1.背景
最近Leetcode上答题时,遇到了Reservoir sampling 算法。挺有趣的。记录一下。
首先说一下,遇到的题目:
Given a singly linked list, return a random node's value from the linked list. Each node must have the same probability of being chosen.
根据上面的题目,我们立即可以想到,将linked list所有元素放入ArrayList中,然后用一个随机数,取出某一个元素。Bingo!问题解决。
不过,当题目中的Linkedlist中Node数目非常庞大时,也许上亿,那么怎么办,如果将所有元素放入内存之后,内存会耗光。
(工作中,当数据量级变大时,处理的方法,也要随之变化)
我们可以是使用蓄水池算法(reservoir sampling)来解决。
2.什么是reservoir sampling
它就是解决一个随机采样的问题。它很简单,常见,但是,非常慢。
下面是它的算法:
(* S has items to sample, R will contain the result *) ReservoirSample(S[1..n], R[1..k]) // fill the reservoir array for i := 1 to k R[i] := S[i] // replace elements with gradually decreasing probability for i := k+1 to n (* randomInteger(a, b) generates a uniform integer from the inclusive range {a, ..., b} *) j := randomInteger(1, i) if j <= k R[j] := S[i]
时间复杂度:
接下来,是我对上面算法的推导(为什么这个算法可以确保每个元素被取出的概率是一样的):
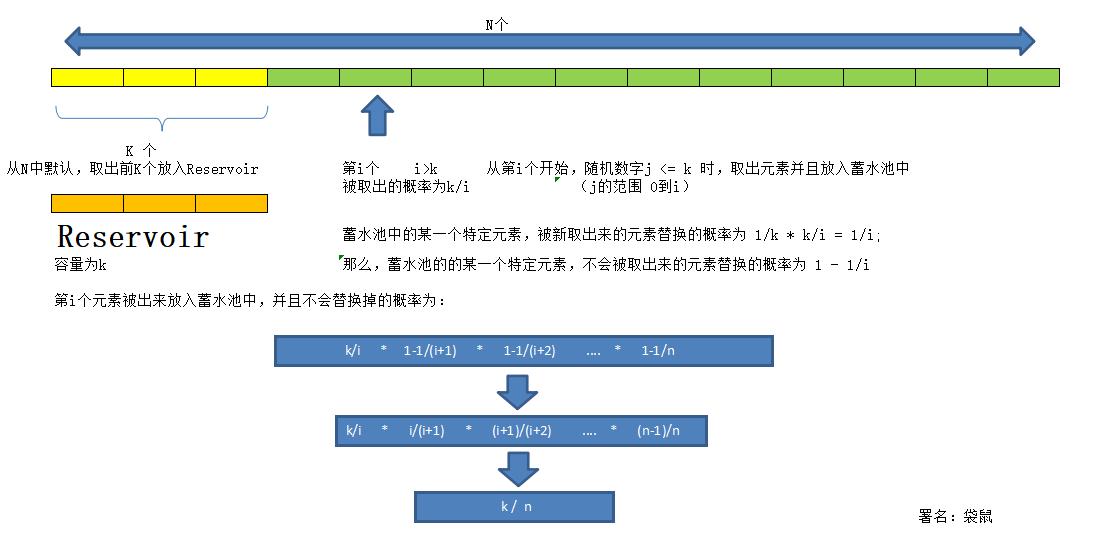
(短短的几行推导,我也是花了些时间才弄懂得,惭愧。但是,要感谢自己,感谢自己没有放弃。)
这个算法最大的问题是,如果数据量非常大的话,那么你惨了,你要等好久,才能等到算法执行完毕。
wiki中,还给出了许多优化,优化的算法,有兴趣的可以深入研究。
References:
https://en.wikipedia.org/wiki/Reservoir_sampling
https://leetcode.com/problems/linked-list-random-node/