引言 - 问题的构建
C大部分读取文件的时候采用fgetc, 最近在使用过程中发现性能不是很理想.都懂得fgetc每次只能读取一个字符, IO操作太频繁.
所以性能低. 本文希望通过标准库函数fread 函数构建读取缓冲区来优化这个瓶颈.
在正式开始实验总结之前, 传一个VS C/C++ 开发的技巧给大家, 天外飞仙~ .
M$忽略C++太久了,对于C直接放弃, 在其Visual Studio IDE中. 但是吧在Window 还是它的IDE写C 系列语言最爽.
现在很流行一个低端套路是, Window VS 开发, Linux上部署. 而我们的问题就是关于这个, 这种不同平台的开发和部署,
存在一个坑就是编码问题. 而这里就是希望完美的解决这个编码问题.
解决基准是选用UTF-8 带签名的编码, VS , GCC都能编译通过. 那就一言不合上图了, 首先定位VC模板文件
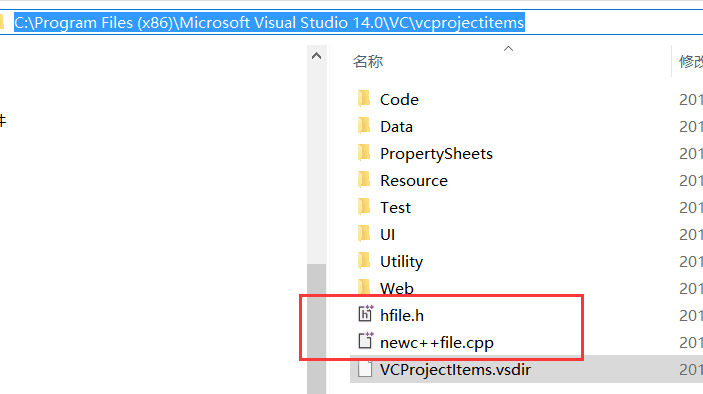
将上面模板文件备份一份, 复制一份, 用VS打开复制的那份
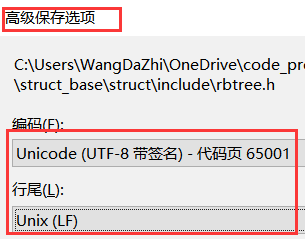
高级选项另存为上面编码格式. 最终保存替换原先的模板文件. 从此以后, 编码问题 perfect! 继续扯一点, 随着写代码时间增长, VS的依赖已经不重要的.
可惜喜欢打游戏, 还是被window 游戏机绑定了. 真的是离开I可以, 请付出代价~ /(ㄒoㄒ)/~~
前言 - 实验验证
这里验证的是fgetc 和 fread读取性能的对比. 在说之前, 先介绍个测试宏
// 简单的time帮助宏 #ifndef TIME_PRINT #define _STR_TIME_PRINT "The current code block running time:%lf seconds " #define TIME_PRINT(code) do { clock_t __st, __et; __st = clock(); code __et = clock(); printf(_STR_TIME_PRINT, (0.0 + __et - __st) / CLOCKS_PER_SEC); } while(0) #endif // !TIME_PRINT
非常还用, 将代码块插入到 code中, 就可以使用了. 那继续了, 第一个测试的主体内容是, 实验一 fread对比fgetc
#include <stdio.h> #include <time.h> #include <stdlib.h> #define _STR_DATA "data.txt" #define _INT_DATA (1024*1024*32) // 测试 fgetc 性能 void test_fgetc(void); // 测试 fread 性能 void test_fread(void); // // 测试C大文件处理方式 // int main(int argc, char * argv[]) { // 先构建测试环境 FILE * txt = fopen(_STR_DATA, "r"); if (NULL == txt) { txt = fopen(_STR_DATA, "w"); if (NULL == txt) { fprintf(stderr, "main fopen w " _STR_DATA " error! "); exit(EXIT_FAILURE); } // 开始写入数据 for (int i = 0; i < _INT_DATA; ++i) fprintf(txt, "%d", i); } fclose(txt); // 开始测试数据, 分批测试 TIME_PRINT({ test_fgetc(); }); TIME_PRINT({ test_fread(); }); return 0; }
其中两个测试函数如下.
// // 测试 fgetc 性能 // void test_fgetc(void) { FILE * txt = fopen(_STR_DATA, "r"); if (NULL == txt) { fprintf(stderr, "test_fgetc fopen w " _STR_DATA " error! "); return; } size_t cnt = 0; int c; while ((c = fgetc(txt)) != EOF) ++cnt; fclose(txt); printf("test_fgetc cnt = %d ", cnt); } // // 测试 fread 性能 // void test_fread(void) { FILE * txt = fopen(_STR_DATA, "r"); if (NULL == txt) { fprintf(stderr, "test_fread fopen w " _STR_DATA " error! "); return; } size_t cnt = 0; char buf[BUFSIZ]; for (;;) { int rn = fread(buf, sizeof(char), BUFSIZ, txt); // 存在信号中断情况, 不考虑 cnt += rn; if (rn < BUFSIZ) break; } fclose(txt); printf("test_fread cnt = %d ", cnt); }
测试主要思路是.
a. 构建差不多是200-300Mb的数据文件
b. 通过fgetc 完毕, 输出时间
c. 通过fread 完毕, 输出时间
测试结果如下
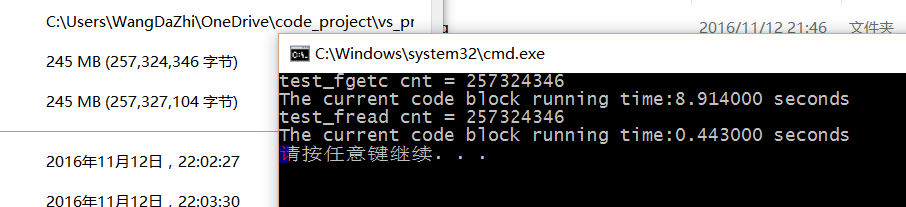
我们发现, fread构建缓冲区有质的飞跃.
附录测试完整内容 file_test.c


#include <stdio.h> #include <time.h> #include <stdlib.h> #define _STR_DATA "data.txt" #define _INT_DATA (1024*1024*32) // 简单的time帮助宏 #ifndef TIME_PRINT #define _STR_TIME_PRINT "The current code block running time:%lf seconds " #define TIME_PRINT(code) do { clock_t __st, __et; __st = clock(); code __et = clock(); printf(_STR_TIME_PRINT, (0.0 + __et - __st) / CLOCKS_PER_SEC); } while(0) #endif // !TIME_PRINT // 测试 fgetc 性能 void test_fgetc(void); // 测试 fread 性能 void test_fread(void); // // 测试C大文件处理方式 // int main(int argc, char * argv[]) { // 先构建测试环境 FILE * txt = fopen(_STR_DATA, "r"); if (NULL == txt) { txt = fopen(_STR_DATA, "w"); if (NULL == txt) { fprintf(stderr, "main fopen w " _STR_DATA " error! "); exit(EXIT_FAILURE); } // 开始写入数据 for (int i = 0; i < _INT_DATA; ++i) fprintf(txt, "%d", i); } fclose(txt); // 开始测试数据, 分批测试 TIME_PRINT({ test_fgetc(); }); TIME_PRINT({ test_fread(); }); return 0; } // // 测试 fgetc 性能 // void test_fgetc(void) { FILE * txt = fopen(_STR_DATA, "r"); if (NULL == txt) { fprintf(stderr, "test_fgetc fopen w " _STR_DATA " error! "); return; } size_t cnt = 0; int c; while ((c = fgetc(txt)) != EOF) ++cnt; fclose(txt); printf("test_fgetc cnt = %d ", cnt); } // // 测试 fread 性能 // void test_fread(void) { FILE * txt = fopen(_STR_DATA, "r"); if (NULL == txt) { fprintf(stderr, "test_fread fopen w " _STR_DATA " error! "); return; } size_t cnt = 0; char buf[BUFSIZ]; for (;;) { int rn = fread(buf, sizeof(char), BUFSIZ, txt); // 存在信号中断情况, 不考虑 cnt += rn; if (rn < BUFSIZ) break; } fclose(txt); printf("test_fread cnt = %d ", cnt); }
实验二 fread最优解
这里测试的主要思路是基于fread设置不同的缓冲区, 开始测试性能对比情况. 首先test_file_define.c
#include <stdio.h> #include <time.h> #include <stdlib.h> #define _STR_DATA "data.txt" #define _INT_DATA (1024*1024*128) #define _INT_SZS (64) #define _INT_SZE (4096) // 测试 fread 性能 void test_fread(int sz); // // 测试C大文件处理方式 // int main(int argc, char * argv[]) { // 先构建测试环境 FILE * txt = fopen(_STR_DATA, "r"); if (NULL == txt) { txt = fopen(_STR_DATA, "w"); if (NULL == txt) { fprintf(stderr, "main fopen w " _STR_DATA " error! "); exit(EXIT_FAILURE); } // 开始写入数据 for (int i = 0; i < _INT_DATA; ++i) fprintf(txt, "%d", i); } fclose(txt); // 开始测试数据, 分批测试 for (int sz = _INT_SZS; sz <= _INT_SZE; sz <<= 1) { clock_t st, et; st = clock(); test_fread(sz); et = clock(); printf("sz = %6d => time:%lf seconds ", sz, (0.0 + et - st) / CLOCKS_PER_SEC); } return 0; } // // 测试 fread 性能 // void test_fread(int sz) { FILE * txt = fopen(_STR_DATA, "r"); if (NULL == txt) { fprintf(stderr, "test_fread fopen w " _STR_DATA " error! "); return; } size_t cnt = 0; char buf[_INT_SZE]; for (;;) { int rn = fread(buf, sizeof(char), sz, txt); // 存在信号中断情况, 不考虑 cnt += rn; if (rn < sz) break; } fclose(txt); printf("test_fread cnt = %d ", cnt); }
最终测试结果如下

直接说我得到的结论是
1). fread读取的时候, buf 和 文件大小, 机器等共同影响了最优解
2). 在设置缓冲大小为BUFSIZ左右, 性能都是可以接受的.
通过上面两个实验, 最终得到的一个结论. 处理大文件IO读取时候, 设计缓冲区可以采用下面套路将会获得更好的性能.
char buf[BUFSIZ]; size_t rn; do { rn = fread(buf, sizeof(char), BUFSIZ, txt); if (rn < 0) { // 初始失败的情况 .... } // 处理合法情况 .... } while(rn == BUFSIZ);
正文 - 构建一个成果
到这里, 通过上面结论, 开始构建一个成果, 例如读取全部文件内容. 当然限定文件大小在100mb以内吧, 太大需要采用分量读取算法了.
会使用到的辅助操作宏
// // 控制台输出完整的消息提示信息, 其中fmt必须是 "" 包裹的字符串 // CERR -> 简单的消息打印 // CERR_EXIT -> 输出错误信息, 并推出当前进程 // CERR_IF -> if语句检查, 如果符合标准错误直接退出 // #ifndef _H_CERR #define _H_CERR #define CERR(fmt, ...) fprintf(stderr, "[%s:%s:%d][errno %d:%s]" fmt " ", __FILE__, __func__, __LINE__, errno, strerror(errno), ##__VA_ARGS__) #define CERR_EXIT(fmt,...) CERR(fmt, ##__VA_ARGS__), exit(EXIT_FAILURE) #define CERR_IF(code) if((code) < 0) CERR_EXIT(#code) #endif
首先声明读取文件的接口部分.
#ifndef _STRUCT_TSTR #define _STRUCT_TSTR struct tstr { char * str; // 字符串实际保存的内容 size_t len; // 当前字符串长度 size_t cap; // 字符池大小 }; // 定义的字符串类型 typedef struct tstr * tstr_t; #endif // !_STRUCT_TSTR // // 简单的文件读取类,会读取完毕这个文件内容返回,失败返回NULL. // path : 文件路径 // return : 创建好的字符串内容, 返回NULL表示读取失败 // extern tstr_t tstr_freadend(const char * path);
这么设计方面, 后续操作, 读取内容长度, 继续添加内容方便些. 详细的实现如下
// // 简单的文件读取类,会读取完毕这个文件内容返回,失败返回NULL. // path : 文件路径 // return : 创建好的字符串内容, 返回NULL表示读取失败 // tstr_t tstr_freadend(const char * path) { tstr_t tstr; char buf[BUFSIZ]; size_t rn; char * ctmp; FILE * txt = fopen(path, "r"); if (NULL == txt) { CERR("tstr_freadend fopen r %s is error!", path); return NULL; } // 分配内存 tstr = malloc(sizeof(struct tstr)); if (NULL == tstr) { fclose(txt); CERR("tstr_freadend malloc is error! path = %s.", path); return NULL; } tstr->len = 0; tstr->cap = _INT_TSTRING; tstr->str = NULL; // 读取文件内容 do { rn = fread(buf, sizeof(char), BUFSIZ, txt); if (rn < 0) { CERR("tstr_freadend fread is error! path = %s. rn = %d.", path, rn); fclose(txt); free(tstr->str); free(tstr); return NULL; } // 构建数据 if (tstr->cap < tstr->len + rn) { do tstr->cap <<= 1; while (tstr->cap < tstr->len + rn); ctmp = realloc(tstr->str, tstr->cap); if (NULL == ctmp) { CERR("tstr_freadend realloc is error! path = %s!", path); fclose(txt); free(tstr->str); free(tstr); return NULL; } tstr->str = ctmp; } // 开始拷贝数据 memcpy(tstr->str + tstr->len, buf, rn); tstr->len += rn; } while (rn == BUFSIZ); fclose(txt); // 继续构建数据, 最后一行补充一个� if (tstr->cap < tstr->len + 1) { do tstr->cap <<= 1; while (tstr->cap < tstr->len + 1); ctmp = realloc(tstr->str, tstr->cap); if (NULL == ctmp) { CERR("tstr_freadend realloc is end error! path = %s!", path); free(tstr->str); free(tstr); return NULL; } } tstr->str[tstr->len] = '�'; tstr->len += 1; return tstr; }
最终测试文件 file_test_build.c
#include <stdio.h> #include <errno.h> #include <stdlib.h> #include <assert.h> #include <stdint.h> #include <stddef.h> #include <string.h> #ifndef _STRUCT_TSTR #define _STRUCT_TSTR struct tstr { char * str; // 字符串实际保存的内容 size_t len; // 当前字符串长度 size_t cap; // 字符池大小 }; // 定义的字符串类型 typedef struct tstr * tstr_t; #endif // !_STRUCT_TSTR // // 控制台输出完整的消息提示信息, 其中fmt必须是 "" 包裹的字符串 // CERR -> 简单的消息打印 // CERR_EXIT -> 输出错误信息, 并推出当前进程 // CERR_IF -> if语句检查, 如果符合标准错误直接退出 // #ifndef _H_CERR #define _H_CERR #define CERR(fmt, ...) fprintf(stderr, "[%s:%s:%d][errno %d:%s]" fmt " ", __FILE__, __func__, __LINE__, errno, strerror(errno), ##__VA_ARGS__) #define CERR_EXIT(fmt,...) CERR(fmt, ##__VA_ARGS__), exit(EXIT_FAILURE) #define CERR_IF(code) if((code) < 0) CERR_EXIT(#code) #endif // // 简单的文件读取类,会读取完毕这个文件内容返回,失败返回NULL. // path : 文件路径 // return : 创建好的字符串内容, 返回NULL表示读取失败 // extern tstr_t tstr_freadend(const char * path); // // 测试文件读取, 推荐都是50mb以下文件好处理一点 // int main(int argc, char * argv[]) { const char * path = "顾城 - 没有名字的诗歌.txt"; tstr_t str = tstr_freadend(path); if (NULL == str) CERR_EXIT("日狗吗? 这都读不出来`!"); // 这里打出数据 printf("当前总字符数:%d, 当前容量:%d. ", str->len, str->cap); puts(str->str); free(str->str); free(str); return 0; } // 文本字符串创建的初始化大小 #define _INT_TSTRING (32) // // 简单的文件读取类,会读取完毕这个文件内容返回,失败返回NULL. // path : 文件路径 // return : 创建好的字符串内容, 返回NULL表示读取失败 // tstr_t tstr_freadend(const char * path) { tstr_t tstr; char buf[BUFSIZ]; size_t rn; char * ctmp; FILE * txt = fopen(path, "r"); if (NULL == txt) { CERR("tstr_freadend fopen r %s is error!", path); return NULL; } // 分配内存 tstr = malloc(sizeof(struct tstr)); if (NULL == tstr) { fclose(txt); CERR("tstr_freadend malloc is error! path = %s.", path); return NULL; } tstr->len = 0; tstr->cap = _INT_TSTRING; tstr->str = NULL; // 读取文件内容 do { rn = fread(buf, sizeof(char), BUFSIZ, txt); if (rn < 0) { CERR("tstr_freadend fread is error! path = %s. rn = %d.", path, rn); fclose(txt); free(tstr->str); free(tstr); return NULL; } // 构建数据 if (tstr->cap < tstr->len + rn) { do tstr->cap <<= 1; while (tstr->cap < tstr->len + rn); ctmp = realloc(tstr->str, tstr->cap); if (NULL == ctmp) { CERR("tstr_freadend realloc is error! path = %s!", path); fclose(txt); free(tstr->str); free(tstr); return NULL; } tstr->str = ctmp; } // 开始拷贝数据 memcpy(tstr->str + tstr->len, buf, rn); tstr->len += rn; } while (rn == BUFSIZ); fclose(txt); // 继续构建数据, 最后一行补充一个� if (tstr->cap < tstr->len + 1) { do tstr->cap <<= 1; while (tstr->cap < tstr->len + 1); ctmp = realloc(tstr->str, tstr->cap); if (NULL == ctmp) { CERR("tstr_freadend realloc is end error! path = %s!", path); free(tstr->str); free(tstr); return NULL; } } tstr->str[tstr->len] = '�'; tstr->len += 1; return tstr; }
测试结果是通过的
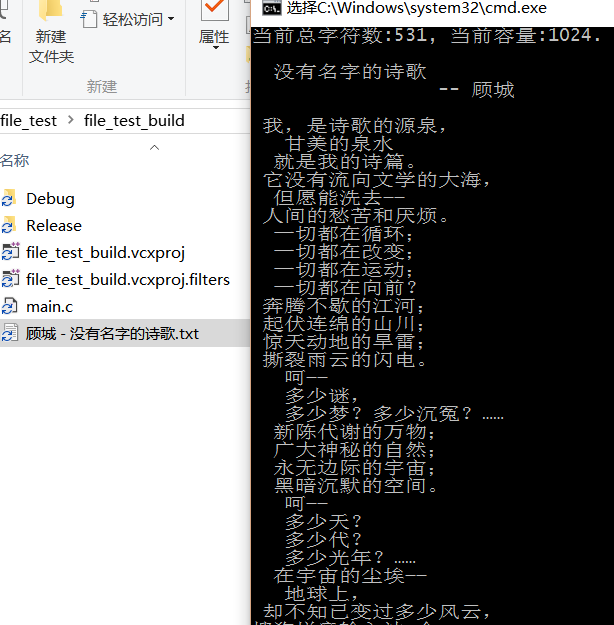
到这里基本上, 我们已经通过验证,构建了最终的操作代码, 欢迎尝试用于性能提升上.
后记 - 扯淡以后
错误是难免的, 欢迎指正, 交流提高. O(∩_∩)O哈哈~
笑傲江湖曲 http://music.163.com/#/song?id=30031035
