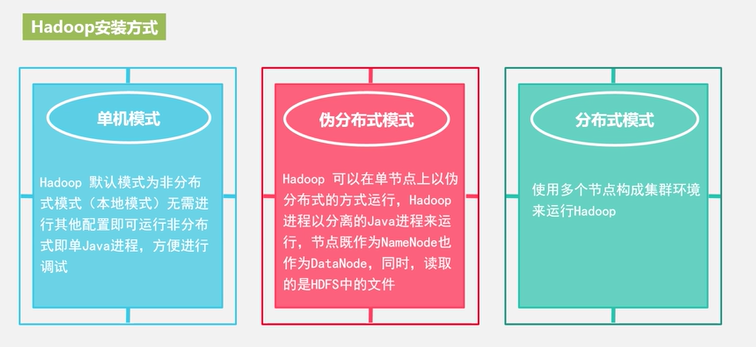
4.安装方式:
单机模式,伪分布式模式,分布式模式
5.创建虚拟机:
1.材料与工具:虚拟机软件与系统映像文件
2.确认系统版本:

2.4 Hadoop集群的部署与使用
考虑HDFS和MapReduce
(后补)
慕课链接:https://www.icourse163.org/learn/XMU-1002335004?tid=1003965001#/learn/content