我发现找出标准流用的是什么缓冲是一件困难的事。
例如下面这个使用unix shell 管道的例子:
$ command1 | command2
下图显示了shell fork了两个进程并通过一个管道将他们联系起来。在这个连接中移动使用了三个缓冲.
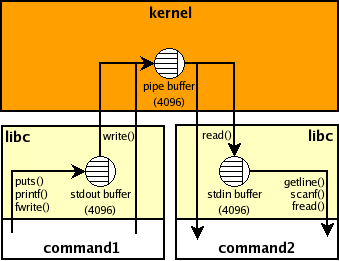
内核中的缓冲区室友pipe系统函数生成的,它的大小取决于操作系统的页大小。我们无法也没必要控制这个缓冲区的大小,因为它会立即转送数据(至少在linux上是这样)。[更新:这个pipe buffer 已经变化为 circular buffers (16 x 4KiB)并且有一个新的 proposed patch 使得它的大小是动态的]
另外两个缓冲是关于流的,为了提高效率,仅仅在第一次使用流的时候申请缓冲区空间。三个标准流(stdin, stdout, stderr)会在几乎所有的unix GNU C程序开始执行自动被创建,新的流也可以被创建用来连接文件、套接字、管道等等。你可以通过控制缓冲策略(无缓冲,行缓冲,满缓冲)来控制数据的读写方法。我使用这个程序来确定标准流的默认缓冲区的特性:
/* Output info about the default buffering parameters
* applied by libc to stdin, stdout and stderr.
* Note the info is sent to stderr, as redirecting it
* makes no difference to its buffering parameters.
* Note gnulib has fbufmode() to make this portable.
*/
#include <stdio_ext.h>
#include <unistd.h>
#include <stdlib.h>
FILE* fileno2FILE(int fileno){
switch(fileno) {
case 0: return stdin;
case 1: return stdout;
case 2: return stderr;
default: return NULL;
}
}
const char* fileno2name(int fileno){
switch(fileno) {
case 0: return "stdin";
case 1: return "stdout";
case 2: return "stderr";
default: return NULL;
}
}
int main(void)
{
if (isatty(0)) {
fprintf(stderr,"Hit Ctrl-d to initialise stdin
");
} else {
fprintf(stderr,"Initialising stdin
");
}
char data[4096];
fread(data,sizeof(data),1,stdin);
if (isatty(1)) {
fprintf(stdout,"Initialising stdout
");
} else {
fprintf(stdout,"Initialising stdout
");
fprintf(stderr,"Initialising stdout
");
}
fprintf(stderr,"Initialising stderr
"); //redundant
int i;
for (i=0; i<3; i++) {
fprintf(stderr,"%6s: tty=%d, lb=%d, size=%d
",
fileno2name(i),
isatty(i),
__flbf(fileno2FILE(i))?1:0,
__fbufsize(fileno2FILE(i)));
}
return EXIT_SUCCESS;
}
默认缓冲策略:
- stdin总是缓冲的
- stderr总是无缓冲的
- 如果stdout是终端的话缓冲是行缓冲的,否则是满缓冲的。(补充一下,GNU里面定义的可交互设备,显然终端是可交互设备)
默认缓冲大小:
- 缓冲大小只会直接影响缓冲策略
- 内核的pipe buffer 已经变化为 circular buffers (16 x 4KiB)并且有一个新的 proposed patch 使得它的大小是动态的
- 如果stdin/stdout 连接的是交互设备那么默认大小是1024,否则是4096
stdio 输出缓冲的问题
现在来考虑一个问题:数据源的信息是间隔发送的,并且接受者希望立即收到新产生的数据。
例如,一个人想要过滤 tcpdump -l 或者 tail -f 的输出等等(注意有一些过滤器比如sort要求一次缓存所有数据到内部,所以这里不能使用)。
考虑下面这个操作,从动态网络日志终端数据中过滤出不一样的IP地址:
$ tail -f access.log | cut -d' ' -f1 | uniq
问题在于,如果按照上面这个命令,我们将不能实时的看到增加的主机IP,示例图如下:
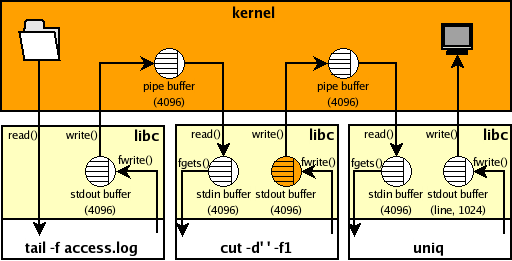
高亮的缓冲区导致了问题的发生。由于该缓存区连接了一个管道缓冲区,他会等到数据达到4096字节后再作为一个块传送给uniq。注意到tail的标准输出也有这个问题,但是tail -f调用会自动清除缓冲区当有新的数据输入时,所以这里不会产生影响( tcpdump -l, grep --line-buffered sed --unbuffered 也是这样)。另外,由于uniq标准输出连接的是一个可交互设备,所以当有新的一行数据到达时也会自动清除缓冲区,不会产生影响。
stdio 输入缓冲问题
正如向stdout一样,stdin也使用缓冲区以增加效率。
如果一个一个字节的读入显然会有更多控制的空间,但是这样是不实际的。
考虑以下命令:
$ printf "one
two
three
" | ( sed 1q ; sed 1q ; sed 1q )
one
(译者注:这里的q是sed流编辑器的退出命令,1q表示当输出到达第一行结束时退出。参考The q or quit command)
正如你所见到的,第一个sed进程读取了所有数据,导致后面的sed没办法读入数据。注意仅仅将stdin缓冲区设置为行缓冲是没有用的,因为只有当输出缓冲区被清除的时候才会产生控制效果(译者注,如果没有输出的话,第一个sed还是会”一行一行的把输入数据读完)。以上的sed标准输入都是行缓冲Reading lines from stdin.通常你只能控制一个进程能否从stdin读入数据,或者读入特定规模的数据然后禁止读入。以下是这样的一个例子:
$ printf "one
two
three
" | ( ssh localhost printf 'zero\n' ; cat )
zero
(译者注:后面的cat命令用于从stdin中读取数据输出到屏幕,防止printf的输出存储在缓冲区中。)
这个远程printf命令并不会从stdin读取数据(译者注:'zero
'是参数),但是ssh client并不知道这个,所以他会读取前面printf传入的数据即stdin中读取数据。为了告诉ssh远程命令不需要读入数据,可以加上-n这个参数:
$ printf "one
two
three
" | ( ssh -n localhost printf 'zero
' ; cat )
zero
one
two
three
常见的经历是你想要吧ssh放在后台当你知道远程命令不会读取数据的时候(利于常见的图像化程序),设置ssh client阻止读入数据可以防止远程应用程序停滞。你可以通过-f参数告诉ssh忽略stdin并且fork到后台。例如:ssh -fY localhost xterm(译者注:-Y Enables trusted X11 forwarding)。
stdio 缓冲控制
省略...(关键词:stdbuf, BUF_X_=Y where X = 0 (stdin), 1 (stdout), 2 (stderr) )