名称:FaceNet: A Unified Embedding for Face Recognition and Clustering
时间:2015.04.13
来源:CVPR 2015
来自谷歌的一篇文章,这篇文章主要讲述的是一个利用深度学习来进行人脸识别的方法,目前在LFW上面取得了最好的成绩,识别率为99.63%。传统的基于CNN的人脸识别方法为:利用CNN的Siamese网络来提取人脸特征,然后利用SVM等方法进行分类。而本篇文章提出了一个方法叫做FaceNet,它直接学习图像到欧式空间上点的映射,其中两张图像对应的特征的欧式空间的距离用来直接判断两张图片的相似度。这篇文章的最大创新点是提出了不同的损失函数,直接优化特征本身,用特征空间上点的距离来判断两张图片是否是同一类。

上图是文章中所采用的网络结构,其中可以看出,其中,前面部分跟CNN是相同的,只是后面接一个特征归一化(使其特征的||f(x)||2=1,这样子,所有图像的特征都会被映射到一个超球面上),接着再去优化这些特征,而文章这里提出了一个新的损失函数(优化函数),而这也是文章最大的特点所在。
什么是Triplet Loss呢,顾名思义也就是有三张图片输入的Loss(之前的都是Double Loss或者是 Single Loss),本文直接学习特征间的可分性:相同身份之间的特征距离要尽可能的小,而不同身份之间的特征距离要尽可能的大。
对于Triple loss如下图所示
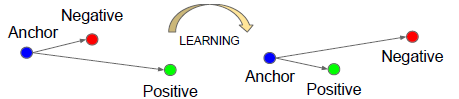
意思就是通过学习,使得类间距离要大于类内的距离,Anchor为 系统选定的锚点。
优化函数为
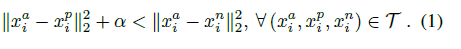
上式表达的含义是左边类内的距离加上边际数值α要小于右边类间的距离,这个约束要在所有的Triplet图像对上都成立,那么损失函数为
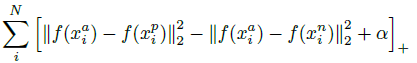
在上式中,如果严格按照上式进行学习的话,它的T(穷举所有的图像3元组)是非常巨大的。
FE:在一个1000人,没人有20张图片的情况下,其所有的可能组合为T=10002020999。O(T)=NN,所以穷举是很困难的,那么我们该如何从这么多的图像中挑选呢?答案是选择最难区分的图像对。
给定一张人脸图片,我们要挑选其中的一张hard positive:即另外19张图像中,跟它最不相似的图片,同时选择一张hard negative:即在20*999张图像中跟它最为相似的图片。挑选hard positive和hard negative有两种方法,offline和online方法,具体的差别只在训练上。本文采用的是在线的方式,在min-batch中挑选所有的anchor positive图像对,同时依然选择最为困难的anchor negative图像对。
那么我们的问题就转为为了如何悬着最为困难的负样本,在实际训练中容易导致很快的陷入局部最优。为了避免这个问题,在选择negative的时候,使其满足式3,把这个约束称为半约束: