先来一段到处都有的原理(出处到处都有,就不注明了)
Streaming和Kafka整合有两种方式--Receiver和Direct,简单理解为:Receiver方式是通过zookeeper来连接kafka队列,Direct方式是直接连接到kafka的节点上获取数据
Receiver:
1、Kafka中topic的partition与Spark中RDD的partition是没有关系的,因此,在KafkaUtils.createStream()中,提高partition的数量,只会增加Receiver的数量,也就是读取Kafka中topic partition的线程数量,不会增加Spark处理数据的并行度。
2、可以创建多个Kafka输入DStream,使用不同的consumer group和topic,来通过多个receiver并行接收数据。
3、如果基于容错的文件系统,比如HDFS,启用了预写日志机制,接收到的数据都会被复制一份到预写日志中。因此,在KafkaUtils.createStream()中,设置的持久化级别是StorageLevel.MEMORY_AND_DISK_SER。
Direct:
1、简化并行读取:如果要读取多个partition,不需要创建多个输入DStream,然后对它们进行union操作。Spark会创建跟Kafka partition一样多的RDD partition,并且会并行从Kafka中读取数据。所以在Kafka partition和RDD partition之间,有一个一对一的映射关系。
2、高性能:如果要保证零数据丢失,在基于receiver的方式中,需要开启WAL机制。这种方式其实效率低下,因为数据实际上被复制了两份,Kafka自己本身就有高可靠的机制会对数据复制一份,而这里又会复制一份到WAL中。而基于direct的方式,不依赖Receiver,不需要开启WAL机制,只要Kafka中作了数据的复制,那么就可以通过Kafka的副本进行恢复。
3、一次且仅一次的事务机制:基于receiver的方式,是使用Kafka的高阶API来在ZooKeeper中保存消费过的offset的。这是消费Kafka数据的传统方式。这种方式配合着WAL机制可以保证数据零丢失的高可靠性,但是却无法保证数据被处理一次且仅一次,可能会处理两次。因为Spark和ZooKeeper之间可能是不同步的。基于direct的方式,使用kafka的简单api,Spark Streaming自己就负责追踪消费的offset,并保存在checkpoint中。Spark自己一定是同步的,因此可以保证数据是消费一次且仅消费一次。由于数据消费偏移量是保存在checkpoint中,因此,如果后续想使用kafka高级API消费数据,需要手动的更新zookeeper中的偏移量
本来说网上搜一搜就解决了代码问题,但是大部分都是Spark1.X 的,对应的Kafka的 createDirectStream 的传参方式不一样(也可能是我学的太浅),所以仿照spark1.X的写了个。
接下来直接上代码
package com.kafka
import scala.collection.JavaConversions._
import org.apache.curator.framework.CuratorFrameworkFactory
import org.apache.curator.retry.ExponentialBackoffRetry
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.kafka.common.TopicPartition
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable
object KafkaZookeeperCheckPoint {
// ZK client
val client = {
val client = CuratorFrameworkFactory
.builder
.connectString("bigdata:2181,bigdata:2182,bigdata:2183")
.retryPolicy(new ExponentialBackoffRetry(1000, 3))
.namespace("mykafka")
.build()
client.start()
client
}
// offset 路径起始位置
val Globe_kafkaOffsetPath = "/kafka/offsets"
// 路径确认函数 确认ZK中路径存在,不存在则创建该路径
def ensureZKPathExists(path: String)={
if (client.checkExists().forPath(path) == null) {
client.create().creatingParentsIfNeeded().forPath(path)
}
}
// 保存 新的 offset
def storeOffsets(offsetRange: Array[OffsetRange], groupName:String) = {
for (o <- offsetRange){
val zkPath = s"${Globe_kafkaOffsetPath}/${groupName}/${o.topic}/${o.partition}"
// 向对应分区第一次写入或者更新Offset 信息
println("---Offset写入ZK------
Topic:" + o.topic +", Partition:" + o.partition + ", Offset:" + o.untilOffset)
client.setData().forPath(zkPath, o.untilOffset.toString.getBytes())
}
}
def getFromOffset(topic: Array[String], groupName:String):(Map[TopicPartition, Long], Int) = {
// Kafka 0.8和0.10的版本差别,0.10 为 TopicPartition 0.8 TopicAndPartition
var fromOffset: Map[TopicPartition, Long] = Map()
val topic1 = topic(0).toString
// 读取ZK中保存的Offset,作为Dstrem的起始位置。如果没有则创建该路径,并从 0 开始Dstream
val zkTopicPath = s"${Globe_kafkaOffsetPath}/${groupName}/${topic1}"
// 检查路径是否存在
ensureZKPathExists(zkTopicPath)
// 获取topic的子节点,即 分区
val childrens = client.getChildren().forPath(zkTopicPath)
// 遍历分区
val offSets: mutable.Buffer[(TopicPartition, Long)] = for {
p <- childrens
}
yield {
// 遍历读取子节点中的数据:即 offset
val offsetData = client.getData().forPath(s"$zkTopicPath/$p")
// 将offset转为Long
val offSet = java.lang.Long.valueOf(new String(offsetData)).toLong
// 返回 (TopicPartition, Long)
(new TopicPartition(topic1, Integer.parseInt(p)), offSet)
}
println(offSets.toMap)
if(offSets.isEmpty){
(offSets.toMap, 0)
} else {
(offSets.toMap, 1)
}
}
// if (client.checkExists().forPath(zkTopicPath) == null){
//
// (null, 0)
// }
// else {
// val data = client.getData.forPath(zkTopicPath)
// println("----------offset info")
// println(data)
// println(data(0))
// println(data(1))
// val offSets = Map(new TopicPartition(topic1, 0) -> 7332.toLong)
// println(offSets)
// (offSets, 1)
// }
//
// }
def createMyZookeeperDirectKafkaStream(ssc:StreamingContext, kafkaParams:Map[String, Object], topic:Array[String],
groupName:String ):InputDStream[ConsumerRecord[String, String]] = {
// get offset flag = 1 表示基于已有的offset计算 flag = 表示从头开始(最早或者最新,根据Kafka配置)
val (fromOffsets, flag) = getFromOffset(topic, groupName)
var kafkaStream:InputDStream[ConsumerRecord[String, String]] = null
if (flag == 1){
// 加上消息头
//val messageHandler = (mmd:MessageAndMetadata[String, String]) => (mmd.topic, mmd.message())
println(fromOffsets)
kafkaStream = KafkaUtils.createDirectStream(ssc, LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe(topic, kafkaParams, fromOffsets))
println(fromOffsets)
println("中断后 Streaming 成功!")
} else {
kafkaStream = KafkaUtils.createDirectStream(ssc, LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe(topic, kafkaParams))
println("首次 Streaming 成功!")
}
kafkaStream
}
def main(args: Array[String]): Unit = {
val processInterval = 5
val brokers = "bigdata:9092,bigdata:9093,bigdata:9094"
val topics = Array("zkKafka")
val conf = new SparkConf().setMaster("local[2]").setAppName("kafka checkpoint zookeeper")
// kafka params
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> brokers,
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "zk_group",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val ssc = new StreamingContext(conf, Seconds(processInterval))
val messages = createMyZookeeperDirectKafkaStream(ssc, kafkaParams, topics, "zk_group")
messages.foreachRDD((rdd) => {
if (!rdd.isEmpty()){
println("###################:"+rdd.count())
}
// 存储新的offset
storeOffsets(rdd.asInstanceOf[HasOffsetRanges].offsetRanges, "zk_group")
})
ssc.start()
ssc.awaitTermination()
}
}
遇到的几个坑:
一、怎么传入 Offset,这个纠结了好久。后面是看 createDirectStream的源代码看到 consumerStrategy.Subscribe 这个方法还有第三个参数,就是Offset
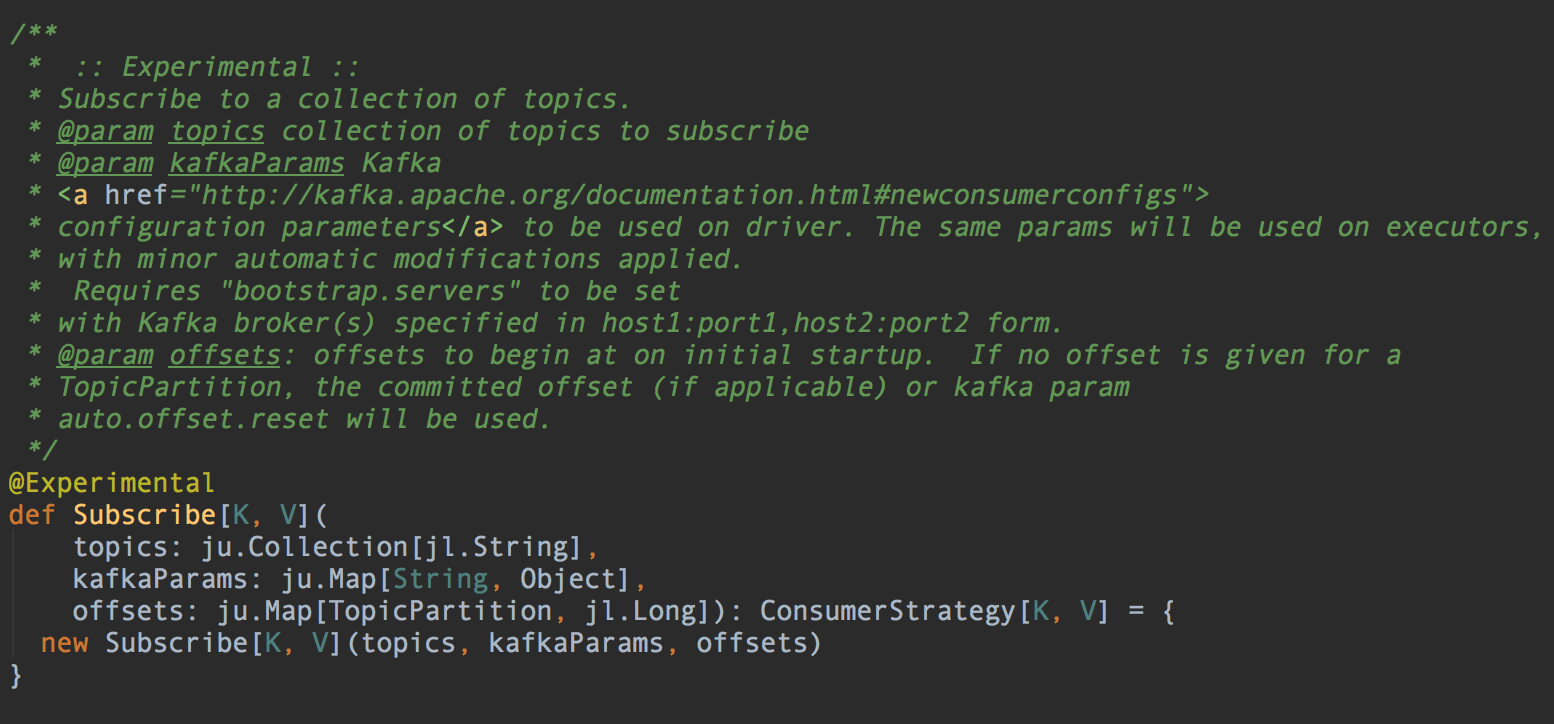
二、无法遍历topic的子节点(分区)
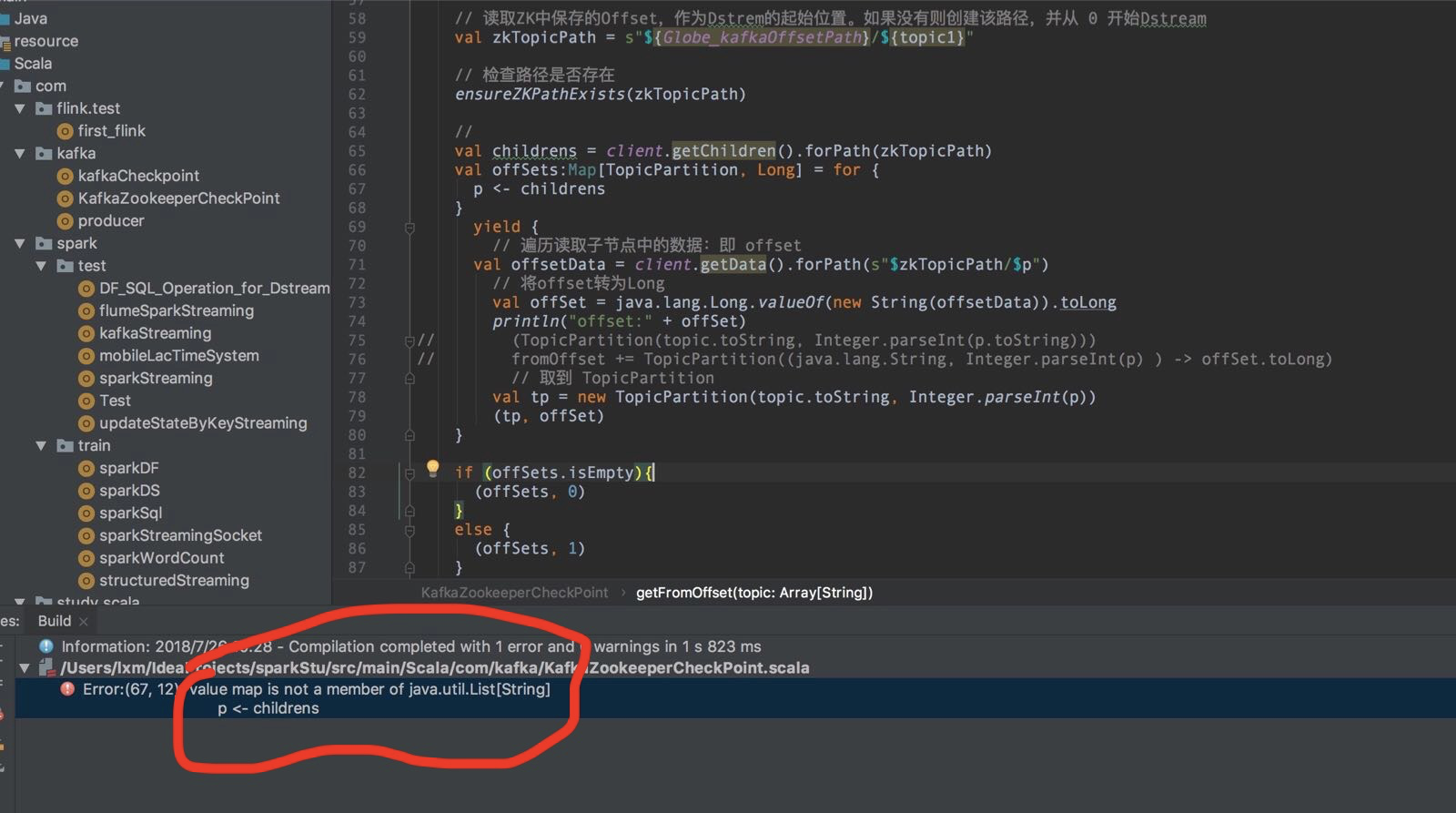
解决方案:
import scala.collection.JavaConversions._
这个是因为个人水平问题,不多说
三、TopicPartition和TopicAndPartition
spark2.X貌似只有TopicPartition了,这个方法也是看源码找到的,搜一下就有,就不截图了。
然后,实例化的时候,因为我的Topic是Array,在实例化TopicPartition的时候,需要先toString。不能TopicPartition(topic.toString, .... ,在里面toString会造成,实例化后的topic显示为乱码(这块不熟,谅解)。
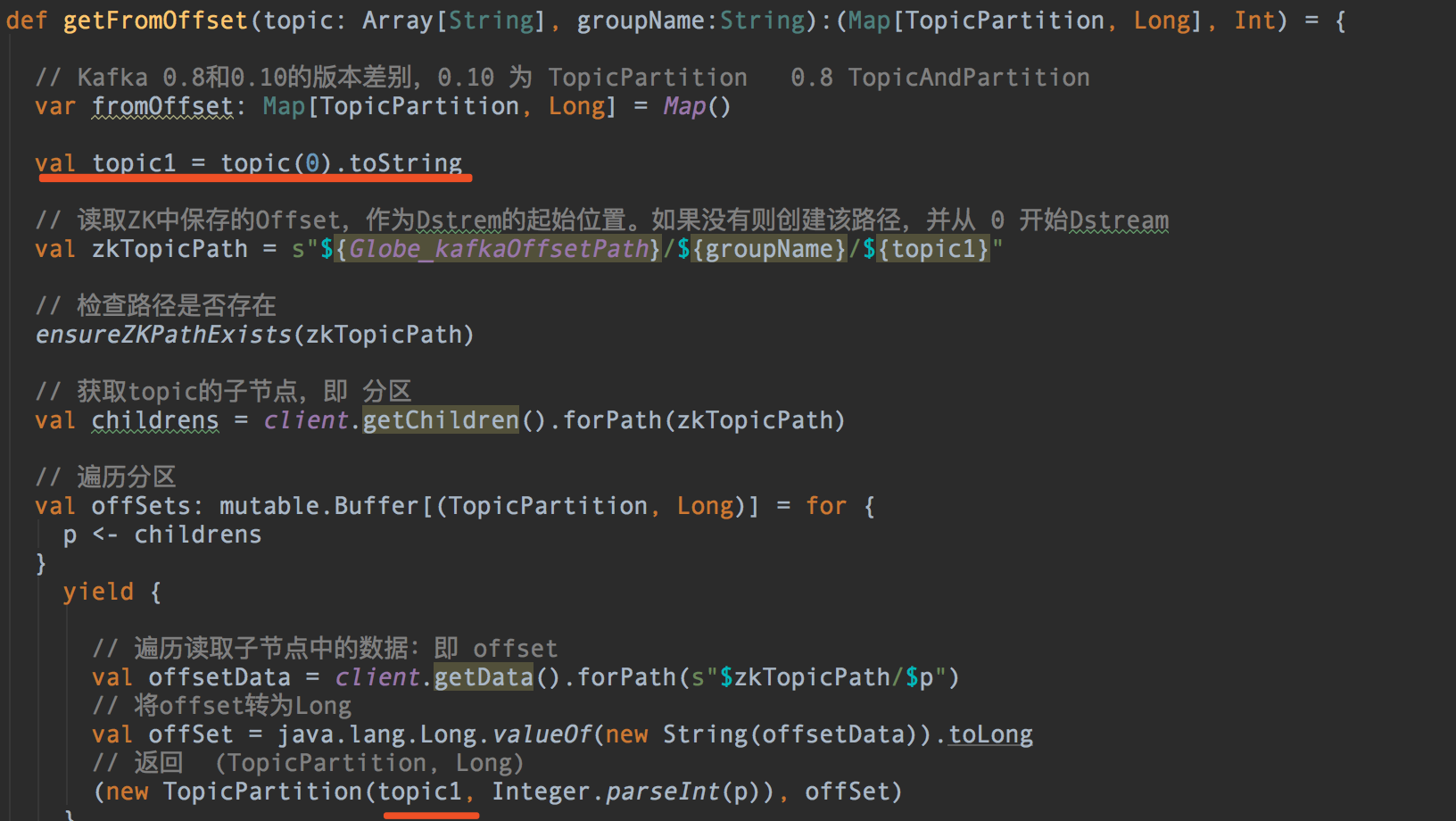
如有问题,欢迎指正~
下次将Offset写入到Hbase的代码和遇到的坑写出来
最后,源码真的是个好东西~