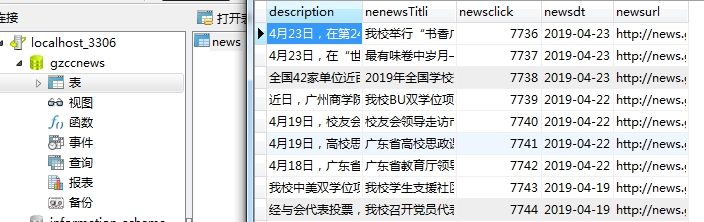
可以用pandas读出之前保存的数据:见上次博客爬取全部的校园新闻并保存csv
一.把爬取的内容保存到数据库sqlite3
import sqlite3
with sqlite3.connect('gzccnewsdb.sqlite') as db:
newsdf.to_sql('gzccnews',con = db)
with sqlite3.connect('gzccnewsdb.sqlite') as db:
df2 = pd.read_sql_query('SELECT * FROM gzccnews',con=db)
保存到MySQL数据库
- import pandas as pd
- import pymysql
- from sqlalchemy import create_engine
- conInfo = "mysql+pymysql://user:passwd@host:port/gzccnews?charset=utf8"
- engine = create_engine(conInfo,encoding='utf-8')
- df = pd.DataFrame(allnews)
- df.to_sql(name = ‘news', con = engine, if_exists = 'append', index = False)
 二.爬虫综合大作业
二.爬虫综合大作业- 选择一个热点或者你感兴趣的主题。
- 选择爬取的对象与范围。
- 了解爬取对象的限制与约束。
- 爬取相应内容。
- 做数据分析与文本分析。
- 形成一篇文章,有说明、技术要点、有数据、有数据分析图形化展示与说明、文本分析图形化展示与说明。
- 文章公开发布。
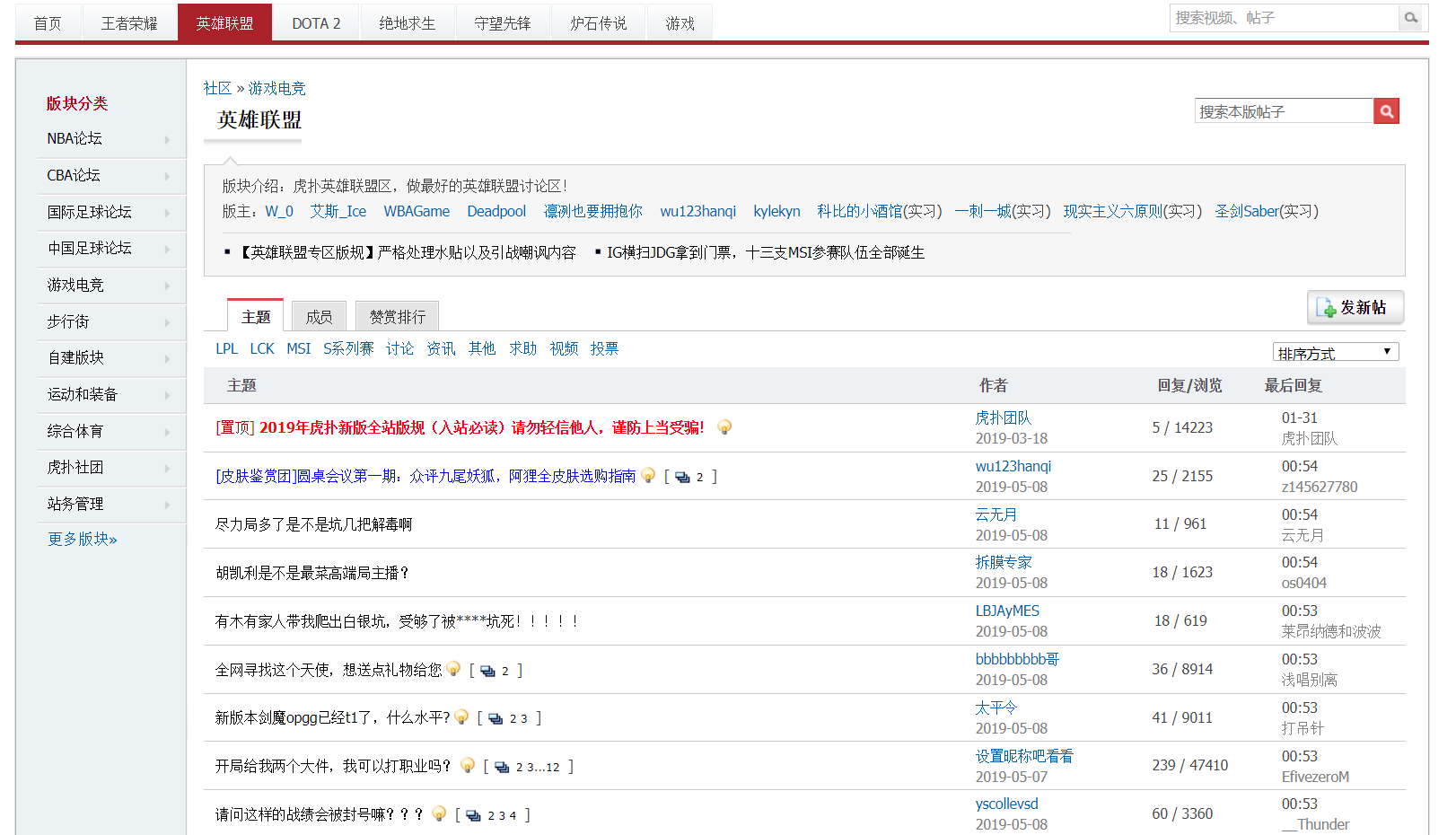
- 我爬取的主题是虎扑英雄联盟专区,作为一名jr,平时比较喜欢在虎扑这个软件。
主要代码:
-
生成爬虫的函数 def creat_bs(url): result = requests.get(url) e=chardet.detect(result.content)['encoding'] #set the code of request object to the webpage's code result.encoding=e c = result.content soup =BeautifulSoup(c,'lxml') return soup
接着构建所要获取网页的集合函数: def build_urls(prefix,suffix): urls=[] for item in suffix: url=prefix+item urls.append(url) return urls
爬取函数: def find_title_link(soup): titles=[] links=[] try: contanier=soup.find('div',{'class':'container_padd'}) ajaxtable=contanier.find('form',{'id':'ajaxtable'}) page_list=ajaxtable.find_all('li') for page in page_list: titlelink=page.find('a',{'class':'truetit'}) if titlelink.text==None: title=titlelink.find('b').text else: title=titlelink.text if np.random.uniform(0,1)>0.90: link=titlelink.get('href') titles.append(title) links.append(link) except: print('have no value') return titles,links
数据并保存: wordlist=str() for title in title_group: wordlist+=title for reply in reply_group: wordlist+=reply def savetxt(wordlist): f=open('wordlist.txt','wb') f.write(wordlist.encode('utf8')) f.close() savetxt(wordlist)
词云图的制作: import jieba jieba.load_userdict('user_dict.txt') wordlist_af_jieba=jieba.cut_for_search(wordlist) wl_space_split=' '.join(wordlist_af_jieba) from wordcloud import WordCloud,STOPWORDS import matplotlib.pyplot as plt stopwords=set(STOPWORDS) fstop=open('stopwords.txt','r') for eachWord in fstop: stopwords.add(eachWord.decode('utf-8')) wc=WordCloud(font_path=r'C:WindowsFontsSTHUPO.ttf', background_color='black',max_words=200,width=700,height=1000,stopwords=stopwords,max_font_size=100,random_state=30) wc.generate(wl_space_split) wc.to_file('hupu_pubg2.png') plt.imshow(wc,interpolation='bilinear') plt.axis('off')
爬取的帖子截图:
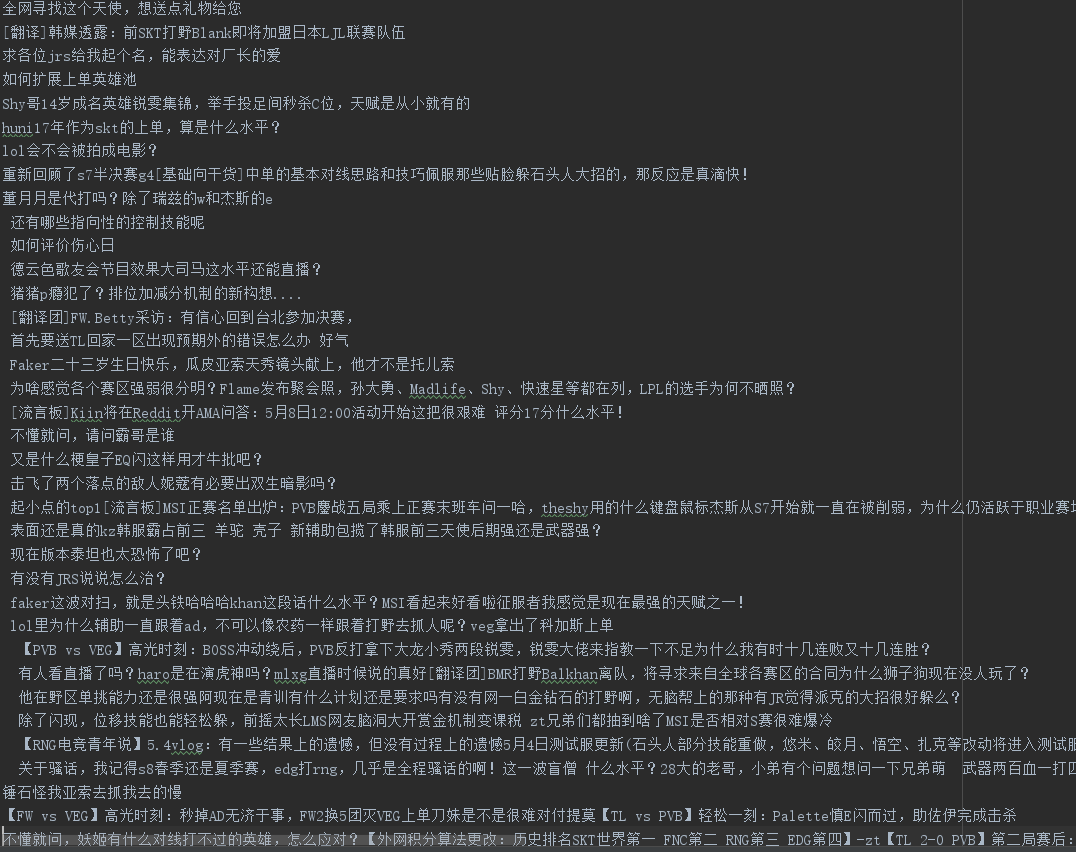

词云图:
