1.在文章开头给出博客作业要求地址,码云项目地址。
https://gitee.com/nzlj/PersonalProject-Java
2.给出个人的PSP表格。
| PSP2.1 | 个人开发流程 | 预估耗费时间(分钟) | 实际耗费时间(分钟) |
|---|---|---|---|
| Planning | 计划 | 5 | 3 |
| · Estimate | 明确需求和其他相关因素,估计每个阶段的时间成本 | 5 | 3 |
| Development | 开发 | 360 | 518 |
| · Analysis | 需求分析 (包括学习新技术) | 60 | 120 |
| · Design Spec | 生成设计文档 | 5 | 2 |
| · Design Review | 设计复审 | 4 | 2 |
| · Coding Standard | 代码规范 | 5 | 5 |
| · Design | 具体设计 | 10 | 20 |
| · Coding | 具体编码 | 120 | 180 |
| · Code Review | 代码复审 | 10 | 9 |
| · Test | 测试(自我测试,修改代码,提交修改) | 60 | 180 |
| Reporting | 报告 | 40 | 65 |
| · | 测试报告 | 30 | 60 |
| · | 计算工作量 | 5 | 2 |
| · | 并提出过程改进计划 | 3 | 3 |
3.解题思路描述。即刚开始拿到题目后,如何思考,如何找资料的过程。
刚开始会先思考已经拿到了所有的字符该如何做下一个动作,空格和回车需要每次记录,还需要一个记录英文长度是否超过4,不超过的不算单词,然后清空前面储存的数组,这是一个大体,然后后面再根据需求添加各自要求,添加完开始测试发现自己很多地方没有设计又修改代码完善代码,所以导致中间的关键代码很冗长很乱,刚开始写的时候就遇到要从文件读取就开始各种百度,什么如何读取文件,如何在命令行里调用java程序,如何遍历map的所有键值,如何让map里面根据key排序,根据values排序
边学边写
4.设计实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?单元测试是怎么设计的?
-
计算模块接口的设计与实现过程。 设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?说明你的算法的关键(不必列出源代码),以及独到之处。(8')
-
我分成了五个类,还有一个main类,总共六个,分别是:
-
character :统计文本里的空格数量,回车数,水平制表符数
-
comper :有两种比较的接口,一种是用map中的key比较,一种是用map的values比较,重写的方法
-
main :主要是调用其它类的方法来实现这整个单词程序各部分的功能
-
open :执行读取文件的指令
-
word :以字节方式得到文件的内容,用for循环来进行单词的判断,用map来储存,最后用迭代器输出结果
-
Wordsimple :得到字节的内容,用for循环来进行单词的判断,用num储存单词数最后输出单词数
-
Word类中需要对单词进行排序所以会调用到comper类的比较器
-
Main类首先调用了open类先把文件里的数据用流的方式写入byte[]数组里,再一个一个遍历打印出,再调用character类输出空格数回车数等,再调用了wordsimple类统计出单词数,然后再调用了word类打印出单词出现次数为前十。
- 最关键的应该是word类,因为主要的代码都在这个函数里,中间我用了很多if else语句分支很多,光看代码我都容易看混,需要画一个流程图来让读这段代码的人更容易理解
- 每个类我都写了一个单元测试,不是写不同的文件来让每种类覆盖的多,而是在测试里修改测试的内容,测出的结果再认证我觉得这个认证我有点认识不多,导致很单一为了用这个方法会搞得很麻烦,还需要学习
5.代码说明。展示出项目关键代码,并解释思路与注释说明。
for(int x=0;x<=i;x++) { //遍历byte数组
if(data[x]>=65&&data[x]<=90) { //如果为大写改为小写
data[x]=(byte) (data[x]+32);
rold[flag]=data[x]; //是字母计入rold数组
flag++; //统计单词长度
}
else if(data[x]>=97&&data[x]<=122) {//是小写字母计入数组
rold[flag]=data[x];
flag++; //放入数组单词长度加一
}
else if(data[x]==32||data[x]==10||data[x]==13||data[x]==0||data[x]==9){//如是空格回车TAB分隔符一类的进入判断
if(flag>3) { //字母数长度超过3可以算作一个单词
String str = new String(rold).trim(); //使rold数组转为string并取掉多余的空格
Iterator<Entry<String, Integer>> it = map.entrySet().iterator();//用迭代器遍历判断是否有相同的单词已经存入
if(it.hasNext()) {
while(it.hasNext()) {
Entry<String, Integer> entry = it.next();
if(entry.getKey().equals(str)) {//如有相同的单词,value+1
map.put(str, entry.getValue()+1);
flag=0; //单词长度清空
rold = new byte[20]; //数组清空
rf=1; //记录是否放入了map
break;
}
}
if(rf!=1) { //循环完了,没放入需要放入
map.put(str, 1);
flag=0;
rold = new byte[20];
}
rf=0; //置0再次使用
}
else { //如果map里没值直接put
map.put(str, 1);
flag=0;
rold = new byte[20];
}
}
else { //如果不满足4个字母数,清空
flag=0;
rold = new byte[20];
}
}
else if(data[x]>=48&&data[x]<=57) { //如碰到特殊字符判断下一个字符是不是空并且字母数超过3个可以计入单词
if(data[x]!=32&&flag>3) {
rold[flag]=data[x];
flag++;
}
else { //如是空格或者不到4个字母清空
flag=0;
rold = new byte[20];
while(data[x+1]!=32) { //以特殊字符和数字开头的都不算单词
x++;
if(x==i)
break;
}
}
}
} //遍历完之后最后一个单词可能大于3个字母数需要计入数组运行如上
if(flag>3) {
String str = new String(rold).trim();
Iterator<Entry<String, Integer>> it = map.entrySet().iterator();
if(it.hasNext()) {
while(it.hasNext()) {
Entry<String, Integer> entry = it.next();
if(entry.getKey().equals(str)) {
map.put(str, entry.getValue()+1);
flag=0;
rold = new byte[20];
break;
}
else {
map.put(str, 1);
flag=0;
rold = new byte[20];
break;
}
}
}
else {
map.put(str, 1);
flag=0;
rold = new byte[20];
}
}
6.结合在构建之法中学习到的相关内容与个人项目的实践经历,撰写解决项目的心路历程与收获。
其实第一次开始学测试学效能,大家都是边学边做自然效率就低,我觉得应该把这些内容分开,我个人代码其实写的蛮久的因为有一些要求需要一个一个百度出教程然后学习之后再添加进自己的代码里,有时候为了赶工会粗略的套用,从而达不到学习的目的,我现在只是知道可以这样用,但其实内部为什么这么写我还是不知道,我只知道这一块是网上说可以用来写入文件我就直接套用,我甚至只能记住一个大概的模糊的样子,你要我再写一边我根本也写不出来。
7.计算模块接口部分的性能改进。 记录在改进计算模块性能上所花费的时间,描述你改进的思路。(3')
我最开始是把所有程序都写在了一个java文件里,然后一个个拆分,就发现有点麻烦,主要是以前写代码没有这个习惯就喜欢往一个文件里疯狂写,全集合在一起,但其实如果文件大了自己会开始乱,然后我分成了五个类,还有一个main类,总共六个,character ,comper ,main ,open ,word ,Wordsimple 。每个类里基本只有一个方法,这个的意思好像是想让我写在一个类里,然后调用不同的方法,但是那样的话那个代码不是很长么,全部代码都在那个class里,不如分开为五个类的好呀。
8.计算模块部分单元测试展示。 展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路。并将单元测试得到的测试覆盖率截图,发表在博客中。(4')
public class characterTest {
@Before
public void setUp() throws Exception {
}
@Test
public void testCharacter() {
String str = "Hello201621123036 hello
";
byte[] data = str.getBytes();
character c=new character(data,26);
assertEquals(2,c.kong);
assertEquals(1,c.t);
assertEquals(1,c.n);
}
}
这个测试最开始是调用character用data[]数组,然后测试c的数据是否相等
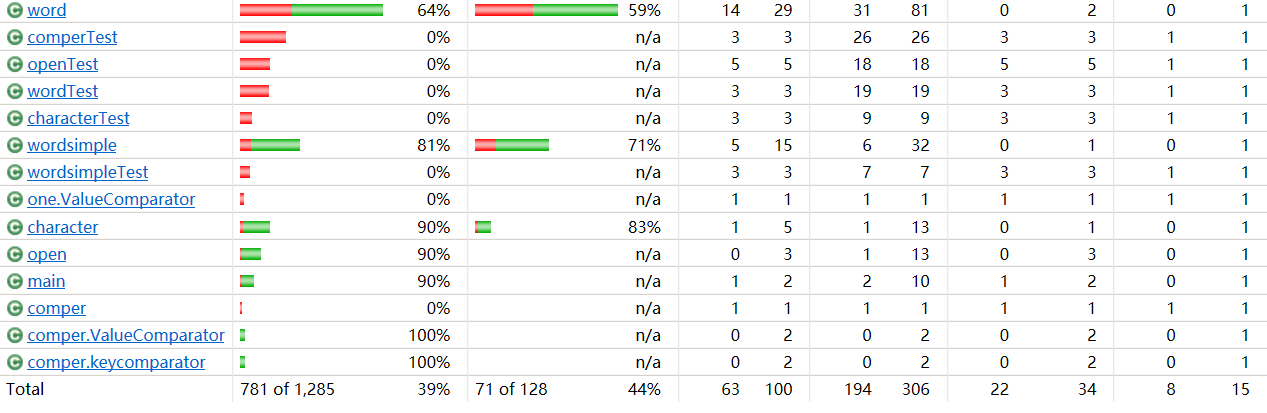
9.计算模块部分异常处理说明。 在博客中详细介绍每种异常的设计目标。每种异常都要选择一个单元测试样例发布在博客中,并指明错误对应的场景。(3')
测试:
public class openTest {
@Before
public void setUp() throws Exception {
}
@Test
public void testOpen() {
open f=new open();
String[] str= {"test.txt"};
byte[] data=f.open(str);
String s = new String(data).trim();
assertEquals("java201621123036 sdsd",s);
}
@Test
public void testOpen1() {
open f=new open();
String[] str= {"app.txt"};
byte[] data=f.open(str);
String s = new String(data).trim();
}
@Test
public void testGeti() {
open f=new open();
String[] str= {"test.txt"};
byte[] data=f.open(str);
assertEquals(22,f.geti());
}
}
读取文件:
public class open {
int i;
public byte[] open(String[] args){
//声明流对象
FileInputStream fis = null;
byte[] data = new byte[2048]; //数据存储的数组
try{
//创建流对象
fis = new FileInputStream("D:/"+args[0]);
//读取数据,并将读取到的数据存储到数组中
i = fis.read(data);
//解析数据
String s = new String(data,0,i);
//输出字符串
System.out.println(s.toLowerCase());
}catch(Exception e){
//e.printStackTrace();
System.out.println("系统找不到指定的文件。");
}finally{
try{
//关闭流,释放资源
fis.close();
}catch(Exception e){}
}
return data;
}
public int geti() {
return i;
}
}
10.效能测试
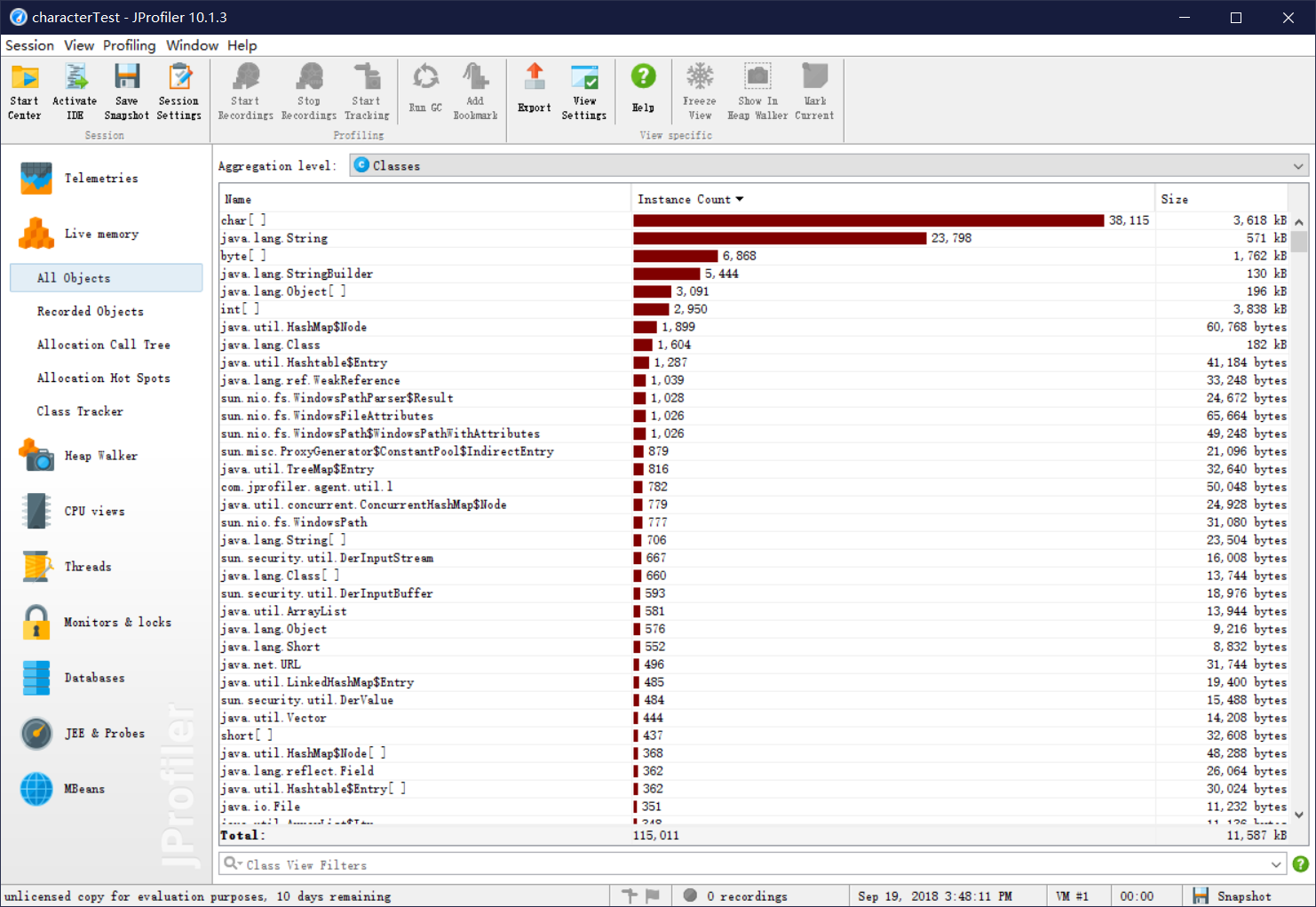
还不是很看得懂哪里占用资源,也点不开