SMON的作用还包括RAC环境中的Instance Recovery,注意虽然Instance Recovery可以翻做实例恢复,但实际上和我们口头所说的实例恢复是不同的。我们口头语言所说的实例恢复很大程度上是指Crash Recovery崩溃恢复,Instance Recovery与Crash Recovery是存在区别的:针对单实例(single instance)或者RAC中所有节点全部崩溃后的恢复,我们称之为Crash Recovery。而对于RAC中的某一个节点失败,存活节点(surviving instance)试图对失败节点线程上redo做应用的情况,我们称之为Instance Recovery。对于Crash Recovery更多的内容可见
<还原真实的cache recovery>一文。
现象
Instance Recovery期间分别存在cache recovery和ges/gcs remaster2个recovery stage,注意这2个舞台的恢复是同时进行的。cache recovery的主角是存活节点上的SMON进程,SMON负责分发redo给slave进程。而实施ges/gcs remaster的是RAC专有进程LMON。
整个Reconfiuration的过程如下图:
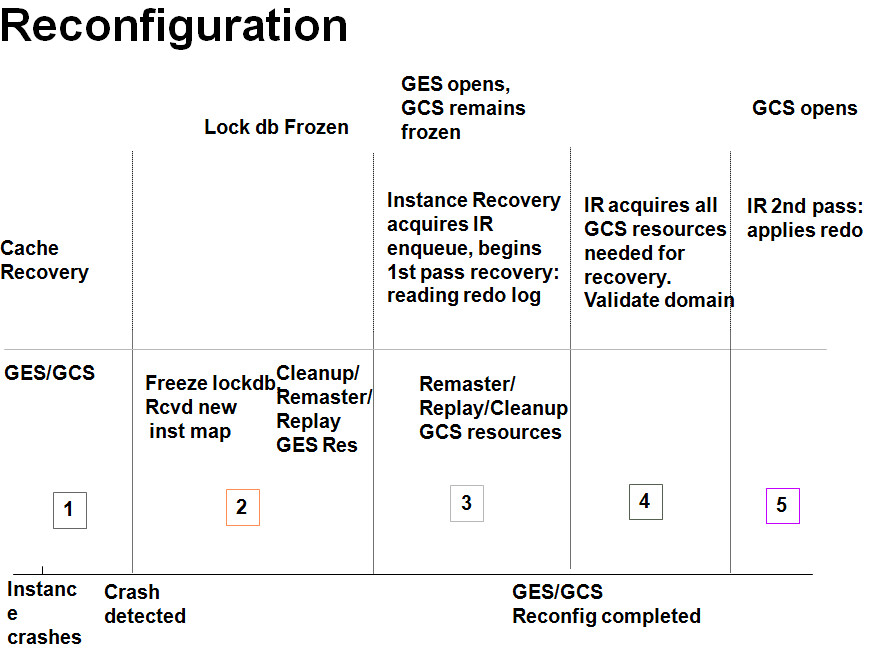
注意以上Crash Detected时数据库进入部分可用(Partial Availability)状态,从Freeze Lockdb开始None Availability,到IR applies redo即前滚时转换为Partial Availability,待前滚完成后会实施回滚,但是此时数据库已经进入完全可用(Full Availability)状态了,如下图:
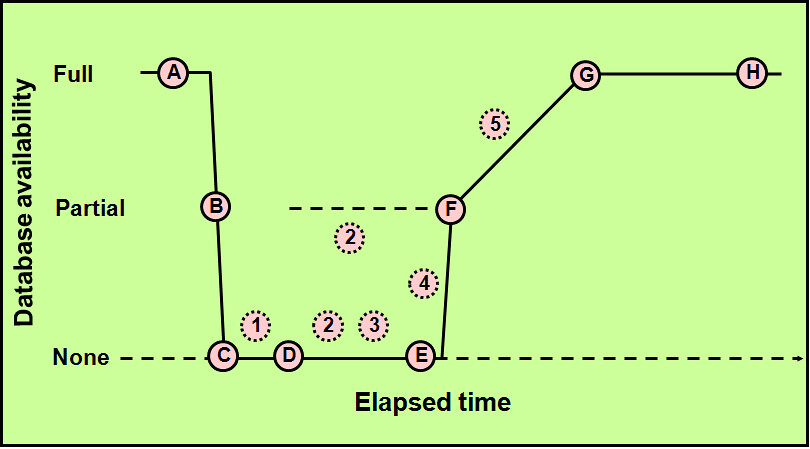
| The graphic illustrates the degree of database availability during each step of Oracle instance recovery:
A. Real Application Clusters is running on multiple nodes.
B. Node failure is detected.
C. The enqueue part of the GRD is reconfigured; resource management is redistributed to the surviving nodes. This operation occurs relatively quickly.
D. The cache part of the GRD is reconfigured and SMON reads the redo log of the failed instance to identify the database blocks that it needs to recover.
E. SMON issues the GRD requests to obtain all the database blocks it needs for recovery. After the requests are complete, all other blocks are accessible.
F. The Oracle server performs roll forward recovery. Redo logs of the failed threads are applied to the database, and blocks are available right after their recovery is completed.
G. The Oracle server performs rollback recovery. Undo blocks are applied to the database for all uncommitted transactions.
H. Instance recovery is complete and all data is accessible.
Note: The dashed line represents the blocks identified in step 2 in the previous slide. Also, the dotted steps represent the ones identified in the previous slide. |
我们来实际观察一下Instance Recovery的过程:
INST 1:
SQL> select * from v$version;
BANNER
--------------------------------------------------------------------------------
Oracle Database 11g Enterprise Edition Release 11.2.0.2.0 - 64bit Production
PL/SQL Release 11.2.0.2.0 - Production
CORE 11.2.0.2.0 Production
TNS for Linux: Version 11.2.0.2.0 - Production
NLSRTL Version 11.2.0.2.0 - Production
SQL> select * from global_name;
GLOBAL_NAME
--------------------------------------------------------------------------------
www.oracledatabase12g.com
SQL> alter system set event='10426 trace name context forever,level 12' scope=spfile; -- 10426 event Reconfiguration trace event
System altered.
SQL> startup force;
ORACLE instance started.
INST 2:
SQL> shutdown abort
ORACLE instance shut down.
=============================================================
========================alert.log============================
Reconfiguration started (old inc 4, new inc 6)
List of instances:
1 (myinst: 1)
Global Resource Directory frozen
* dead instance detected - domain 0 invalid = TRUE
Communication channels reestablished
Master broadcasted resource hash value bitmaps
Non-local Process blocks cleaned out
LMS 0: 0 GCS shadows cancelled, 0 closed, 0 Xw survived
Set master node info
Submitted all remote-enqueue requests
Dwn-cvts replayed, VALBLKs dubious
All grantable enqueues granted
Post SMON to start 1st pass IR
Instance recovery: looking for dead threads
Beginning instance recovery of 1 threads
parallel recovery started with 2 processes --2 recovery slave
Submitted all GCS remote-cache requests
Post SMON to start 1st pass IR
Fix write in gcs resources
Reconfiguration complete
Started redo scan
Completed redo scan
read 88 KB redo, 82 data blocks need recovery
Started redo application at
Thread 2: logseq 374, block 2, scn 54624376
Recovery of Online Redo Log: Thread 2 Group 4 Seq 374 Reading mem 0
Mem# 0: +DATA/prod/onlinelog/group_4.271.747100549
Mem# 1: +DATA/prod/onlinelog/group_4.272.747100553
Completed redo application of 0.07MB
Completed instance recovery at
Thread 2: logseq 374, block 178, scn 54646382
73 data blocks read, 83 data blocks written, 88 redo k-bytes read
Thread 2 advanced to log sequence 375 (thread recovery)
Redo thread 2 internally disabled at seq 375 (SMON)
ARC3: Creating local archive destination LOG_ARCHIVE_DEST_1: '/s01/arch/2_374_747100216.dbf' (thread 2 sequence 374) (PROD1)
Setting Resource Manager plan SCHEDULER[0x310B]:DEFAULT_MAINTENANCE_PLAN via scheduler window
Setting Resource Manager plan DEFAULT_MAINTENANCE_PLAN via parameter
ARC3: Closing local archive destination LOG_ARCHIVE_DEST_1: '/s01/arch/2_374_747100216.dbf' (PROD1)
2011-06-27 22:19:29.280000 +08:00
Archived Log entry 792 added for thread 2 sequence 374 ID 0x9790ab2 dest 1:
ARC0: Creating local archive destination LOG_ARCHIVE_DEST_1: '/s01/arch/2_375_747100216.dbf' (thread 2 sequence 375) (PROD1)
2011-06-27 22:19:30.336000 +08:00
ARC0: Archiving disabled thread 2 sequence 375
ARC0: Closing local archive destination LOG_ARCHIVE_DEST_1: '/s01/arch/2_375_747100216.dbf' (PROD1)
Archived Log entry 793 added for thread 2 sequence 375 ID 0x9790ab2 dest 1:
minact-scn: Master considers inst:2 dead
==================================================================
===========================smon trace begin=======================
*** 2011-06-27 22:19:28.279
2011-06-27 22:19:28.279849 : Start recovery for domain=0, valid=0, flags=0x0
Successfully allocated 2 recovery slaves
Using 67 overflow buffers per recovery slave
Thread 2 checkpoint: logseq 374, block 2, scn 54624376
cache-low rba: logseq 374, block 2
on-disk rba: logseq 374, block 178, scn 54626382
start recovery at logseq 374, block 2, scn 54624376
Instance recovery not required for thread 1
*** 2011-06-27 22:19:28.487
Started writing zeroblks thread 2 seq 374 blocks 178-185
*** 2011-06-27 22:19:28.487
Completed writing zeroblks thread 2 seq 374
==== Redo read statistics for thread 2 ====
Total physical reads (from disk and memory): 4096Kb
-- Redo read_disk statistics --
Read rate (ASYNC): 88Kb in 0.18s => 0.48 Mb/sec
Longest record: 8Kb, moves: 0/186 (0%)
Longest LWN: 33Kb, moves: 0/47 (0%), moved: 0Mb
Last redo scn: 0x0000.0341884d (54626381)
----------------------------------------------
----- Recovery Hash Table Statistics ---------
Hash table buckets = 262144
Longest hash chain = 1
Average hash chain = 82/82 = 1.0
Max compares per lookup = 1
Avg compares per lookup = 248/330 = 0.8
----------------------------------------------
*** 2011-06-27 22:19:28.489
KCRA: start recovery claims for 82 data blocks
*** 2011-06-27 22:19:28.526
KCRA: blocks processed = 82/82, claimed = 81, eliminated = 1
2011-06-27 22:19:28.526088 : Validate domain 0
**************** BEGIN RECOVERY HA STATS ****************
I'm the recovery instance
smon posted (1278500359646), recovery started 0.027 secs,(1278500359673)
domain validated 0.242 secs (1278500359888)
claims opened 70, claims converted 11, claims preread 0
**************** END RECOVERY HA STATS *****************
2011-06-27 22:19:28.526668 : Validated domain 0, flags = 0x0
*** 2011-06-27 22:19:28.556
Recovery of Online Redo Log: Thread 2 Group 4 Seq 374 Reading mem 0
*** 2011-06-27 22:19:28.560
Completed redo application of 0.07MB
*** 2011-06-27 22:19:28.569
Completed recovery checkpoint
----- Recovery Hash Table Statistics ---------
Hash table buckets = 262144
Longest hash chain = 1
Average hash chain = 82/82 = 1.0
Max compares per lookup = 1
Avg compares per lookup = 330/330 = 1.0
----------------------------------------------
*** 2011-06-27 22:19:28.572 5401 krsg.c
Acquiring RECOVERY INFO PING latch from [krsg.c:5401] IX0
*** 2011-06-27 22:19:28.572 5401 krsg.c
Successfully acquired RECOVERY INFO PING latch IX+
*** 2011-06-27 22:19:28.572 5406 krsg.c
Freeing RECOVERY INFO PING latch from [krsg.c:5406] IX0
*** 2011-06-27 22:19:28.572 5406 krsg.c
Successfully freed RECOVERY INFO PING latch IX-
krss_sched_work: Prod archiver request from process SMON (function:0x2000)
krss_find_arc: Evaluating ARC3 to receive message (flags 0x0)
krss_find_arc: Evaluating ARC0 to receive message (flags 0x0)
krss_find_arc: Evaluating ARC1 to receive message (flags 0xc)
krss_find_arc: Evaluating ARC2 to receive message (flags 0x2)
krss_find_arc: Selecting ARC2 to receive REC PING message
*** 2011-06-27 22:19:28.572 3093 krsv.c
krsv_send_msg: Sending message to process ARC2
*** 2011-06-27 22:19:28.572 1819 krss.c
krss_send_arc: Sent message to ARC2 (message:0x2000)
Recovery sets nab of thread 2 seq 374 to 178 with 8 zeroblks
Retrieving log 4
pre-aal: xlno:4 flno:0 arf:0 arb:2 arh:2 art:4
Updating log 3 thread 2 sequence 375
Previous log 3 thread 2 sequence 0
Updating log 4 thread 2 sequence 374
Previous log 4 thread 2 sequence 374
post-aal: xlno:4 flno:0 arf:3 arb:2 arh:2 art:3
krss_sched_work: Prod archiver request from process SMON (function:0x1)
krss_find_arc: Evaluating ARC3 to receive message (flags 0x0)
krss_find_arc: Selecting ARC3 to receive message
*** 2011-06-27 22:19:28.589 3093 krsv.c
krsv_send_msg: Sending message to process ARC3
*** 2011-06-27 22:19:28.589 1819 krss.c
krss_send_arc: Sent message to ARC3 (message:0x1)
Retrieving log 2
Kicking thread 1 to switch logfile
Retrieving log 4
Retrieving log 3
krss_sched_work: Prod archiver request from process SMON (function:0x1)
krss_find_arc: Evaluating ARC0 to receive message (flags 0x0)
krss_find_arc: Selecting ARC0 to receive message
*** 2011-06-27 22:19:28.599 3093 krsv.c
krsv_send_msg: Sending message to process ARC0
*** 2011-06-27 22:19:28.599 1819 krss.c
krss_send_arc: Sent message to ARC0 (message:0x1)
*** 2011-06-27 22:19:28.599 838 krsv.c
krsv_dpga: Waiting for pending I/O to complete
*** 2011-06-27 22:19:29.304
krss_sched_work: Prod archiver request from process SMON (function:0x1)
krss_find_arc: Evaluating ARC1 to receive message (flags 0xc)
krss_find_arc: Selecting ARC1 to receive message
*** 2011-06-27 22:19:29.304 3093 krsv.c
krsv_send_msg: Sending message to process ARC1
*** 2011-06-27 22:19:29.304 1819 krss.c
krss_send_arc: Sent message to ARC1 (message:0x1)
SMON[INST-TXN-RECO]:about to recover undo segment 11 status:3 inst:2
SMON[INST-TXN-RECO]: mark undo segment 11 as available status:2 ret:0
SMON[INST-TXN-RECO]:about to recover undo segment 12 status:3 inst:2
SMON[INST-TXN-RECO]: mark undo segment 12 as available status:2 ret:0
SMON[INST-TXN-RECO]:about to recover undo segment 13 status:3 inst:2
SMON[INST-TXN-RECO]: mark undo segment 13 as available status:2 ret:0
SMON[INST-TXN-RECO]:about to recover undo segment 14 status:3 inst:2
SMON[INST-TXN-RECO]: mark undo segment 14 as available status:2 ret:0
SMON[INST-TXN-RECO]:about to recover undo segment 15 status:3 inst:2
SMON[INST-TXN-RECO]: mark undo segment 15 as available status:2 ret:0
SMON[INST-TXN-RECO]:about to recover undo segment 16 status:3 inst:2
SMON[INST-TXN-RECO]: mark undo segment 16 as available status:2 ret:0
SMON[INST-TXN-RECO]:about to recover undo segment 17 status:3 inst:2
SMON[INST-TXN-RECO]: mark undo segment 17 as available status:2 ret:0
SMON[INST-TXN-RECO]:about to recover undo segment 18 status:3 inst:2
SMON[INST-TXN-RECO]: mark undo segment 18 as available status:2 ret:0
SMON[INST-TXN-RECO]:about to recover undo segment 19 status:3 inst:2
SMON[INST-TXN-RECO]: mark undo segment 19 as available status:2 ret:0
SMON[INST-TXN-RECO]:about to recover undo segment 20 status:3 inst:2
SMON[INST-TXN-RECO]: mark undo segment 20 as available status:2 ret:0
*** 2011-06-27 22:19:43.299
* kju_tsn_aff_drm_pending TRACEUD: called with tsn x2, dissolve 0
* kju_tsn_aff_drm_pending TRACEUD: tsn_pkey = x2.1
* >> RM REQ QS ---:
single window RM request queue is empty
multi-window RM request queue is empty
* Global DRM state ---:
There is no dynamic remastering
RM lock state = 0
pkey 2.1 undo 1 stat 0 masters[32768, 1->1] reminc 4 RM# 1
flg x0 type x0 afftime x36e6e3a8
nreplays by lms 0 = 0
* kju_tsn_aff_drm_pending TRACEUD: matching request not found on swin queue
* kju_tsn_aff_drm_pending TRACEUD: pp found, stat x0
* kju_tsn_aff_drm_pending TRACEUD: 2 return true
*** 2011-06-27 22:22:18.333
* kju_tsn_aff_drm_pending TRACEUD: called with tsn x2, dissolve 0
* kju_tsn_aff_drm_pending TRACEUD: tsn_pkey = x2.1
* >> RM REQ QS ---:
single window RM request queue is empty
multi-window RM request queue is empty
* Global DRM state ---:
There is no dynamic remastering
RM lock state = 0
pkey 2.1 undo 1 stat 0 masters[32768, 1->1] reminc 4 RM# 1
flg x0 type x0 afftime x36e6e3a8
nreplays by lms 0 = 0
* kju_tsn_aff_drm_pending TRACEUD: matching request not found on swin queue
* kju_tsn_aff_drm_pending TRACEUD: pp found, stat x0
* kju_tsn_aff_drm_pending TRACEUD: 2 return true
*** 2011-06-27 22:24:53.365
* kju_tsn_aff_drm_pending TRACEUD: called with tsn x2, dissolve 0
* kju_tsn_aff_drm_pending TRACEUD: tsn_pkey = x2.1
* >> RM REQ QS ---:
single window RM request queue is empty
multi-window RM request queue is empty
* Global DRM state ---:
There is no dynamic remastering
RM lock state = 0
pkey 2.1 undo 1 stat 0 masters[32768, 1->1] reminc 4 RM# 1
flg x0 type x0 afftime x36e6e3a8
nreplays by lms 0 = 0
* kju_tsn_aff_drm_pending TRACEUD: matching request not found on swin queue
* kju_tsn_aff_drm_pending TRACEUD: pp found, stat x0
* kju_tsn_aff_drm_pending TRACEUD: 2 return true
========================================================================
==============================lmon trace begin==========================
*** 2011-06-27 22:19:27.748
kjxgmpoll reconfig instance map: 1
*** 2011-06-27 22:19:27.748
kjxgmrcfg: Reconfiguration started, type 1
CGS/IMR TIMEOUTS:
CSS recovery timeout = 31 sec (Total CSS waittime = 65)
IMR Reconfig timeout = 75 sec
CGS rcfg timeout = 85 sec
kjxgmcs: Setting state to 4 0.
*** 2011-06-27 22:19:27.759
Name Service frozen
kjxgmcs: Setting state to 4 1.
kjxgrdecidever: No old version members in the cluster
kjxgrssvote: reconfig bitmap chksum 0x2137452d cnt 1 master 1 ret 0
kjxgrpropmsg: SSMEMI: inst 1 - no disk vote
kjxgrpropmsg: SSVOTE: Master indicates no Disk Voting
2011-06-27 22:19:27.760783 : kjxgrDiskVote: nonblocking method is chosen
kjxggpoll: change poll time to 50 ms
2011-06-27 22:19:27.918847 : kjxgrDiskVote: Obtained RR update lock for sequence 5, RR seq 4
2011-06-27 22:19:28.023160 : kjxgrDiskVote: derive membership from CSS (no disk votes)
2011-06-27 22:19:28.023240 : proposed membership: 1
*** 2011-06-27 22:19:28.081
2011-06-27 22:19:28.081952 : kjxgrDiskVote: new membership is updated by inst 1, seq 6
2011-06-27 22:19:28.082073 : kjxgrDiskVote: bitmap: 1
CGS/IMR TIMEOUTS:
CSS recovery timeout = 31 sec (Total CSS waittime = 65)
IMR Reconfig timeout = 75 sec
CGS rcfg timeout = 85 sec
kjxgmmeminfo: can not invalidate inst 2
kjxgmps: proposing substate 2
kjxgmcs: Setting state to 6 2.
kjfmSendAbortInstMsg: send an abort message to instance 2
kjfmuin: inst bitmap 1
kjfmmhi: received msg from inst 1 (inc 2)
Performed the unique instance identification check
kjxgmps: proposing substate 3
kjxgmcs: Setting state to 6 3.
Name Service recovery started
Deleted all dead-instance name entries
kjxgmps: proposing substate 4
kjxgmcs: Setting state to 6 4.
Multicasted all local name entries for publish
Replayed all pending requests
kjxgmps: proposing substate 5
kjxgmcs: Setting state to 6 5.
Name Service normal
Name Service recovery done
*** 2011-06-27 22:19:28.191
kjxgmps: proposing substate 6
kjxgmcs: Setting state to 6 6.
kjxgmcs: total reconfig time 0.432 seconds (from 2895072218 to 2895072650)
kjxggpoll: change poll time to 600 ms
kjfmact: call ksimdic on instance (2)
2011-06-27 22:19:28.211846 :
********* kjfcrfg() called, BEGIN LMON RCFG *********
2011-06-27 22:19:28.211906 : * Begin lmon rcfg step KJGA_RCFG_BEGIN
* kjfcrfg: Resource broadcasting disabled
* kjfcrfg: kjfcqiora returned success
kjfcrfg: DRM window size = 4096->4096 (min lognb = 15)
2011-06-27 22:19:28.211954 :
Reconfiguration started (old inc 4, new inc 6)
TIMEOUTS:
Local health check timeout: 70 sec
Rcfg process freeze timeout: 70 sec
Remote health check timeout: 140 sec
Defer Queue timeout: 163 secs
CGS rcfg timeout: 85 sec
Synchronization timeout: 248 sec
DLM rcfg timeout: 744 sec
List of instances:
1 (myinst: 1)
Undo tsn affinity 1
OMF 0
2011-06-27 22:19:28.212394 : * Begin lmon rcfg step KJGA_RCFG_FREEZE
*** 2011-06-27 22:19:28.233
* published: inc 6, isnested 0, rora req 0,
rora start 0, rora invalid 0, (roram 32767), isrcvinst 1,
(rcvinst 1), isdbopen 1, drh 0, (myinst 1)
thread 1, isdbmounted 1, sid hash x0
* kjfcrfg: published bigns successfully
* Force-published at step 3
2011-06-27 22:19:28.233575 : Global Resource Directory frozen
* roram 32767, rcvinst 1
* kjfc_thread_qry: instance 1 flag 3 thread 1 sid 0
* kjfcrfg: queried bigns successfully
inst 1
* kjfcrfg: single_instance_kjga = TRUE
asby init, 0/1/x2
asby returns, 0/1/x2/false
* Domain maps before reconfiguration:
* DOMAIN 0 (valid 1): 1 2
* End of domain mappings
* dead instance detected - domain 0 invalid = TRUE
* Domain maps after recomputation:
* DOMAIN 0 (valid 0): 1
* End of domain mappings
2011-06-27 22:19:28.235110 : * Begin lmon rcfg step KJGA_RCFG_COMM
2011-06-27 22:19:28.235242 : GSIPC:KSXPCB: msg 0xd8b84550 status 34, type 2, dest 2, rcvr 0
2011-06-27 22:19:28.235339 : GSIPC:KSXPCB: msg 0xd8b80180 status 34, type 2, dest 2, rcvr 1
Active Sendback Threshold = 50 %
Communication channels reestablished
2011-06-27 22:19:28.240076 : * Begin lmon rcfg step KJGA_RCFG_EXCHANGE
2011-06-27 22:19:28.240192 : * Begin lmon rcfg step KJGA_RCFG_ENQCLEANUP
Master broadcasted resource hash value bitmaps
2011-06-27 22:19:28.251474 :
Non-local Process blocks cleaned out
2011-06-27 22:19:28.251822 : * Begin lmon rcfg step KJGA_RCFG_CLEANUP
2011-06-27 22:19:28.265220 : * Begin lmon rcfg step KJGA_RCFG_TIMERQ
2011-06-27 22:19:28.265308 : * Begin lmon rcfg step KJGA_RCFG_DDQ
2011-06-27 22:19:28.265393 : * Begin lmon rcfg step KJGA_RCFG_SETMASTER
2011-06-27 22:19:28.271551 :
Set master node info
2011-06-27 22:19:28.271931 : * Begin lmon rcfg step KJGA_RCFG_ENQREPLAY
2011-06-27 22:19:28.275490 : Submitted all remote-enqueue requests
2011-06-27 22:19:28.275596 : * Begin lmon rcfg step KJGA_RCFG_ENQDUBIOUS
Dwn-cvts replayed, VALBLKs dubious
2011-06-27 22:19:28.277223 : * Begin lmon rcfg step KJGA_RCFG_ENQGRANT
All grantable enqueues granted
2011-06-27 22:19:28.277992 : * Begin lmon rcfg step KJGA_RCFG_PCMREPLAY
2011-06-27 22:19:28.279234 :
2011-06-27 22:19:28.279255 : Post SMON to start 1st pass IR --SMON posted by LMON
2011-06-27 22:19:28.307890 : Submitted all GCS cache requests --IR acquires all gcs resource needed for recovery
2011-06-27 22:19:28.308038 : * Begin lmon rcfg step KJGA_RCFG_FIXWRITES
Post SMON to start 1st pass IR
Fix write in gcs resources
2011-06-27 22:19:28.313508 : * Begin lmon rcfg step KJGA_RCFG_END
2011-06-27 22:19:28.313720 :
2011-06-27 22:19:28.313733 :
Reconfiguration complete
* domain 0 valid?: 0
* kjfcrfg: ask RMS0 to do pnp work
**************** BEGIN DLM RCFG HA STATS ****************
Total dlm rcfg time (inc 6): 0.100 secs (1278500359581, 1278500359681)
Begin step .........: 0.001 secs (1278500359581, 1278500359582)
Freeze step ........: 0.020 secs (1278500359582, 1278500359602)
Remap step .........: 0.002 secs (1278500359602, 1278500359604)
Comm step ..........: 0.005 secs (1278500359604, 1278500359609)
Sync 1 step ........: 0.000 secs (0, 0)
Exchange step ......: 0.000 secs (1278500359609, 1278500359609)
Sync 2 step ........: 0.000 secs (0, 0)
Enqueue cleanup step: 0.011 secs (1278500359609, 1278500359620)
Sync pcm1 step .....: 0.000 secs (0, 0)
Cleanup step .......: 0.013 secs (1278500359620, 1278500359633)
Timerq step ........: 0.000 secs (1278500359633, 1278500359633)
Ddq step ...........: 0.000 secs (1278500359633, 1278500359633)
Set master step ....: 0.006 secs (1278500359633, 1278500359639)
Sync 3 step ........: 0.000 secs (0, 0)
Enqueue replay step : 0.004 secs (1278500359639, 1278500359643)
Sync 4 step ........: 0.000 secs (0, 0)
Enqueue dubious step: 0.001 secs (1278500359643, 1278500359644)
Sync 5 step ........: 0.000 secs (0, 0)
Enqueue grant step .: 0.001 secs (1278500359644, 1278500359645)
Sync 6 step ........: 0.000 secs (0, 0)
PCM replay step ....: 0.030 secs (1278500359645, 1278500359675)
Sync 7 step ........: 0.000 secs (0, 0)
Fixwrt replay step .: 0.003 secs (1278500359675, 1278500359678)
Sync 8 step ........: 0.000 secs (0, 0)
End step ...........: 0.001 secs (1278500359680, 1278500359681)
Number of replayed enqueues sent / received .......: 0 / 0
Number of replayed fusion locks sent / received ...: 0 / 0
Number of enqueues mastered before / after rcfg ...: 2217 / 2941
Number of fusion locks mastered before / after rcfg: 3120 / 5747
**************** END DLM RCFG HA STATS *****************
*** 2011-06-27 22:19:36.589
kjxgfipccb: msg 0x0x7ff526139320, mbo 0x0x7ff526139310, type 19, ack 0, ref 0, stat 34
=====================================================================
============================lms trace begin==========================
*** 2011-06-27 22:38:54.663
2011-06-27 22:38:54.663764 : 0 GCS shadows cancelled, 0 closed, 0 Xw survived
2011-06-27 22:38:54.673539 : 5230 GCS resources traversed, 0 cancelled
2011-06-27 22:38:54.707671 : 9322 GCS shadows traversed, 0 replayed, 0 duplicates,
5183 not replayed, dissolve 0 timeout 0 RCFG(10) lms 0 finished replaying gcs resources
2011-06-27 22:38:54.709132 : 0 write requests issued in 384 GCS resources --check past image
0 PIs marked suspect, 0 flush PI msgs
2011-06-27 22:38:54.709520 : 0 write requests issued in 273 GCS resources
1 PIs marked suspect, 0 flush PI msgs
2011-06-27 22:38:54.709842 : 0 write requests issued in 281 GCS resources
0 PIs marked suspect, 0 flush PI msgs
2011-06-27 22:38:54.710159 : 0 write requests issued in 233 GCS resources
0 PIs marked suspect, 0 flush PI msgs
2011-06-27 22:38:54.710531 : 0 write requests issued in 350 GCS resources
lms 0 finished fixing gcs write protocol
Instance Recovery和普通的Crash Recovery最大的区别在于实例恢复过程中的GRD Frozen和对GES/GCS资源的Remaster,这部分工作主要由LMON进程完成,可以从以上trace中发现一些KJGA_RCFG_*形式的Reconfiguration步骤,它们的含义:
Reconfiguration Steps:
1. KJGA_RCFG_BEGIN
LMON continuously polling for reconfiguration event. Once cgs reports a change in cluster membership,
LMON starts reconfiguration
2. KJGA_RCFG_FREEZE
All processes acknowledges to the reconfiguration freeze before LMON continue
3. KJGA_RCFG_REMAP
Updates new instance map (kjfchsu), re-distributes resource mastership. Invalidate recovery domains
if reconfiguration is caused by instance death.
4. KJGA_RCFG_COMM
Reinitialize communication channel
5. KJGA_RCFG_EXCHANGE
Exchange of master information of gcs, ges and file affinity master
6. KJGA_RCFG_ENQCLEANUP
Delete remote dead gcs/ges locks. Cancel converting gcs requests.
7. KJGA_RCFG_CLEANUP
Cleanup/remove ges resources
8. KJGA_RCFG_TIMERQ
Restore relative timeout for enqueue locks on timeout queue
9. KJGA_RCFG_DDQ
Clean out enqueue locks on deadlock queue
10. KJGA_RCFG_SETMASTER
Update master info for each enqueue resources that need to be remastered.
11. KJGA_RCFG_REPLAY
Replay enqueue locks
12. KJGA_RCFG_ENQDUBIOUS
Invalidates ges resources without established value
13. KJGA_RCFG_ENQGRANT
Grants all grantable ges lock requests
14. KJGA_RCFG_REPLAY2
Enqueue reconfiguration complete. Post SMON to start instance recovery. Starts replaying gcs resources.
15. KJGA_RCFG_FIXWRITES2
Fix write state of gcs resources
16. KJGA_RCFG_END
Unfreeze lock database
Instance Recovery相关的诊断事件
我们无法禁止Instance Recovery的发生,事实上一旦出现Instance Crash那么Instance Recovery就是必须的。
与Instance Recovery相关的诊断事件主要有10426和29717等:
10426 – Reconfiguration trace event
10425 – Enqueue operations
10432 – Fusion activity
10429 – IPC tracing
oerr ora 10425
10425, 00000, "enable global enqueue operations event trace"
// *Document: NO
// *Cause:
// *Action: Dump trace for global enqueue operations.
oerr ora 10426
10426, 00000, "enable ges/gcs reconfiguration event trace"
// *Document: NO
// *Cause:
// *Action: Dump trace for ges/gcs reconfiguration.
oerr ora 10430
10430, 00000, "enable ges/gcs dynamic remastering event trace"
// *Document: NO
// *Cause:
// *Action: Dump trace for ges/gcs dynamic remastering.
oerr ora 10401
10401, 00000, "turn on IPC (ksxp) debugging"
// *Cause:
// *Action: Enables debugging code for IPC service layer (ksxp)
oerr ora 10708
10708, 00000, "print out trace information from the RAC buffer cache"
// *Cause: N/A
// *Action: THIS IS NOT A USER ERROR NUMBER/MESSAGE. THIS DOES NOT NEED TO BE
// TRANSLATED OR DOCUMENTED. IT IS USED ONLY FOR DEBUGGING.
oerr ora 29717
29717, 00000, "enable global resource directory freeze/unfreeze event trace"
// *Document: NO
// *Cause:
// *Action: Dump trace for global resource directory freeze/unfreeze.
diag RAC INSTANCE SHUTDOWN LMON
LMON will dump more informations to trace during reconfig and freeze.
event="10426 trace name context forever, level 8"
event="29717 trace name context forever, level 5"
or
event="10426 trace name context forever, level 12"
event="10430 trace name context forever, level 12"
event="10401 trace name context forever, level 8"
event="10046 trace name context forever, level 8"
event="10708 trace name context forever, level 15"
event="29717 trace name context forever, level 5"
see 29717 grd frozen trace
alter system set event='29717 trace name context forever, level 5' scope=spfile;
=========================================================================
============================lmon trace begin=============================
********* kjfcrfg() called, BEGIN LMON RCFG *********
2011-06-27 23:13:16.693089 : * Begin lmon rcfg step KJGA_RCFG_BEGIN
* kjfcrfg: Resource broadcasting disabled
* kjfcrfg: kjfcqiora returned success
kjfcrfg: DRM window size = 4096->4096 (min lognb = 15)
2011-06-27 23:13:16.693219 :
Reconfiguration started (old inc 4, new inc 6)
TIMEOUTS:
Local health check timeout: 70 sec
Rcfg process freeze timeout: 70 sec
Remote health check timeout: 140 sec
Defer Queue timeout: 163 secs
CGS rcfg timeout: 85 sec
Synchronization timeout: 248 sec
DLM rcfg timeout: 744 sec
List of instances:
1 (myinst: 1)
Undo tsn affinity 1
OMF 0
[FDB][start]
2011-06-27 23:13:16.701320 : * Begin lmon rcfg step KJGA_RCFG_FREEZE
[FACK][18711 not frozen] --fack means acknowledge in advance
[FACK][18713 not frozen]
[FACK][18719 not frozen]
[FACK][18721 not frozen]
[FACK][18723 not frozen]
[FACK][18729 not frozen]
[FACK][18739 not frozen]
[FACK][18743 not frozen]
[FACK][18745 not frozen]
[FACK][18747 not frozen]
[FACK][18749 not frozen]
[FACK][18751 not frozen]
[FACK][18753 not frozen]
[FACK][18755 not frozen]
[FACK][18757 not frozen]
[FACK][18759 not frozen]
[FACK][18763 not frozen]
[FACK][18765 not frozen]
[FACK][18767 not frozen]
[FACK][18769 not frozen]
[FACK][18771 not frozen]
[FACK][18775 not frozen]
[FACK][18777 not frozen]
[FACK][18816 not frozen]
[FACK][18812 not frozen]
[FACK][18818 not frozen]
[FACK][18820 not frozen]
[FACK][18824 not frozen]
[FACK][18826 not frozen]
[FACK][18830 not frozen]
[FACK][18835 not frozen]
[FACK][18842 not frozen]
[FACK][18860 not frozen]
[FACK][18865 not frozen]
[FACK][18881 not frozen]
[FACK][18883 not frozen]
[FACK][18909 not frozen]
*** 2011-06-27 23:13:16.724
* published: inc 6, isnested 0, rora req 0,
rora start 0, rora invalid 0, (roram 32767), isrcvinst 0,
(rcvinst 32767), isdbopen 1, drh 0, (myinst 1)
thread 1, isdbmounted 1, sid hash x0
* kjfcrfg: published bigns successfully
* Force-published at step 3
2011-06-27 23:13:16.724764 : Global Resource Directory frozen
* kjfc_qry_bigns: noone has the rcvinst established yet, set it to the highest open instance = 1
* roram 32767, rcvinst 1
* kjfc_thread_qry: instance 1 flag 3 thread 1 sid 0
* kjfcrfg: queried bigns successfully
=====================================================================
==========================lmd0 trace begin===========================
*** 2011-06-27 23:13:16.700
[FFCLI][frozen]
[FUFCLI][normal]