一、认识SQL:
1.什么是SQL?
- Structured Query Language:结构化查询语言
- 其实就是定义了操作所有关系型数据库的规则。每一种数据库操作的方式存在不一样的地方,称为“方言”。
2.SQL通用语法:
- SQL语句可以单行或多行书写,以分号结尾。
- 可使用空格和缩进来增强语句的可读性
- MySQL数据库的SQL语句不区分大小写,关键字建议使用大写。
- 三种注释:
-
- 单行注释①:-- 注释内容(注意--后面有一个空格)
- 单行注释②:#注释内容(mysql特有)
- 多行注释:/*注释内容*/
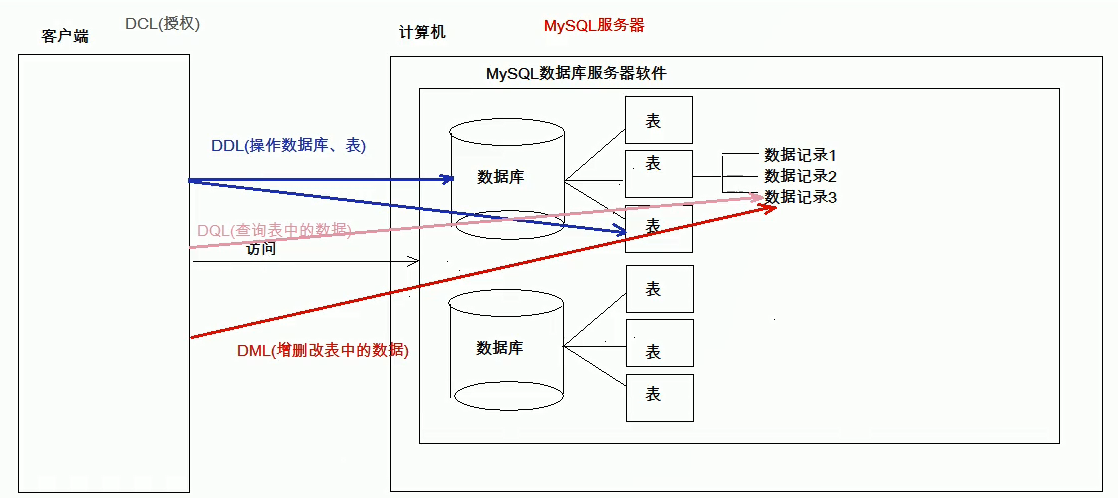
3.SQL的分类:
①:DDL:数据定义语言,用来定义数据库对象:数据库、表、列等。
关键字:create、drop、alter等
②:DML:数据库操作语言,用来对数据库中表的数据进行增删改。
关键字:insert、delete、update等
③:DQL:数据查询语句,用来查询数据库中表的记录(数据)。
关键字:select、where等
④:DCL:数据库控制语言(了解),用来定义数据库的访问权限和安全级别,以及创建用户。
关键字:GRANT,REVOKE等
图解这四种SQL语言:
二、DDL:
*****操作数据库:CRUD
1、C(Create):创建:
- ①创建数据库:
- create database 数据库名称;
- ②创建数据库,判断不存在,再创建,存在则不创建:
- create database if not exists 数据库名称;
- ③创建数据库,并指定字符集:
- create database 数据库名称 character set 字符集名;
- ④创建数据库,判断是否存在并指定字符集:
- create database if not exists 数据库名称 character set 字符集名;
2、R(Retrieve):查询:
①查询所有数据库的名称:
show databases;
②查询某个数据库的字符集:查询某个数据库的创建语句
show create database 数据库名称;
3、U(Update):修改:
①修改数据库的字符集:
alter database 数据库名称 character set 字符集名;
4、D(Delete):删除:
①删除数据库:
drop database 数据库名称;
②判断数据库存在,就删除:
drop database if exists 数据库名称;
5、使用数据库:
①查询当前正在使用的数据库名称:
select database();
②使用数据库:
use 数据库名称;
*****操作表:
1、C(Create):创建:
①语法:
create table 表名(
列名1 数据类型1,
列名2 数据类型2,
。。。
列名n 数据类型n
);注意最后一行不能有“,”号。
②数据库类型:
1、int 整数类型:age int,
2、double 小数类型:score double(5,2)表示一共五位,小数点后有两位,比如111.11。
3、data 日期,只包含年月日,yyyy-MM-dd
4、datatime 日期,包含年月日时分秒,yyyy-MM-dd HH:mm:ss
5、timestamp 时间错类型,包含年月日时分秒,yyyy-MM-dd HH:mm:ss(如果将来不给这个字段赋值,或赋值为null,则默认使用当前的系统时间,来自动赋值)
6、varchar 字符串,name varchar(n),n表示姓名最大字符
创建实例:
create table student(
id int,
name varchar(32),
age int,
score double(4,1),
birthday data,
insert_time timestamp
);
③创建一个现有表的复制品:
create table 表名 like 复制的表名
2、R(Retrieve):查询:
①查询某个数据库中所有的表名称:
show tables;
②查询表结构:
desc 表的名字;
3、U(Update):修改:
①:修改表名:
alter table 表名 rename to 新表名;
②:修改表的字符集:
alter table 表名 character set 字符集名称;
③:添加一行:
alter table 表名 add 列名 数据类型;
④:修改列名称、类型:
alter table 表名 change 列名 新列名 新数据类型;
alter table 表名 modify 列名 新数据类型;
⑤:删除列:
alter table 表名 drop 列名;
4、D(Delete):删除:
①删除表:
drop table 表名;
②加一个判断:
drop table if exists 表名;
三、DML(增删改查表中数据):
1、添加数据:
语法:insert into 表名(列名1,列名2....列名n)values(值1,值2...值n);
注意:
- 列名和值要一一对应。
- 如果表名后,不定义列名,则默认给所有列添加值:insert into 表名 values(值1,值2....值n);
- 除了数字类型,其他类型需要使用引号引起来。
2、删除数据:
语法:delete from 表名 【where 条件】
注意:
- 如果不加where条件,则会把表中所有记录删除。
- 如果要删除所有记录有两种方法:
- delete from 表名;——不推荐使用,因为表中有多少记录就会执行多少次删除操作,效率太低。
- truncate table 表名;——推荐使用,因为他的原理是先删除表,再创建一张一样的空表,效率高。
3、修改数据:
语法:updata 表名 set 列名1 = 值1,列名2 = 值2,...【where 条件】
注意:
- 注意如果不加上while条件,则会修改表中所有数据。
四、DQL(查询语句):
查询表中的记录:select * from 表名;
语法:
select
字段列表
from
表名列表
where
条件列表
group by
分组字段
having
分组之后的条件
order by
排序
limit
分页限定
1、基础查询:
1.多个字段的查询
select 字段名,字段名2...from 表名;
注意:
如果查询所有字段,则可以使用*来代替字段列表
2.去除重复:
distinct:delect distinct age from st;
3.计算列
一般可以使用四则运算计算一些列的值。
ifnull(表达式1,表达式2):null参与的运算,计算结果都是null
表达式1:哪个字段需要判断是否为null;
如果该字段为null,后的替换值。
4.起别名
as:可以省略。
2、条件查询:
1、where子句后面跟条件
2、运算符:
>、<、<=、>=、=、<>(不等于,也可以写成!=)
between ...and...(比如between 20 and 30,包含20和30)
in(集合,可以放多个查询条件)
like(模糊查询),_表示一个位置,%表示多个位置。
比如“刘”开头的人:select from st where name like ‘马%’;
比如第二个字为“小”的人:select from st where name like ‘_小%’;
比如名字中包含“王”的人:select from st where name like “%王%”;
is null和is not null
and 或 &&
or 或 ||
not 或 !
3、排序查询:
语法:select from 表名 order by 子句 排序方式(不写默认ASC);
order by 排序字段1 排序方式1,排序字段2,排序方式2....
排序方式:
ASC:升序,默认。
DESC:降序。
注意:
如果有多个排序条件,则当前边的条件值一样时,才会判断第二条件。
4、聚合函数:将一列数据作为一个整体,进行纵向计算。
- count:计算个数 (①一般选择非空的列:主键。②count(*)不推荐)
- max:计算最大值
- min:计算最小值
- sum:计算和
- avg:计算平均数
注意:聚合函数的计算,排除null值。(因此在计算个数的时候,选择了有空值的列,会导致空值列不被计算个数)
解决方案:
1、选择不包含非空的列激进行计算。
2、IFNULL函数来将非空的变为0:IFUNLL(列名,0)。
5、分组查询:
1、语法:group by 分组字段;
2、注意:
1.分组之后查询的字段:分组字段、聚合函数
2.where和having的区别?
1.where在分组之后进行限定,如果不满足条件,则不参与分组。having在分组之后进行限定,如果不满足结果,则不会被查询出来。
2.where后不可以跟聚合函数,having可以进行聚合函数的判断。
例子:
---按照性别分组。分别查询男、女生的平均分,人数:
select sex,AVG(math),count(id) from st group by sex;
---按照性别分组,分别查询男、女生的平均分,人数。要求:分数低于70分的人,不参与分组:
select sex,avg(math),count(id) from st where math > 70 group by sex;
---按照性别分组,分别查询男、女生的平均分,人数。要求:分数低于70分的人,不参与分组,分组之后,人数要大于两个人。
select sex,avg(math),count(id) from st where math > 70 group by sex having count(id)> 2;
当然也可以起一个别名:
select sex,avg(math),count(id) renshu from st where math > 70 group by sex having renshu> 2;
6、分页查询:
1.语法:limit 开始的索引,每页查询的条数;
2.开始的索引 = (当前的页码 - 1) * 每页显示的最大条数
比如:
select * from st limit 0,3;--第一页
select * from st limit 3,3;--第二页
select * from st limit 6,3;--第三页
3.分页操作是一个MYSQL的“方言”,只能在MYSQL中使用。