摘要:郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Abstract
事实证明,深度RL模型可以成功地学习图像输入下的控制策略。但是,它们一直在努力学习需要更长时间信息的策略。RNN结构已用于处理数据点之间长期依赖的任务中。我们研究了这些结构,以克服长期依赖给学习策略带来的困难。
1 Introduction
RL的最新进展已导致在各种游戏(例如Atari 2600游戏)上达到人类水平或更高的性能。但是,训练这些网络可能会花费很长时间,并且现有技术[0]在需要长期计划的几款游戏中效果不佳。
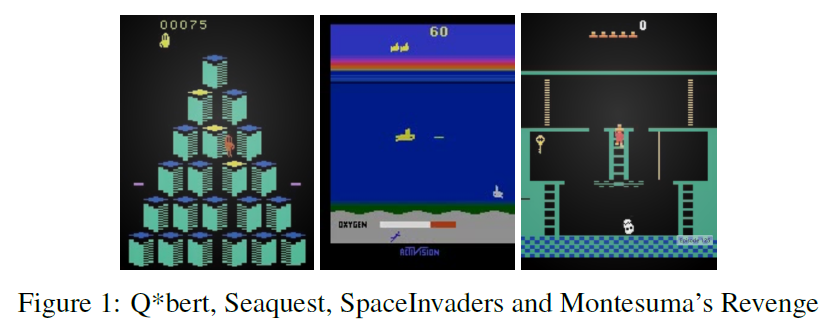
DQN的局限性在于,它们从单个先前状态中学习映射,该状态由少量游戏屏幕组成。在实践中,DQN使用包含最后四个游戏屏幕的输入进行训练。因此,DQN在要求智能体记住四个屏幕之前的信息的游戏中表现较差。从图1中DQN在接近或低于人类水平时表现不佳的游戏类型可以明显看出这一点[0]。
我们探讨了DRQN,RNN [6]和类似于[5]的DQN的组合1。RNN背后的想法是能够保留更长时间的状态信息,并将其整合以更好地预测Q值,从而在需要长期计划的游戏中表现更好。
除了朴素的RNN架构外,我们还研究了增强型RNN架构,例如注意力RNN。RNN在翻译任务中的最新成果[2, 3]已显示出希望。使用注意力的优点在于,它使DRQN可以专注于特定的先前状态,该状态对于预测当前状态下的动作而言非常重要。我们研究增强DRQN的注意力并评估其有效性。
1 代码参见https://github.com/dillonalaird/deep-rl-tensorflow
2 Related Work
RL涵盖了从玩五子棋[7]到驾驶RC直升机[8]的各个领域。传统RL依靠迭代算法在较小的状态空间上训练智能体。后来,诸如Q学习之类的算法与非线性函数近似一起用于在较大的状态空间上训练智能体。然而,这些算法更难训练并且会发散[9]。
RL的最新进展使得使用深度神经网络作为非线性函数近似并对其进行训练成为可能,而不会遇到稳定性问题。这些类型的模型被称为Q网络,并且在玩诸如Atari游戏之类的游戏时非常成功,其中输入仅是屏幕上的像素[0, 1]。
我们研究扩展此框架以包括RNN。RNN在Q学习[5]中已被使用过,但是在通过闪烁游戏画面而创建的部分可观察的马尔可夫决策过程中。我们的目标是提高智能体所获得的平均分数。
3 Deep Q-Learning
我们研究玩Atari游戏的智能体。在我们的环境中,智能体与Atari模拟器进行交互。它们在时间 t 收到观测值xt ∈ RD,它是来自当前游戏屏幕的像素向量。然后,智能体采取动作at ∈ A = {1, ... , K}并获得奖励rt,即游戏得分的变化。
智能体的目标是采取使未来折扣奖励最大化的动作。我们可以用![]() 来计算未来奖励,其中T是游戏的结束,并且γ是我们的折扣因子。实现此目标的一种方法是采取与最大动作-价值函数相对应的动作:
来计算未来奖励,其中T是游戏的结束,并且γ是我们的折扣因子。实现此目标的一种方法是采取与最大动作-价值函数相对应的动作:
![]()
这是策略π = P(a|s)下未来折扣奖励的期望价值。如果智能体处于特定状态,这就是采取动作的概率。不幸的是,这种方法很难计算,因此我们用另一个函数![]() 对其进行近似。我们为函数近似研究了几种不同类型的深度神经网络架构,这被称为Q网络。
对其进行近似。我们为函数近似研究了几种不同类型的深度神经网络架构,这被称为Q网络。
训练此函数可能很不稳定,有时会发散。以下损失函数用于帮助减少其中的某些问题[0]:
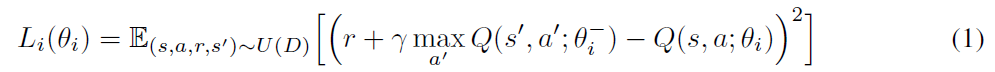
其中经验定义为et = (st, at, rt, st+1),存储经验的缓存为Dt = {e1, ... , et}。在SGD更新中,我们对经验元组的迷你批次进行采样(s, a, r, s') ~ U(D),它们是从内存缓存中随机均匀采样的。这被称为经验回放,旨在减轻训练过程中的不稳定。在上面的损失函数中,![]() 是在迭代 i 中计算目标网络的网络参数。我们仅在每C步用Q网络参数更新这些目标网络参数θi;请注意,我们保留了Q网络和目标网络。
是在迭代 i 中计算目标网络的网络参数。我们仅在每C步用Q网络参数更新这些目标网络参数θi;请注意,我们保留了Q网络和目标网络。
4 Deep Recurrent Q-Learning
我们研究了DRQN的几种结构。其中之一是在DQN之上使用RNN,以将信息保留更长的时间。这应有助于智能体完成可能需要智能体记住发生在几十个屏幕前的特定事件的任务。
我们还研究了RNN中注意机制的使用。注意力使RNN可以专注于过去看到的特定状态。可以将其视为将重要性赋予给RNN所迭代的状态。我们研究了两种注意力形式,一种是线性注意力,使用一个学到的向量来分配先前状态的重要性,另一种是全局注意力,它基于当前状态为先前状态赋予重要性。
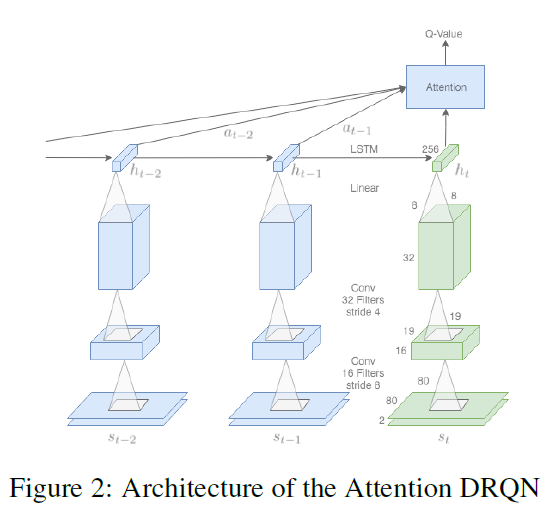
第一种结构是DQN的基本扩展。DRQN的结构通过LSTM增强DQN的全连接层。我们通过查看最后L个状态{st-(L-1), ... , st}来完成此操作,并将其输入到CNN中,以获得中间输出CNN(st-i) = xt-i。然后将它们馈送到RNN(为此我们使用LSTM,但可以是任何RNN),RNN(xt-i, ht-i-1) = ht-i,最终输出ht用于预测Q值,这现在是Q({st-(L-1), ... , st}, at)的函数。
我们使用的第二种结构是注意力RNN的版本,我们称为线性注意力。对于线性注意力RNN,我们取RNN输出的L个隐含状态{ht-(L-1), ... , ht},并计算va的内积![]() 。这使模型可以根据学到的va值将更多的注意力集中在附近的隐含状态或更远的状态上。然后,我们对这些值取一个softmax,即
。这使模型可以根据学到的va值将更多的注意力集中在附近的隐含状态或更远的状态上。然后,我们对这些值取一个softmax,即![]() 。我们使用这个softmax对隐含状态进行加权求和,以获得上下文向量
。我们使用这个softmax对隐含状态进行加权求和,以获得上下文向量![]() 。然后将该上下文向量用于预测Q值。
。然后将该上下文向量用于预测Q值。
我们使用的第三个结构包括全局注意力机制,类似于[3]中使用的全局注意力。在图2中可以看到这种注意力的示意图。我们将当前状态st视为"解码器"输入,将先前L-1个状态视为"编码器"输入。我们计算以下分数![]() 。然后,我们对这些值取一个softmax,即
。然后,我们对这些值取一个softmax,即![]() 。上下文向量被计算为先前隐含状态的加权和
。上下文向量被计算为先前隐含状态的加权和![]() 。最后,上下文向量用于计算
。最后,上下文向量用于计算![]() ,然后用于预测Q值。这种注意力方式允许模型根据当前状态ht专注于先前状态,而不是像va这样的固定向量。
,然后用于预测Q值。这种注意力方式允许模型根据当前状态ht专注于先前状态,而不是像va这样的固定向量。
在对经验进行采样并使用(1)中定义的损失函数时,学习观察序列会带来一些困难。我们提出了一个简单的解决方案,在其中采样et ~ U(D),取之前L个状态![]() ,然后将以前游戏的状态归零。例如,如果st-i是先前比赛的结束,那么我们将拥有状态{0, ... , 0, st-(i+1), ... , st},并且下一个状态{0, ... , 0, st-(i+2), ... , st+1}也相似。
,然后将以前游戏的状态归零。例如,如果st-i是先前比赛的结束,那么我们将拥有状态{0, ... , 0, st-(i+1), ... , st},并且下一个状态{0, ... , 0, st-(i+2), ... , st+1}也相似。
5 Experiments
对于我们的实验,我们主要关注游戏Q*bert。我们选择Q*bert是因为它对DQN而言是具有挑战性的游戏,其得分仅略高于人类水平[0],但其挑战性不至于使得DQN无法取得任何进步,例如Montezuma's Revenge[0]。
对于输入,DRQN在每种状态下采用指定数量的屏幕。屏幕图像是灰度的,并调整为80 x 80。第一个隐含层在输入图像上用16个滤波器进行卷积(19 x 19,步幅为8),并应用ReLU。第二个隐含层用32个滤波器进行卷积(8 x 8, 步幅为4),再次应用ReLU。卷积输出被馈送到每层具有256个隐含单元的LSTM。最后,全连接的线性层为每个可能的动作输出一个Q值。附录A中列出了所有使用的超参数。它们与[0]中使用的超参数相似。
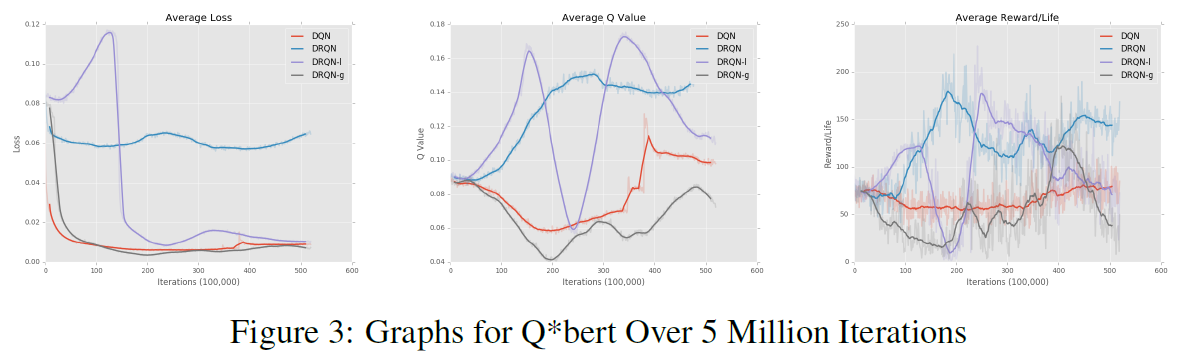
对于图3,我们在Q*bert上训练了4种不同的模型,进行了大约500万次迭代,完成需要大约6天的时间。所有模型都使用上述相同的CNN来处理图像。DQN在每个状态使用4个游戏画面。
图3中的DRQN模型使用L = 16且每个状态2个屏幕,这使它可以查看最近32帧。我们希望让模型查看足够多的先前状态以做出明智的决定,但又不至于让RNN遭受梯度消失和训练时间问题的困扰,这就是为什么我们选择L =16。我们发现每个状态2个屏幕可以使模型高效运行而不会遭受任何损失。DRQN是一个基本的循环模型,没有注意力机制。DRQN-1是具有线性注意力的循环模型,DRQN-g是具有全局注意力的循环模型。
从图3中可以看到,DRQN模型的图表带噪。常规的DRQN在每次生命的平均分数方面表现最优,但减少损失的时间也最困难。DRQN-1的图噪声最大。在每个统计数据的某个点,它的表现接近最高值和最低值。DRQN-g的性能令人失望。它具有最简单的时间来最小化损失,但是却很难在每次生命的平均奖励中获得动量。
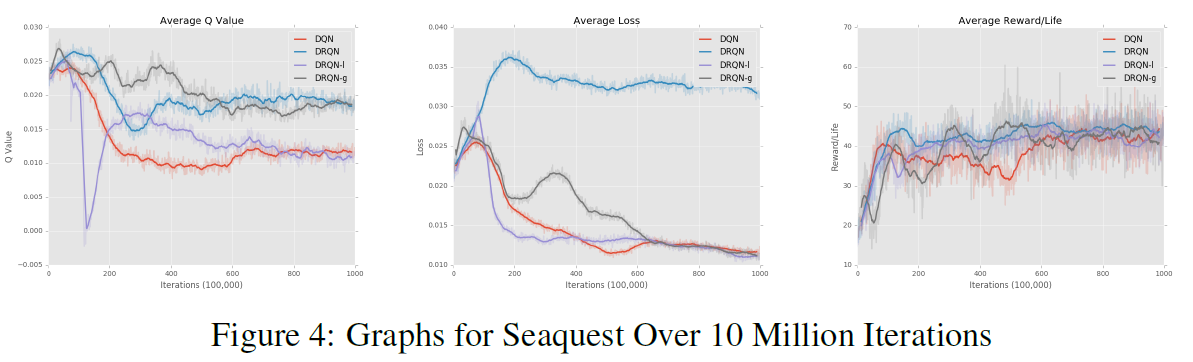
在图4中,我们在Seaquest上训练了所有4个模型。对于我们的DRQN模型,我们使用L = 2和2个游戏屏幕,因此它查看的游戏屏幕数量与DQN, 4相同。平均得分都收敛到相同的值,这是我们期望的,因为每个智能体都是给定相同数量的屏幕来预测Q值。
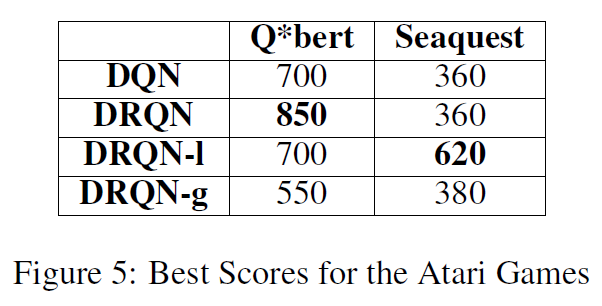
在图5中,我们可以看到从玩100次Q*bert游戏的每种算法获得的最优分数。该表反映了算法在图3中每次生命的平均奖励中所处的位置。DRQN表现最优,其次是DQN,DRQN-1,最后是DRQN-g。不幸的是,我们无法在Q*bert上重现[1]所获得的分数。
从这些图中可以看出,添加循环层可以帮助该智能体,而添加注意力机制只会阻碍该智能体。我们假设几种原因可以解释意外的结果。一方面,必须训练的网络更大,需要调整的参数更多。从图中可以明显看出,注意力DRQN没有收敛。我们假设进行较长时间的训练会产生更好的结果。另一个原因是玩Q*bert可能不需要注意力。由于智能体在每个屏幕上都收到完整的游戏状态,因此它不需要将精力集中在过去的游戏屏幕上。
Conclusion
我们研究了在DQN之上使用RNN(DRQN)的情况,还测试了几种不同类型的注意力机制来增强RNN。不出所料,我们确认基本的DRQN在DQN难以学习的游戏中比DQN可以获得更高的分数。我们还发现增加注意力也可能会阻碍某些游戏的性能。
展望未来,希望对算法进行更长时间的训练,以查看注意力最终是否确实表现更好。可以看出,这些图还没有收敛,仍然带噪。此外,我们认为在屏幕上未完全显示游戏状态的游戏上运行智能体会更好地利用注意力来获得更高的分数。想想一个游戏,在一个屏幕中你看到一个人,而在下一屏幕中,他们在墙后奔跑。智能体应该查看该人最后一次出现的屏幕,以获取有关其当前位置在当前时间步骤中可能在何处的信息。
Appendix A:
