数组:一段连续控件存储数据,指定下标的查找,时间复杂度O(1),通过给定值查找,需要遍历数组,自已对比复杂度为O(n) 二分查找插值查找,复杂度为O(logn) 线性链表:增 删除仅处理结点,时间复杂度O(1)查找需要遍历也就是O(n) 二叉树:对一颗相对平衡的有序二叉树,对其进行插入,查找,删除,平均复杂度O(logn) 哈希表:哈希表中进行添加,删除,查找等操作,性能十分之高,不考虑哈希冲突的情况下,仅需一次定位即可完成,时间复杂度为O(1)哈希表的主干就是数组
hash冲突
当我们对某个元素进行哈希运算,得到一个存储地址,然后要进行插入的时候,发现已经被其他元素占用了,其实这就是所谓的哈希冲突,也叫哈希碰撞。
哈希冲突的解决方案有多种:开放定址法(发生冲突,继续寻找下一块未被占用的存储地址),再散列函数法,链地址法,而HashMap即是采用了链地址法,也就是数组+链表的方式

entry结构:
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
final int hash;
……
}
1.7 put过程 数组+链表 头插法
public V put(K key, V value) {
//其允许存放null的key和null的value,当其key为null时,调用putForNullKey方法,放入到table[0]的这个位置
if (key == null)
return putForNullKey(value);
//通过调用hash方法对key进行哈希,得到哈希之后的数值。该方法实现可以通过看源码,其目的是为了尽可能的让键值对可以分不到不同的桶中
int hash = hash(key);
//根据上一步骤中求出的hash得到在数组中是索引i
int i = indexFor(hash, table.length);
//如果i处的Entry不为null,则通过其next指针不断遍历e元素的下一个元素。
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
//如果遍历链表没发现这个key,则会调用以下代码
modCount++;
addEntry(hash, key, value, i);
return null;
}
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
}
Entry( int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
/*这里的next=n,说明了一切。意为: 新建节点的next,指向了n。n即为key对应索引处的链表。把之前的链表放到了新建节点的next的位置。说明是在以前链表的头部插入了新节点。故为头插法*/
get过程
public V get(Object key) {
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
final Entry<K,V> getEntry(Object key) {
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[indexFor(hash, table.length)];e != null;e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
hash算法
final int hash(Object k) {
int h = 0;
if (useAltHashing) {
if (k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h = hashSeed;
}
//得到k的hashcode值
h ^= k.hashCode();
//进行计算
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
HashMap的容量
static int indexFor(int h, int length) {
return h & (length-1);
}
为什么是2的n次方
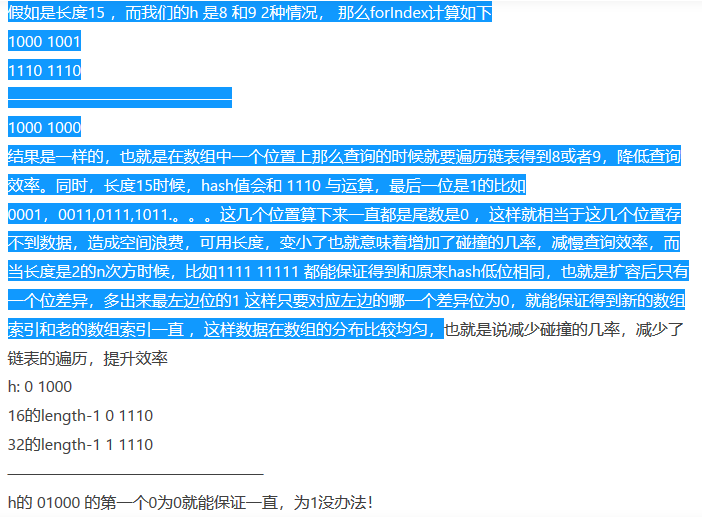
HashMap的resize(rehash)
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return; }
Entry[] newTable = new Entry[newCapacity];
boolean oldAltHashing = useAltHashing;
useAltHashing |= sun.misc.VM.isBooted() && (newCapacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
boolean rehash = oldAltHashing ^ useAltHashing;
transfer(newTable, rehash); //transfer函数的调用
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1); }
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) { //这里才是问题出现的关键..
while(null != e) {
Entry<K,V> next = e.next; //寻找到下一个节点..
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key); }
int i = indexFor(e.hash, newCapacity); //重新获取hashcode
e.next = newTable[i];
newTable[i] = e;
e = next; } } }
单线程下扩容

多线程扩容
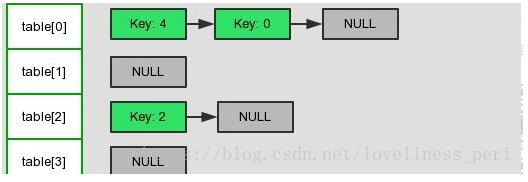
假设这里有两个线程同时执行了put()操作,并进入了transfer()环节:
刚开始:
线程1中的e指向key(0),next指向key(4),此时线程1挂起。

线程2调度完成所有节点的移动,移动后结果为:
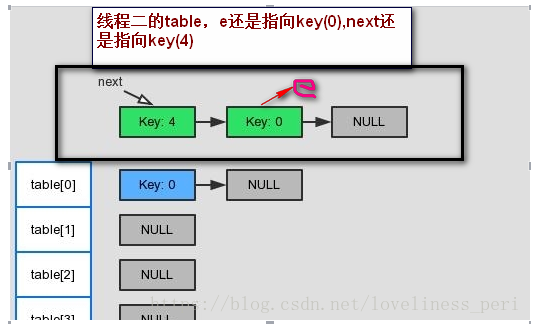
线程1继续执行,线程一会把线程二的新表当成原始的hash表,将原来e指向的key(0)节点当成是线程二中的key(0),放在自己所建table[0]的头节点。注意线程1的next仍然指向key(4),
虽然此时key(0)的next已经是null。
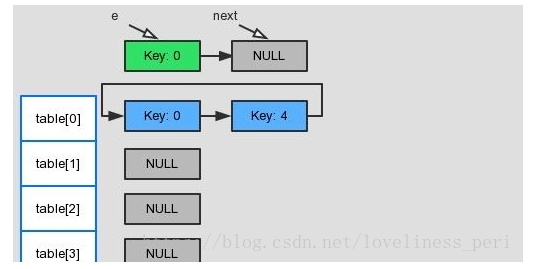
执行e.next = newTable[i],于是 key(0)的 next 指向了线程1的新 Hash 表,因为新 Hash 表为空,所以e.next = null,
执行newTable[i] = e,所以线程1的新 Hash 表第一个元素指向了线程2新 Hash 表的 key(0)。好了,e 处理完毕。
执行e = next,将 e 指向 next,所以新的 e 是 key(4)
线程1的e指向了上一次循环的next,也就是key(4),此时key(4)的next已经是key(0)。将key(4)插入到table[0]的头节点,并且将key(4)的next设置为key(0)。此时仍然没有问题。
现在的 e 节点是 key(4),首先执行Entry<K,V> next = e.next,那么 next 就是 key(0)了
执行e.next = newTable[i],于是key(0) 的 next 就成了 key(4)
执行newTable[i] = e,那么线程1的新 Hash 表第一个元素变成了 key(4)
执行e = next,将 e 指向 next,所以新的 e 是 key(0)
现在的 e 节点是 key(0),首先执行Entry<K,V> next = e.next,那么 next 就是 null
执行e.next = newTable[i],于是key(0) 的 next 就成了 key(4)
执行newTable[i] = e,那么线程1的新 Hash 表第一个元素变成了 key(0)
执行e = next,将 e 指向 next,所以新的 e 是 key(4)