第2章 端到端的机器学习项目
写在前面
参考书
《机器学习实战——基于Scikit-Learn和TensorFlow》
工具
python3.5.1,Jupyter Notebook, Pycharm
回归问题的性能指标
- 均方根误差(RMSE):$sqrt {frac{1}{m} sumlimits_{i=1}^m ( h(x^{(i)}) - y^{(i)} ) ^2}$,对应$l_2$范数。
- 平均绝对误差(MAE):$frac{1}{m} sumlimits_{i=1}^m | h( x^{(i)} ) - y^{(i)} |$,对应$l_1$范数。
- 范数指数越高,则越关注大的价值,忽略小的价值。这就是为什么RMSE比MAE对异常值更敏感。但是当异常值非常稀少(例如钟形曲线)时,RMSE的表现优异,通常作为首选。
df.where详解
- 参考连接:https://blog.csdn.net/brucewong0516/article/details/80226990
- 返回一个同样shape的df,当满足条件为TRUE时,从本身返回结果,否则从返回其他df的结果
- df.mask使用时,结果与where相反
分层抽样详解
- sklearn.model_selection.StratifiedShuffleSplit
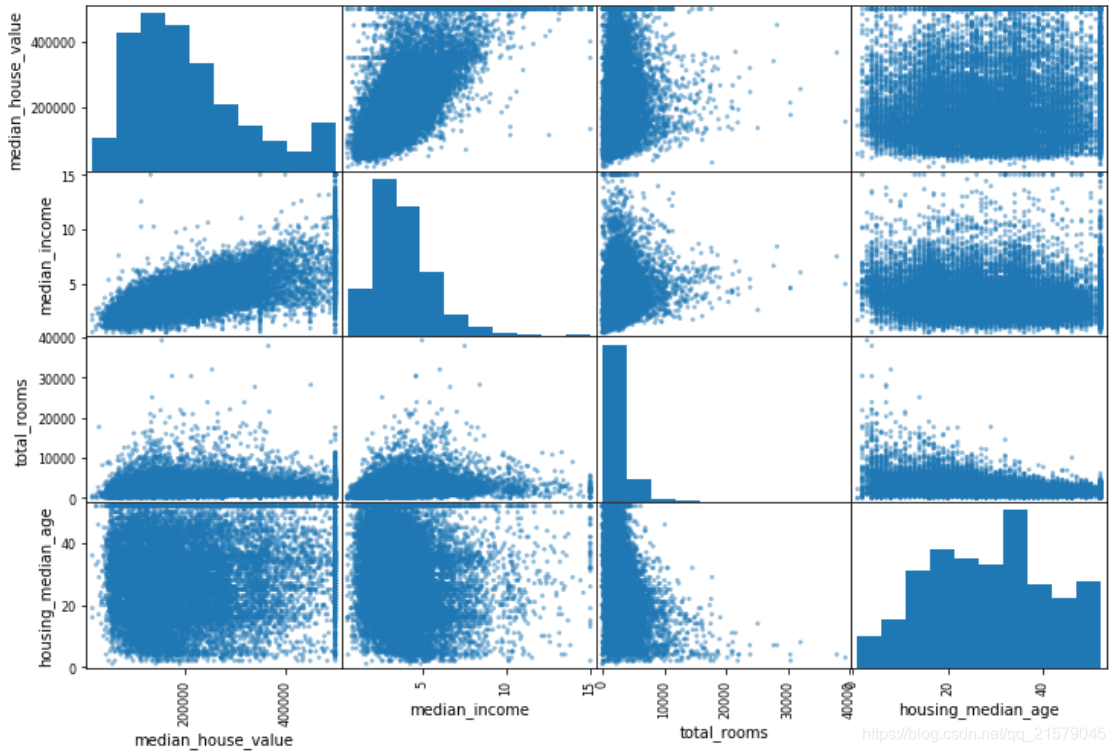
检验属性之间的相关性
- from pandas.plotting import scatter_matrix
缺失值处理
- from sklearn.preprocessing import Imputer
处理文本和分类属性
- from sklearn.preprocessing import LabelEncoder
- LabelEncoder
- 这种代表方式产生的一个问题是,机器学习算法会一位两个相近的数字比两个离得较远的数字更为相似一些,然而真实情况并非如此。
- from sklearn.preprocessing import OneHotEncoder
- from sklearn.preprocessing import LabelBinarizer
- LabelBinarizer
- 使用LabelBinarizer类可以一次性完成两个转换
- 从文本类别转换为整数类别,再从整数类别转换为独热向量
- 这时默认返回的是一个密集的Numpy数组,通过发送sparse_output=True,可以得到稀疏矩阵
特征缩放
- 最大最小缩放(归一化):MinMaxScaler
- 标准化:StandardScaler
用numpy连接两个矩阵
np.c_和np.r_的用法解析- np.c_是按行连接两个矩阵,就是把两矩阵左右相加,要求行数相等。
- np.r_是按列连接两个矩阵,就是把两矩阵上下相加,要求列数相等。
交叉验证
- sklearn的交叉验证功能更倾向于使用效用函数(越大越好),而不是成本函数(越小越好),所以计算分数的函数实际上是负的MSE(一个负值)函数,这就是为什么上面的代码在计算平方根之前会先计算出-scores。
我的CSDN:https://blog.csdn.net/qq_21579045
我的博客园:https://www.cnblogs.com/lyjun/
我的Github:https://github.com/TinyHandsome
纸上得来终觉浅,绝知此事要躬行~
欢迎大家过来OB~
by 李英俊小朋友