作业要求查看https://edu.cnblogs.com/campus/nenu/2020Fall/homework/11206
一.怎么开始?
语言选择:python 选择原因:Python的标准库种类繁多,可以帮助我们处理各种工作,不需要安装就可以直接使用。
编程前需要解决的问题:
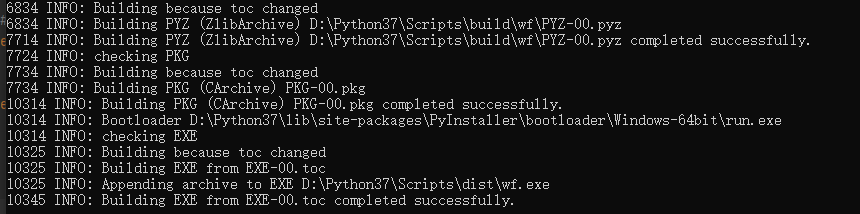
1.Python不像C语言或者C++之类的编译型语言编译后可生成.exe文件,Python是边解释边执行的,所以第一个工作就是把.py文件转换成.exe文件
做法参考博客 https://blog.csdn.net/tangdaxue43/article/details/84840643
2.如何获取命令行参数
下面一起来看个小demo
import sys print("参数个数",len(sys.argv)) print("参数",str(sys.argv)) print("第一个参数",sys.argv[0]) print("第2个参数",sys.argv[1])
与C语言类似,不过没有参数argc,可用len(argv)获取参数个数。参数的获取直接影响着程序接口的调用
二.具体功能实现
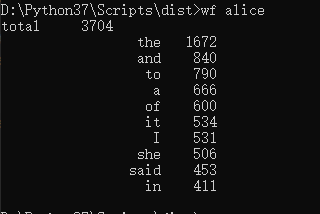
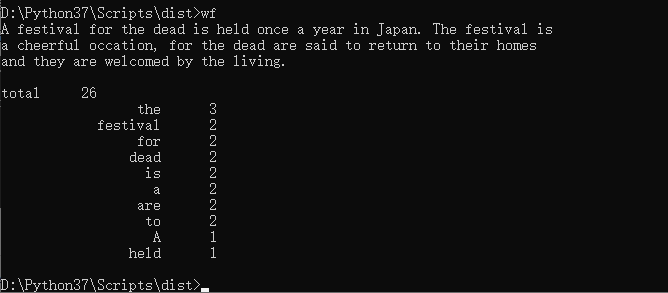
功能1 小文件输入。 为表明程序能跑,结果真实而不是迫害老五,请他亲自键
盘在控制台下输入命令。

def get_word_freq(str): words = get_file_content(str) word_list = Counter(words) # [('a', 5), ('b', 2), ('r', 2)] total = len(word_list) # 记录单词个数 print("total ", total) common_word_list = word_list.most_common(10) for common_word in common_word_list: print("%20s %5d" % (common_word[0], common_word[1])) #返回单词list def get_file_content(path_or_content_str): contents = '' if(os.path.isfile(path_or_content_str)): filename = path_or_content_str with open(filename, encoding='utf-8') as f_obj: contents = f_obj.read() # findall(p,txt) 在txt字符串总查找所有匹配的内容,如果找到,返回字符串列表,否则None else: contents = path_or_content_str words = re.findall(r'[w^-]+', contents) # ['My', 'English', 'is', 'very', 'very', 'pool'] return words
(1)这个功能来来回回改了好多次,第一次是自己写的函数,先用sorted对单词根据词频排序,最后输出数组前10项,结果运行大文件时力不从心,后面查找到了most_common..
也就是此题目的亮点,用法如下:
most_common([n])-
Return a list of the n most common elements and their counts from the most common to the least. If n is omitted or
None,most_common()returns all elements in the counter. Elements with equal counts are ordered in the order first encountered: -
Counter('abracadabra').most_common(3) [('a', 5), ('b', 2), ('r', 2)]
(2)正则表达式,print格式输出不熟悉也浪费了很多时间
(3)此程序的参数可以为表示文章内容的字符串,也可以是文件路径
功能2 支持命令行输入英文作品的文件名,请老五亲自录入。
elif len(sys.argv) == 2 and os.path.isfile(sys.argv[1] + '.txt'): # 功能2
filename = sys.argv[1] + '.txt'
get_word_freq(filename)
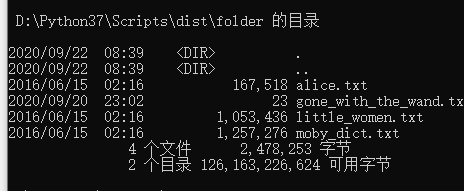
功能3 支持命令行输入存储有英文作品文件的目录名,批量统计。

# 是否为功能3接口 elif len(sys.argv) == 2 and os.path.isdir(sys.argv[1]): multiple_call_word_fre(sys.argv[1])
这里用到了os.path.isdir() 来判断第二个参数是否为文件夹
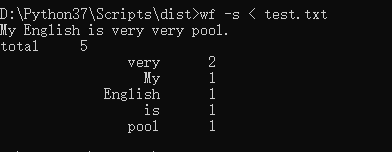
功能4 从控制台读入英文单篇作品,这不是为了打脸老五,而是为了向你女朋友炫酷,表明你能提供更适合嵌入脚本中的作品(或者如她所说,不过是更灵活的接口)。如果读不懂需求,请教师兄师姐,或者 bing: linux 重定向,尽管这个功能在windows下也有,搜索关键词中加入linux有利于迅速找到。
情况1:
elif len(sys.argv) == 2: # 功能4情况1 command < file 将输入重定向到 file。 file_str = input() print(file_str) get_word_freq(file_str)
难点在于理解重定向。还有个需要特别注意的地方 当命令行输入"wf -s < the_show_of_the_ring " ,此时len(argv)的值为2不是4!!!被这里坑死。
情况2:
elif len(sys.argv) == 1: #功能4情况2 data = "" for line in sys.stdin: if line != " ":#停止条件 data += line else: break get_word_freq(data)
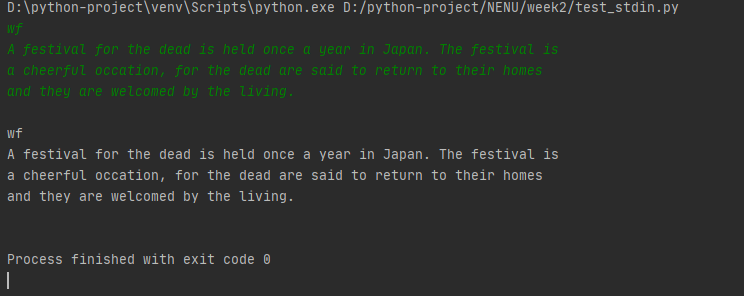
这里的难点在于如何从命令行获取多行输入。这里需要用到sys.stdin ,可以用下面的小demo理解:
import sys data = "" for line in sys.stdin: if line != " ":#停止条件 data += line else: break print(data)
此demo的输出结果如下:
PSP

代码及版本控制
github代码链接:https://github.com/lichao9417/SPEC