分页查询
--分页查询 ROWNUM SELECT ROWNUM,ENAME,SAL,DEPTNO FROM EMP WHERE ROWNUM BETWEEN 6 AND 10;
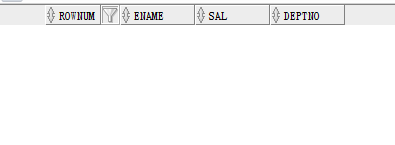
上面的分页查询 已经查询了数据但是为什么查询不出数据?
答:--这个是查询不出任何数据的.因为rownum>1 后 rownum从1开始 但是他的值一直大于一
--rownum不可以自增1 所以导致数据不能向下走 数据不可以被查出来。
上面昨日遗留问题
分页查询案例
--把rownum 加进去的当做一张表查询 查询6-10 之间的值 SELECT * FROM (SELECT ROWNUM AS IDD ,ENAME,SAL,DEPTNO FROM EMP ) WHERE IDD BETWEEN 6 AND 10;
--注意这里一定要给别名 否则数据库不认为 是要查询该表里面字段
--题目:查找公司工资排名的6-10名 SELECT *FROM (SELECT ROWNUM AS ISS ,ENAME,SAL FROM (SELECT ENAME,SAL FROM EMP ORDER BY SAL DESC) ) WHERE ISS BETWEEN 6 AND 10;
--最里面的一层查询 是排序 外面的一层是 加rownum 只要排序就需要两层查询
--题目:查找公司工资排名的6-10名 SELECT *FROM (SELECT ROWNUM AS ISS ,ENAME,SAL FROM (SELECT ENAME,SAL FROM EMP ORDER BY SAL DESC) WHERE ROWNUM <=10) WHERE ISS >=6;
DECODE函数(参数,参数,参数...)
可以实现分支结构
--DECODE函数 可以实现分支结构 SELECT ENAME,JOB,SAL,DECODE( JOB, 'MANAGER',SAL*10, 'ANALYST',SAL*5, 'CLERK',sal*2, sal ) 工资 FROM EMP;
--DECODE函数 可以实现分支结构 SELECT ENAME,JOB,SAL,DECODE( JOB, 'MANAGER',SAL*10, 'ANALYST',SAL*5, 'CLERK',sal*2 ) 工资 FROM EMP; --如果没有default条件 不满足条件的填null
--利用decode函数将MANAGER,ANALYST划分为一组 SELECT COUNT(*),DECODE( JOB, 'MANAGER','VIP', 'ANALYST','VIP', 'OTHER' ) FROM EMP GROUP BY DECODE( JOB, 'MANAGER','VIP', 'ANALYST','VIP', 'OTHER' )
--利用decode函数将想要按自己的排序进去操作 SELECT DISTINCT DEPTNO,DNAME FROM DEPT ORDER BY DECODE( DNAME, 'ACCOUNTING',1, 'OPERATIONS',2, 'RESEARCE',3, 4 );
CASE语句
与DECODE函数用法相似
--case语句 SELECT ENAME,JOB,SAL,CASE JOB WHEN 'MANAGER' THEN SAL*10 WHEN 'ANALYST'THEN SAL*5 WHEN 'CLERK' THEN sal*2 ELSE SAL END 工资 from EMP;
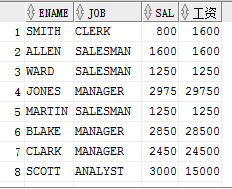
排序函数
排序函数允许对结果集按照指定的字段分组在组内要按照指定的字段排序,最终生成组内编号
1.ROW_NUMBER() OVER(
PARTITON BY 字段名
)
--利用排序函数ROW_NUMBER()函数 查看每个部门的工资排名 SELECT DEPTNO,ENAME,SAL,ROW_NUMBER() OVER( PARTITION BY DEPTNO ORDER BY SAL DESC ) SORTT FROM EMP
2.RANK函数
生成组内个连续也不唯一的数字,同组内排序字段值一样的记录,生成的数字也一样
--RANK函数 生成组内不连续也不唯一的数字,同组内排序字段一样的记录,生成的数字也一样 SELECT DEPTNO,ENAME,RANK() OVER( PARTITION BY DEPTNO ORDER BY SAL DESC ) SORTT FROM EMP
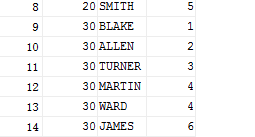
注意 这里重复了4 没有按照顺序出现5.
集合操作
并集、交集、差集
1.并集(两个条件都要兼顾 只要有一个 结果就会显示)
UNION
SELECT ENAME,JOB,SAL FROM EMP WHERE JOB='MANAGER' UNION SELECT ENAME,JOB,SAL FROM EMP WHERE SAL>2500;
UNION ALL
SELECT ENAME,JOB,SAL FROM EMP WHERE JOB='MANAGER' UNION ALL SELECT ENAME,JOB,SAL FROM EMP WHERE SAL>2500;
UNION和UNION ALL 最大的区别:第一个 不会将重复的显示出来,第二个会将重复的显示出来
2.交集(显示两者都满足的条件的数据)
关键字:
INTERSECT
--交集(取结果集内共有的记录) SELECT ENAME,JOB,SAL FROM EMP WHERE JOB='MANAGER' INTERSECT SELECT ENAME,JOB,SAL FROM EMP WHERE SAL>2500;
3.差集(满足上边但不满足下边)
关键字:
MINUS
--差集 满足上边条件但是不满足下边 SELECT ENAME,JOB,SAL FROM EMP WHERE JOB='MANAGER' MINUS SELECT ENAME,JOB,SAL FROM EMP WHERE SAL>=2500;
高级分组函数
主要用于GROUP up中
1.ROLLUP()
分组原则,参数逐渐递减,一直到所有参数都没有,每一种分组统计一次结果,并在一个结果集内显示。
--查看每天每月每年 以及总共的营业额 SELECT year_id,month_id,day_id,sum(sales_value) FROM sales_tab GROUP BY ROLLUP(year_id,month_id,day_id)
结果:最后参数再逐渐递减直到没有

2.CUBE()
每种组合分一次组,分组的次数是2的参数个数次方
SELECT year_id,month_id,day_id,sum(sales_value) FROM sales_tab GROUP BY CUBE(year_id,month_id,day_id)
这个函数不过是把参数组合的所有情况都显示出来。
3.GROUPING SETS ()
每个参数是一种分组方式,然后将这些分组统计后并在一个结果集内显示
--GROUPING SETS 只看 相同日相同月的(自己可定义) 可以满足 SELECT year_id,month_id,day_id,sum(sales_value) FROM sales_tab GROUP BY GROUPING SETS((year_id,month_id,day_id), (year_id,month_id))
参数自己可以定义自己想看的结果。