前言
后缀自动机(Suffix Automaton, SAM)是一个能解决许多字符串相关问题的数学模型。
需要注意的是,自动机不是算法,也不是数据结构,而是一种数学模型。实现同一种自动机的方法不同可能会造成时空复杂度不同。
以下问题都可以在线性时间内通过 SAM 解决:
-
在另一个字符串中搜索一个字符串的所有出现位置。
-
计算给定的字符串中有多少个不同的子串。
定义与性质
基础定义
字符串 \(s\) 的 SAM 是一个接受 \(s\) 所有后缀的最小 DFA(确定性有限状态自动机)。
即:
- SAM 是一张边上标有字符的有向无环图。
- 节点被称作状态,边称为状态间的转移。
- 从每个节点出发的转移均不同。
- 存在一个起始状态 \(st\) 和若干个终止状态。从 \(st\) 开始不断转移到达终止状态时,路径上所有转移连接起来形成 \(s\) 的一个后缀,且 \(s\) 的每一个后缀均对应一条从 \(st\) 到某个终止状态的路径。
- 在所有满足上述条件的自动机中,SAM 的节点数最小。
按照上述定义,我们可以推导出:对于同一个状态,所有以该状态为终点的转移边上字符应该相同。
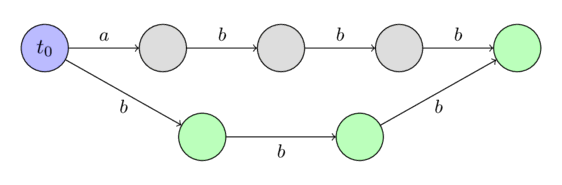
下图是 \(s=\texttt{abbb}\) 时的后缀自动机。我们用绿色节点表示终止状态,用节点 \(t_0\) 来表示起始状态 \(st\)。
子串性质
另外,SAM 具有一个重要的关于子串的性质。
因为 SAM 接受 \(s\) 的所有后缀,而 \(s\) 的子串一定是 \(s\) 某个后缀的前缀,所以对于字符串 \(s'\),当 \(s'\) 是 \(s\) 的子串时,存在一条从 \(st\) 到某个节点的路径,路径上所有转移连接起来的字符串和 \(s'\) 相同。
同时,当 \(s'\) 不是 \(s\) 的子串时,我们也可以证明这样的路径不存在。注意到:
- 如果这条路径是 \(st\) 到某个终止状态的路径(设这条路径对应的字符串是 \(p\))的子路径,那么这条路径对应的字符串一定是 \(s\) 的后缀 \(p\) 的一个前缀,即 \(s\) 的一个子串。
- 如果这条路径不是任何 \(st\) 到终止状态的路径的子路径,那么必然可以删掉若干个节点,使得 SAM 的节点数更小,这和「SAM 的节点数是所有符合条件的自动机中最小的」这一定义矛盾。
结束位置 endpos
字符串 \(s\) 的非空子串 \(s'\) 在 \(s\) 中所有的结束位置构成的集合记作 \(\operatorname{endpos}(s')\)。
例如,当 \(s=\texttt{ababa}\) 时,\(\operatorname{endpos}(\texttt{aba})=\{3,5\}\)。
这样,\(s\) 的所有非空子串都可以通过它们的 \(\operatorname{endpos}\) 来划分成若干个等价类。
关于 \(\operatorname{endpos}\),有以下几个显然但十分重要的引理。
-
引理 \(1\)
对于 \(s\) 的两个非空子串 \(a,b\)(\(|a| \leq |b|\)),如果 \(\operatorname{endpos}(a)=\operatorname{endpos}(b)\),那么 \(a\) 是 \(b\) 的后缀;如果 \(a\) 是 \(b\) 的后缀,那么 \(\operatorname{endpos}(b) \subseteq \operatorname{endpos}(a)\)。
-
证明
前半句显然。对于后面半句,考虑到对于任意字符串 \(t\),\(t\) 的出现次数一定不超过 \(t\) 的每个真后缀(不与 \(t\) 相等的后缀)的出现次数。因为 \(t\) 每次出现意味着 \(t\) 的每个真后缀的出现,而反之则不一定成立,所以两者的 \(\operatorname{endpos}\) 集合是包含关系。
-
-
引理 \(2\)
对于 \(s\) 的两个非空子串 \(a,b\)(\(|a| \leq |b|\)),如果 \(a\) 是 \(b\) 的后缀,那么 \(\operatorname{endpos}(b) \subseteq \operatorname{endpos}(a)\),否则 \(\operatorname{endpos}(a) \cap \operatorname{endpos}(b) = \varnothing\)。
-
证明
前半句参见引理 \(1\)。
对于后面,更长的 \(b\) 肯定不能和一个比它短还不是它后缀的 \(a\) 在同一个结束位置出现。
-
-
引理 \(3\)
同一个 \(\operatorname{endpos}\) 等价类中的字符串的长度互不相同且连续。
-
证明
对于命题的前半部分,考虑反证法。由引理 \(1\),假设等价类中存在两个不同的长度相同的字符串,那么这两个字符串互为后缀,因此这两个字符串是相同的,这和假设矛盾。
对于命题的后半部分,设等价类中最长的字符串为 \(u\),最短的字符串为 \(w\)。由引理 \(1\),\(w\) 一定是 \(u\) 的后缀。因为 \(w\) 和 \(u\) 在同一个等价类中,因此 \(u\) 所有比 \(w\) 长的后缀也一定在这个等价类中。
-
后缀链接 link
等价类的定义之后,我们规定,SAM 中的所有状态对应的字符串必须属于同一 \(\operatorname{endpos}\) 等价类。容易发现,这样规定之后,SAM 的任何一个状态对应的所有字符串都是该状态对应的最长字符串的后缀。
对于 SAM 中不是 \(st\) 的状态 \(x\),记 \(\operatorname{longest}(x)\) 表示状态 \(x\) 对应的最长的字符串,记 \(\operatorname{len}(x) = |\operatorname{longest(x)}|\)。我们称状态 \(x\) 的最长对应串为 \(\operatorname{longest}(x)\)。
设 \(sx\) 为 \(\operatorname{longest}(x)\) 最长的和 \(\operatorname{longest}(x)\) 不在同一个等价类中的后缀,则 \(x\) 的后缀链接 \(\operatorname{link}(x)\) 指向最长对应串为 \(sx\) 的状态。
-
引理 \(4\)
对于 SAM 中不是 \(st\) 的状态 \(x\),\(\operatorname{link}(x)\) 一定存在且唯一。
-
证明
由引理 \(1\) 和后缀链接的定义,\(sx\) 一定是其所属等价类中最长的字符串。又因为 SAM 的子串性质,所以一定存在状态使得该状态对应的字符串集合中包含 \(sx\),且该状态的最长对应串就是 \(sx\)。
如果 \(x\) 有多个后缀链接,那么这不满足 SAM 的最小性。
-
-
引理 \(5\)
将 SAM 上除 \(st\) 外所有节点的后缀链接和它连边,会形成一棵以 \(st\) 为根的有根树。
-
证明
只需要注意到,\(x\) 每经过一次后缀链接,状态的最长对应长度便至少减少 \(1\),这样一定会到达最长对应为空串的节点 \(st\)。
-
-
引理 \(6\)
如果我们令空串的 \(\operatorname{endpos}\) 为 \(\{-1,1,2,\cdots,|s|\}\),那么通过 \(\operatorname{endpos}\) 构造的树(每个节点父亲的最长对应串的 \(\operatorname{endpos}\) 真包含该节点最长对应串的 \(\operatorname{endpos}\) )和通过后缀链接构造的树相同。
-
证明
只需要注意到,如果字符串 \(t\) 的某个后缀 \(t'\) 和它不在一个等价类中,那么一定有 \(\operatorname{endpos}(t) \subsetneq \operatorname{endpos}(t')\)。
而 \(\operatorname{longest}(\operatorname{link}(x))\) 是 \(\operatorname{longest}(x)\) 的后缀且和它不在一个等价类中,因此对于状态 \(x\),\(\operatorname{link}(x)\) 对应的状态就是 \(x\) 在 \(\operatorname{endpos}\) 树上的父节点。
-
SAM 的线性构造
我们可以在线性时间内维护 \(\operatorname{link}\) 从而构造 SAM。在构造时,我们先构造出 \(s[1,i-1]\) 的 SAM,然后尝试加入 \(s_i\)。在加入 \(s_i\) 时,我们默认之前的所有构造是正确的。
记 \(\operatorname{last}\) 表示 \(s[1,i-1]\) 对应的状态。首先我们新建一个节点 \(\operatorname{cur}\) 表示现在的状态。
我们需要计算 \(\operatorname{link(cur)}\),并且因为 \(s[1,i]\) 的所有后缀新出现了一次,所以我们还需要维护 \(s[1,i]\) 所有后缀的后缀链接,这需要找出 \(s[1,i]\) 后缀的所有等价类。事实上,沿着 \(\operatorname{last}\) 的后缀链接向上遍历一直到根,那么有结论:
-
记途中经过所有状态的最长对应串为 \(f_1,f_2,\cdots,f_k\),那么我们会发现,\(f_j\) 所有和 \(f_j\) 在同一个等价类中的后缀 \(f'_j\),满足 \(f'_j+s_i\) 在同一个等价类中。
这是显然的。所有的 \(f'_j\) 总是同时出现,而 \(f'_j+s_i\) 会出现且仅出现在满足 \(s_{x+1}=s_i\) 且 \(x \in \operatorname{endpos}(f'_j)\) 的位置 \(x\)。
那么我们沿着 \(\operatorname{last}\) 的后缀链接向上遍历,经过一个节点 \(p\) 就找一下 \(p \to s_i\) 这个节点,它对应的就是 \(s[1,i]\) 的某个后缀的等价类了。根据上面的结论,我们不会漏掉某些等价类。
从 \(\operatorname{last}\) 开始不断遍历后缀链接,记当前节点为 \(p\),\(\operatorname{longest}(p)=x\)。接下来,我们需要分类讨论。
Case 1.1
如果 \(p\) 已经有出边 \(s_i\),设 \(p\) 经过出边转移到的节点为 \(q\)。此时我们需要继续分类讨论。
先来讨论 \(\operatorname{len}(p)+1=\operatorname{len}(q)\)。
此时,\(x+s_i\) 就是 \(\operatorname{longest}(q)\),我们只需要将 \(\operatorname{link}(\operatorname{cur})\) 设为 \(q\)。因为我们从下往上遍历,所以找到的一定是最长的 \(\operatorname{longest}(q)\)。
\(x+s_i\) 已经出现在了 SAM 中,因此 \(x+s_i\) 的所有后缀(它们也是 \(s[1,i]\) 的后缀)已经出现在了 SAM 中(想一想,为什么?),我们不需要继续遍历。
Case 1.2
再来讨论 \(\operatorname{len}(p)+1 < \operatorname{len}(q)\)。
此时,\(x+s_i\) 仍然是 \(s[1,i]\) 的最长后缀,但是 \(x+s_i\) 不再是 \(q\) 的最长对应串。
设 \(y=\operatorname{longest}(q)\),并设 \(r\) 表示通过 \(s_i\) 转移到 \(q\) 的节点中 \(\operatorname{longest}\) 最长的节点。显然,\(x+s_i\) 是 \(y\) 的后缀。因为 \(x+s_i\) 和 \(y\) 在同一等价类中且 \(y\) 比 \(x+s_i\) 长,但通过 \(\operatorname{last}\) 通过后缀链接先访问到的节点是 \(p\) 而不是 \(r\),这说明了 \(y\) 不是 \(s[1,i]\) 的后缀。
此时,\(x+s_i\) 的 \(\operatorname{endpos}\) 中新增了 \(i\),而 \(y\) 不是 \(s[1,i]\) 的后缀,因此 \(x+s_i\) 的所有后缀和 \(y\) 不应属于一个等价类中。我们需要新建一个节点 \(\operatorname{clone}\),复制 \(q\) 除了 \(\operatorname{len}\) 之外的所有信息。我们继续遍历 \(p\) 的后缀链接,将所有连向 \(q\) 的状态重定向到 \(\operatorname{clone}\),然后将 \(\operatorname{link(cur)}\) 设置为 \(\operatorname{clone}\)。这样,我们保证了 SAM 的正确性。
值得一提的是,在遍历后缀链接的过程中,我们可以找到第一个出边 \(s_i\) 不转移到 \(q\) 的状态就停止。如果这个状态的出边 \(s_i\) 不转移到 \(q\),那么之后所有状态的出边 \(s_i\) 都不可能转移到 \(q\)。这是因为遍历后缀链接时,状态的最长对应串长度会减少,可能会成为更多后缀的子串。而出边 \(s_i\) 如果不转移到 \(q\),那么说明找到了一个比 \(q\) 「更强」的状态可供转移。之后的状态要么转移到这个状态,要么转移到比这个状态还「强」的状态,不可能转移到 \(q\)。
和第一种情况一样,此时我们也不需要继续遍历。但有一个疑问仍然存在:如果 \(p\) 的某个祖先 \(p'\) 的出边 \(s_i\) 指向异于 \(q\) 的一个节点 \(w\),而 \(\operatorname{len}(p')+1<\operatorname{len}(w)\),我们不应该执行同样的操作,将 \(w\) 分成两个部分吗?
事实上,这种情况不会存在。
考虑到,如果 \(\operatorname{len}(p')+1<\operatorname{len}(w)\),那 \(\operatorname{longest}(p')+s_i\) 是 \(\operatorname{longest}(w)\) 的后缀。
设通过出边 \(s_i\) 转移到 \(w\) 的点中 \(\operatorname{len}\) 最长的是 \(r\),那么通过和之前一样的策略,能够证明 \(\operatorname{longest}(r)\) 不是 \(s[1,i]\) 的后缀。
但是 \(\operatorname{longest}(p')+c\) 是 \(\operatorname{longest}(w)\) 的后缀,两边去掉最后一个字符,\(\operatorname{longest}(p')\) 是 \(\operatorname{longest}(r)\) 的后缀。
于是 \(\operatorname{longest}(r)\) 必须要比 \(\operatorname{longest}(p)\) 长(因为 \(p\) 自己是 \(s[1,i]\) 的后缀,但 \(\operatorname{longest}(r)\) 不是 \(s[1,i]\) 的后缀),然而这是不可能的。这样的串在 \(q\) 进行复制操作的时候就已经被分离出来了,不可能在向上遍历的过程中再次出现。
Case 2
最后,来考虑 \(p\) 没有出边 \(s_i\) 的情况。
此时我们无法找到 \(\operatorname{link(cur)}\)。因为我们需要在 SAM 中保存所有子串的信息,但此时不存在 \(x+s_i\) 对应的状态,因此我们需要将 \(p \to s_i\) 设置为 \(\operatorname{cur}\)。
此时我们需要继续遍历。
小结
对 \(s_1,s_2,\cdots,s_n\) 依次执行上述操作,便完成了 SAM 的构造。我们发现,上述构造除了最小性之外的正确性是显然的。
感兴趣的读者可以自行查阅最小性的证明。
复杂度证明
此处的证明不太严谨。事实上 SAM 的节点数和转移数都有不带 \(O\) 记号的准确上界,感兴趣的读者可以自行查阅。
SAM 的复杂度证明依赖于一个假设:字符集的大小 \(|\Sigma|\) 是常数。接下来,我们设 \(n = |s|\)。
空间复杂度
我们发现,每添加一个字符,最多增加两个状态,因此节点数是 \(O(n)\) 的;每个节点对应字符的转移边最多被添加一次,因此边数也是 \(O(n)\) 的(别忘了字符集大小是常数!)。
时间复杂度
有两处的时间复杂度还不太清晰:
-
遍历 \(\operatorname{last}\) 的所有后缀链接,找到第一个有字符 \(s_i\) 出边的状态 \(p\)
这取决于有多少个状态没有字符 \(s_i\) 的出边。因为一个出边被加入就不会被删除,因此总复杂度是均摊 \(O(n)\) 的:节点数是 \(O(n)\),字符集是常数。
-
遍历 \(p\) 的后缀链接,将出边重定向到 \(\operatorname{clone}\)
我们可以证明,\(\operatorname{cur}\) 的后缀链接链是 \(\operatorname{last}\) 的后缀链接链上的状态通过一条 \(s_i\) 出边到达的状态所组成集合的子集。因此,如果我们把多个状态的出边重定向到同一个状态,那么 \(\operatorname{cur}\) 的后缀链接链的长度上界减小。
设 \(k_i\) 表示添加第 \(i\) 个字符时,出边被重定向到 \(\operatorname{clone}\) 的状态个数;\(l_i\) 表示 \(s[1,i]\) 对应状态的后缀链接长。那么我们有 \(l_i \leq l_{i-1}+(k_i-1)\)。同时,我们有 \(l_i \geq 1\) 和 \(l_{i} \leq l_{i-1}+1\),因此,\(l_i\) 最多增加 \(n\),所以 \(\sum \limits_{i=1}^{n} k_i -1 \leq n\),于是 \(\sum \limits_{i=1}^{n} k_i\) 是 \(O(n)\) 的。这正是我们要证明的。
代码(主体部分)
inline void sam_insert(int c){
int p=last;
int now=++tot;
sam[now].len=sam[last].len+1;
size[now]=1;
while(p&&(!sam[p].nex[c]))
sam[p].nex[c]=now,p=sam[p].link; // case2: 对应节点没有出边 c
last=now;
if(!p){ // 一个有出边的 c 都没有
sam[now].link=1;
return;
}
if(sam[p].len+1==sam[sam[p].nex[c]].len){ // case1.1
sam[now].link=sam[p].nex[c];
return;
}
int clone=++tot,qnode=sam[p].nex[c]; // case1.2
sam[clone]=sam[qnode];
sam[clone].len=sam[p].len+1; // 全部复制
sam[qnode].link=clone,sam[now].link=clone; // 更新 link
while(p&&sam[p].nex[c]==qnode){ // 重定向到 clone
sam[p].nex[c]=clone,p=sam[p].link;
}
return;
}