通常情况下,ETL方案需要同时访问两个或多个数据源,并把结果合并为单个数据流,输出到目标表中。为了向目标表中提供统一的数据结构,需要把多个数据源连接在一起。数据连接的另外一种用法,就是根据现有的数据,向目标表中添加数据,或者更新现有的数据。这种方案是把源数据与现有的数据进行比较,以便找到需要更新的数据行,或者需要添加的数据。在设计ETL方案时,连接数据可以使用SSIS的转换(Lookup和Merge Join)组件,或者直接在关系型数据库内部执行,而后者性能更高。
一,SSIS 连接
查找转换以嵌套循环(Nested Loop)的方式实现连接操作,该组件被设计为以同步方式进行连接操作,这意味着在进行转换的时候,查找转换不会阻塞数据流管道,但是,在全缓存(Full Cache)模式下,当组件加载查找数据集的内部缓存时,可能会阻塞包一段时间,阻塞时间的长短由加载查找数据集的时间来决定。
合并连接(Merge Join)转换也可以实现连接操作,通常情况下,它比查找转换更适合做连接操作,转换的性能更高。相比查找转换,合并连接对输入数据的要求更严格:
- 两个输入的数据必须是有序的;
- 设置连接类型,Merge Join支持Inner Join,Left Join和Full Join三种连接类型;
- 设置比较列的映射,Merge Join只支持等值连接,自动按照排序列设置比较列的映射;
合并连接转换组件只能产生单个输出,用户需要单独设置输出的数据列,并且输出的结果集是有序的。
典型的合并连接的设计如下图,推荐在源组件中对数据做排序,而不是使用Sort组件来对数据进行排序。
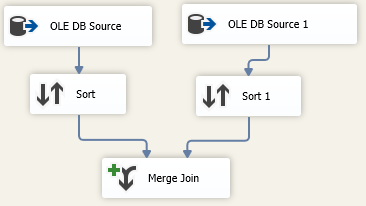
1,输入的数据是有序的
Merge Join的输入必须是有序的,可以使用Sort组件对数据进行排序,或者在源组件中使用SQL脚本对数据排序。当使用脚本对数据排序时,需要设置源组件的输出列的属性SortKeyPosition,默认值是0,表示无序。
SortKeyPosition属性的值,有正整数,0和负整数,分别具有以下含义:
- 当该属性的值为正整数时,表示数据是升序排序的,
- 当值为负整数时,表示数据是降序的,
- 其绝对值表示排序列的位置,Merge join转换组件对位置相同的列做等值比较。
排序列的位置和顺序十分重要,Merge Join把相同位置的列做对比,如果这些列的值都相等,那么匹配成功。
如果使用Sort组件对数据进行排序,那么在Sort组件的输出列中,排序的SortKeyPosition属性值也是非0的,例如,对StudentID升序排序,

Sort组件还能对排序的键值去重,这意味着,Sort组件会把排序键值重复的数据行丢弃,输出的结果中排序键值是唯一的,这可以通过两种方式来实现:
勾选“Remove rows with duplicate sort values”,或者把EliminateDuplicates属性设置为True:


2,设置连接类型
Merge Join支持三种类型,默认类型是Inner join,可以在Join type列表中选择连接类型。

3,连接条件
Merge Join转换组件自动按照排序列设置连接条件,对相同位置的列进行比较,如果所有列的值都对应相等,那么匹配成功;只要有一列不等,就匹配失败。
例如,Merge Join组件自动创建连接条件,连接条件是两个输入之间的连线,用于连接条件种的列的Join Key复选框都是勾选的。

4,设置输出列
为Merge Join的组件设置输出列和输出列的别名。

合并连接和查找转换的不同之处在于,合并连接是通过数据流接收参考数据(即查找数据),而不是通过转换组件的属性直接配置的,并且两个输入必须是有序的,同时,必须使用相同的列集,并以相同的顺序进行排序。
相对于查找转换,合并连接转换通常使用更少的内存,因为它只需要维护内存中用来支持连接两个输入流所需要的几行数据,然而,它不支持短路执行,这是因为,在该组件完成工作之前,两个管道需要对输入流的所有内容进行流处理。
Merge Join不支持短路操作,我举个例子,第一个输入有5行数据,而第二个输入有100万行数据,当Merge Join转换组件处理完成第一个输入的5行数据之后,该组件仍然会对来自第二个输入的其他数据进行流处理,即使它们不可能再被连接了。
二,关系连接
在关系数据库中,使用基于集合的方式把多个表连接起来以完成连接操作,一般来说,只要数据在相同的数据库实例中,就没有必要把数据移动到SSIS引擎中执行连接操作,关系连接的性能是最佳的,应充分利用关系数据库的优势来准备数据。
对比关系连接和SSIS连接,主要有五个不同的地方:
- 关系连接是原子的,该操作要么全部完成,要么全部失败;而SSIS连接不是原子的,执行转换的多个阶段是可以独立的完成或失败。
- 关系连接的输出是单个的,SSIS连接可以配置两个输出,如果指定左外连接,那么SSIS连接可以把把匹配的数据和不匹配的数据分开,还能输出错误消息。
- 关系连接使用基于集合的方式来连接多个表,并能利用数据库引擎存储的统计信息来优化查询,而SSIS连接是逐行进行数据匹配的。
- 关系连接一次可以连接多个表,而SSIS连接一次只能连接两个表。
- 关系连接不需要数据是有序的,而SSIS的合并连接转换需要两个输入都是有序的,排序操作有时是非常耗费资源和时间的。
关系连接的性能要比SSIS连接提高很多,一般来说,只要数据在相同的数据库实例中,那么关系连接就是首选。然而,如果输入的数据不在同一个数据库实例中,可以使用暂存表,先把所需要的数据都导入导同一个数据库中,后做关系连接。
参考文档:
微软BI 之SSIS 系列 - Merge, Merge Join, Union All 合并组件的使用以及Sort 排序组件同步异步的问题