5、列表+元组+字典
一、列表类型
作用:多个装备,多个爱好,多门课程,多个女朋友
定义: []内可以有多个任意的值,逗号分隔
my_habbies = ['study','reading','money','woman']
l = list('abc)>>>>>['a','b','c']
优先掌握的操作:
1、按索引存取值(正向存取+反向存取):即可存也可以取
2、切片(顾头不顾尾,步长)
l=[11,22,33,44,55,66,77]
l[0:6:2]
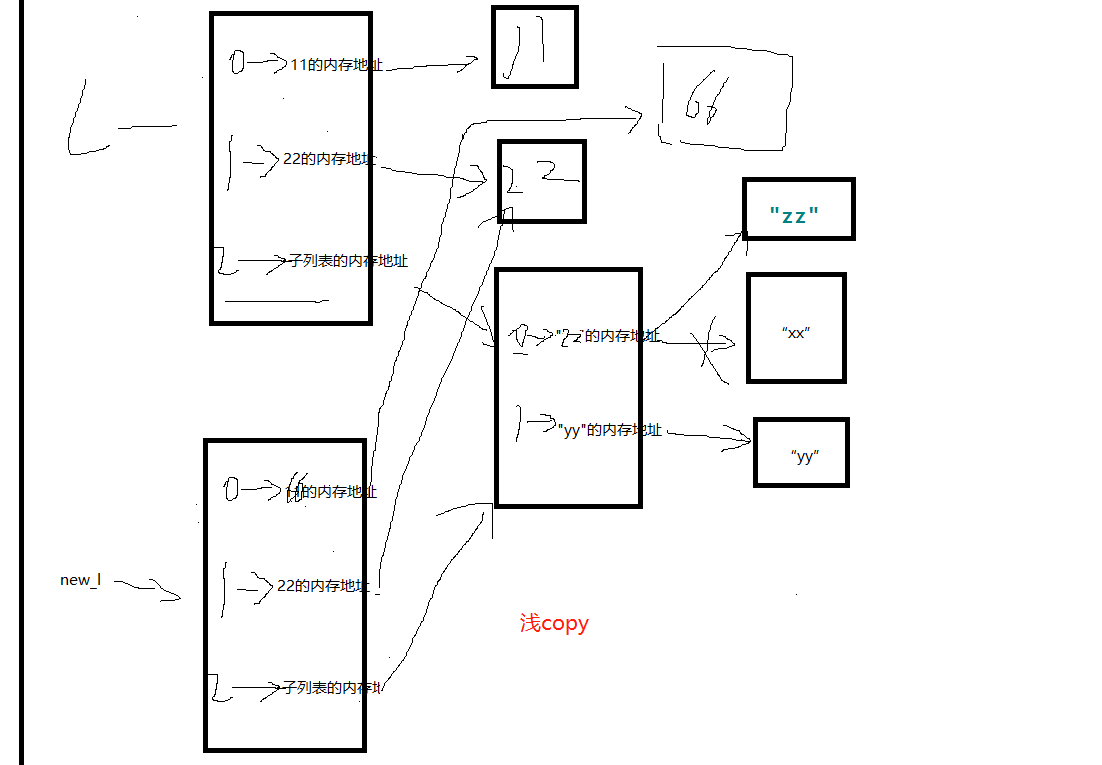
new_l = l[:] ` 相当于复制一个l 不过是浅copy
l = [11, 22, ["xx", "yy"]]
new_l = l[:]
new_l[0] = 66
new_l[2][0]='zz'
print("新列表",new_l)
print("原列表",l)
**新列表 [66, 22, ['zz', 'yy']]**
**原列表 [11, 22, ['zz', 'yy']]**
浅拷贝(shallowCopy)只是增加了一个指针指向已存在的内存地址,
深拷贝(deepCopy)是增加了一个指针并且申请了一个新的内存,使这个增加的指针指向这个新的内存,
from copy import deepcopy(深拷贝)
new_l1 = deepcopy(l)
print(id(l[0]), id(l[1]), id(l[2]))
print(id(new_l1[0]), id(new_l1[1]), id(new_l1[2]))
new_l1[2][0]="zzzzz"
print(new_l1)
print(l)
deepcopy会拷贝子列表的索引,有多少循环就会一直拷贝下去,改变copy 的值不会影响原值
3、长度
len(l)
4、成员运算in和not in
5、追加
l.append(值) 加在末尾
l.insert(索引,值) 指定位置插入
6、删除
del l[0]
l.remove(元素)
res = l.pop(索引)
7、循环
for x in l:
print(x)
for i,x in enumerate(l):
print(i,x)
需要掌握的操作(****)
l=[11,22,33,44,33,33,55]
new_l = l.copy() # new_l = l[:]
print(len(l)) # l.__len__()
1、判断是否存在 不存在会报错
####2、出现的次数
l.count() 出现的次数
print(l.count(33))
3、清空列表
l.clear()
l.clear()
print(l)
4、可插入多个值l.extend()
l.extend("hello") 插入的为'h','e','l','l','o'
l.extend([1,2,3]) 插入的为'1','2','3'
l.append([1,2,3]) 插入的为[1,2,3]
print(l)
5、颠倒顺序
l.reverse()
l.reverse()
print(l)
6、排序
l.sort()
l=[11,-3,9,7,99,73]
l.sort(reverse=True)
print(l)
列表相关总结
1、可存多个值
2、有序
3、可变
二、元组类型
元组tuple基本使用
1、用途:元组就相当于一种不可变的列表,所以说元组也是按照位置存放多个任意类型的元素
2、定义方式:在()内用逗号分隔开个多个任意类型的元素
x=(11)
print(x,type(x))
t=(11,11.33,"xxx",[44,55]) # t = tuple(...)
print(t[-1][0]) >>>44
print(type(t)) >>>><class,'tuple'>
数据类型转换
tuple(可迭代的类型)
注意:如果元组内只有一个元素,那么必须用逗号分隔
t=(11,)
print(type(t))
3、常用操作+内置的方法
优先掌握的操作:
1、按索引取值(正向取+反向取):只能取
t=(11,22,33)
t[0]=7777
2、切片(顾头不顾尾,步长)
t=(11,22,33,44,55,666)
print(t[0:4:2])
t=(11,22,33,44,55,666)
print(len(t))>>>>>6
4、成员运算in和not in
t=(11,22,33,[44,55,666])
print([44,55,666] in t)
5、循环
t=(11,22,33,[44,55,666])
for x in t:
print(x)
需要掌握
t=(33,22,33,[44,55,666])
print(t.count(33))
print(t.index(33,1,4))>>>>>1,4是判断从索引1 到索引4之间
==该类型总结
存多个值
有序
不可变
t=(11,22,[33,44])
t[2]=777
print(id(t[0]),id(t[1]),id(t[2]))
t[2][0]=777
print(t)
print(id(t[0]),id(t[1]),id(t[2]))
三、字典基本使用
1、用途:按照key:value的方式存放多个值,其中key对value应该有描述性的效果
2、定义方式:在{}内用逗号分隔开多个元素,每个元素都是key:value的组合,其中value可以是任意类型
但是key必须是不可变类型,通常是字符串类型,并且key不能重复
d={1:111111,1.1:22222222222,"k1":333333,(1,2,3):44444444,[1,2,3]:5555} # d=dict(...)
print(d[1])
print(d[1.1])
print(d[(1,2,3)])
3、数据类型转换
res = dict([("name","egon"),["age",18],["gender","male"]])
print(res)>>>>>>{'name': 'egon', 'age': 18, 'gender': 'male'}
res = dict(a=1,b=2,c=3)
print(res)>>>>>>>{'a': 1, 'b': 2, 'c': 3}
d={}
d=dict()
print(type(d))>>>>>>><class 'dict'>
只改变name,其他不会变
res = {}.fromkeys(['name',"age","gender"],None)
res = {}.fromkeys(['name',"age","gender"],11)
res["name"]=666
print(res)>>>>>>>>{'name': 666, 'age': 11, 'gender': 11}
用append()添加,其他也会跟着变
res = {}.fromkeys(['name',"age","gender"],[])
res["name"].append(1111111)
print(res)>>>>>>>{'name': [11111], 'age': [11111], 'gender': [11111]}
3、常用操作+内置的方法
优先掌握的操作:
1、按key存取值:可存可取
d={"k1":111,'k2':222}
print(d['k1'])
d['k1']=6666
d['k3']=6666
print(d)>>>>>>>{'k1': 6666, 'k2': 222, 'k3': 6666}
2、长度len
d={"k1":111,'k2':222}
print(len(d))>>>>>>2
3、成员运算in和not in: 判断的是key
d={"name":"egon",'age':18}
print("name" in d)
4、删除
d={"name":"egon",'age':18}
print(d)
del d["name"]
v = d.pop("name")
print(d)
print(v)
item = d.popitem()
print(item)
print(d)
5、键keys(),值values(),键值对items()
d={"name":"egon",'age':18,"gender":"male"}
print(d.keys())>>>>>dict_keys(['name', 'age', 'gender'])
print(d.values())>>>>dict_keys(['name', 'age', 'gender'])
print(d.items())>>>>>dict_keys(['name', 'age', 'gender'])
6、循环
d={"name":"egon",'age':18,"gender":"male"}
for k in d.keys():
print(k)
>>>>>name
>>>>>age
>>>>>gender
for k in d:
print(k)
>>>>和d.key()相同
for v in d.values():
print(v)
>>>>egon
>>>>18
>>>>male
for k,v in d.items(): # k,v = ('gender', 'male'),
print(k,v)
>>>>>name egon
>>>>>age 18
>>>>>gender male
转成列表格式
print(list(d.keys()))
print(list(d.values()))
print(list(d.items()))
7、d.get()
d={"name":"egon",'age':18,"gender":"male"}
print(d["xxx"])>>>>无 报错
print(d.get("xxx"))>>>>无输出None
需要掌握(****)
d={"name":"egon",'age':18,"gender":"male"}
d.clear()
print(d)
d.copy() # 浅copy
d={"name":"egon",'age':18,"gender":"xxx"}
key不存在则添加key:value,key如果存在则什么都不做
if "gender" not in d:
d['gender']="male"
key不存在则添加key:value,key如果存在则什么都不做
d.setdefault("gender","male")
print(d)
.update()更新
d={"name":"egon",'age':18,"gender":"male"}
d.update({"k1":111,"name":"xxx"})
print(d)
==该类型总结
存多个值
无序
可变
d={'k1':111}
print(id(d))
d['k1']=2222222
print(id(d))