Visoin MLP之CycleMLP A MLP-like Architecture for Dense Prediction

从摘要读文章
This paper presents a simple MLP-like architecture, CycleMLP, which is a versatile backbone for visual recognition and dense predictions, unlike modern MLP architectures, e.g., MLP-Mixer, ResMLP, and gMLP, whose architectures are correlated to image size and thus are infeasible in object detection and segmentation.
看来又是一个金字塔形状的 MLP 架构,并且可以看到主要的工作必定又是围绕空间 MLP 而展开的。因为这里解除了架构对于输入尺寸的依赖。
实际上在MLP-Mixer 原论文中,作者们其实也尝试了金字塔结构,相较与固定分辨率的形式,确实收敛更快。We tried using the token-mixing MLP to reduce the number of tokens by mapping from S input tokens to S'<S output tokens. While first experiments showed that on JFT-300M such models significantly reduced training time without losing much performance, we were unable to transfer these findings to ImageNet or ImageNet-21k.
CycleMLP has two advantages compared to modern approaches.
- (1) It can cope with various image sizes.
- (2) It achieves linear computational complexity to image size by using local windows.
这里使用局部窗口的操作实现了线性计算复杂度,这中固定局部窗口也使得可以处理不同大小的图像。
In contrast, previous MLPs have quadratic computations because of their fully spatial connections.
指出了改进空间 MLP 的必要性。其计算复杂度太高。
We build a family of models that surpass existing MLPs and achieve a comparable accuracy (83.2%) on ImageNet-1K classification compared to the state-of-the-art Transformer such as Swin Transformer (83.3%) but using fewer parameters and FLOPs.
可以看到,本文的方法的性能是非常高的。不知道除了结构之外,是否使用了其他的策略。
We expand the MLP-like models' applicability, making them a versatile backbone for dense prediction tasks. CycleMLP aims to provide a competitive baseline on object detection, instance segmentation, and semantic segmentation for MLP models. In particular, CycleMLP achieves 45.1 mIoU on ADE20K val, comparable to Swin (45.2 mIOU). Code is available at this https URL.
主要内容
整体结构
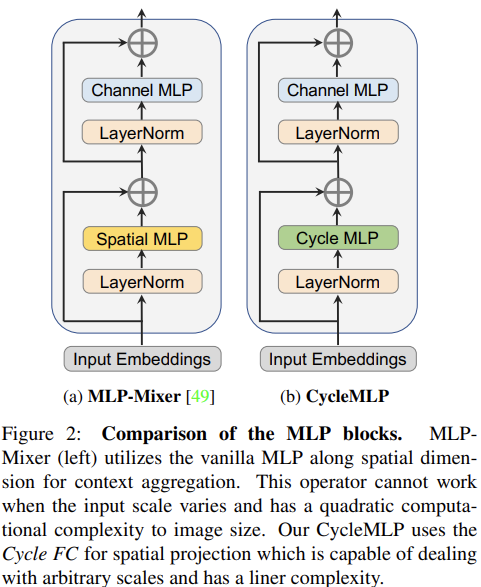
可以看到,核心是在改进空间 MLP。
现有 MLP 结构的三点不足:
- 大多属于单尺度结构,不便于迁移到其他的需要特征金字塔的任务上,例如检测、分割等。
- 空间 MLP 会连接输入特征空间上的所有点,这也限制了模型对于输入尺寸的依赖。不利于多尺度训练、多尺度测试、甚至训练和测试分辨率不一样的情况。
- 空间 MLP 具有二次方量级的计算复杂度,使其不便于处理高分辨率图像。
对此,作者们从两个方面进行应对:
- 针对问题 1,设计了层级结构来生成特征金字塔。
- 针对问题 2 和 3,实际上是针对空间 MLP 的问题,作者们设计了一种特殊的通道 MLP 来实现对于局部空间的处理。由于是针对局部空间的,所以说不再对于输入尺寸有过强的依赖。并且仍然是通道 MLP(空间上共享的点操作),所以计算复杂度降低到了线性。
与 S2-MLP 的不同
虽然都是使用通道 MLP 替换了空间 MLP,但是具体方式和模型整体形式有所不同:
- S2-MLP 对特征进行通道分组,不同组进行空间上不同方向的相对偏移。这在特征图上引入了额外的分组和偏移操作。而本文则是不需要改变特征,仅仅是调整了通道 MLP 的运算形式。具有更良好的通用性和可拔插性。
- S2-MLP 依然是单尺度结构,本文引入了金字塔结构来更好的适应检测分割等任务。
实际上,对于第 1 点,其实 S2-MLP 中给出了使用深度分离卷积实现的策略,即偏移可以通过特定形式的深度分离卷积核实现,对于输入数据的分组和偏移都是可以直接通过对卷积核的操作来实现的。这里的第 1 点并不成立。只能说,Cycle FC 的实现可能更加直接一些,不同于 S2-MLP 需要借助一些与计算无关的处理操作。
更进一步,从实现上来讲,Cycle FC 是否也是可以通过使用深度分离卷积实现便宜操作呢?回答是可以的,我会在后文的代码分析中提供一些简单的尝试。
模型细节
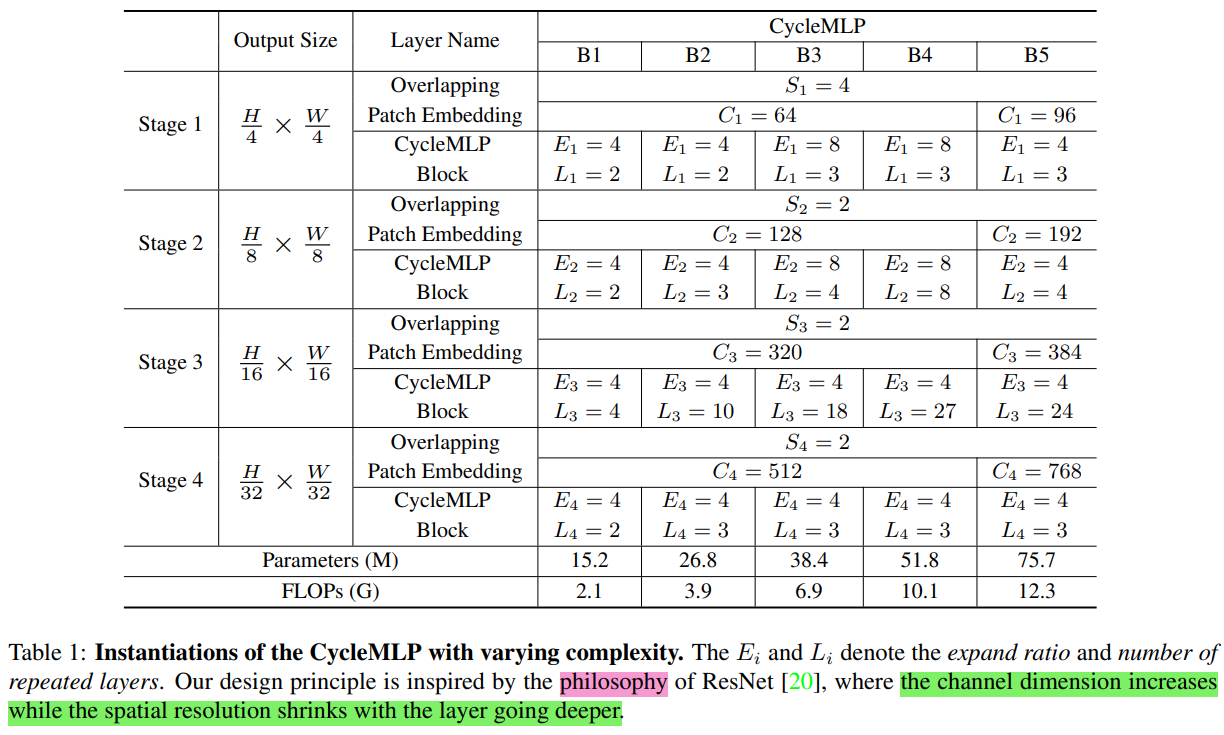
- patch embedding module: window size 7, stride 4,最终特征下采样四倍。
- 中间通过跨步卷积实现 2 倍下采样。
- 最终输出为下采样 32 倍的特征。
- 最终使用一个全连接层整合所有 token 的特征。
核心操作——Cycle FC
论文提出 Cycle FC 的核心想法在于利用通道 MLP 的与特征尺寸的无关性(减少了对输入形状的限制并且可以将计算复杂度降到线性),同时想办法增大其感受野来更好的集成上下文特征。
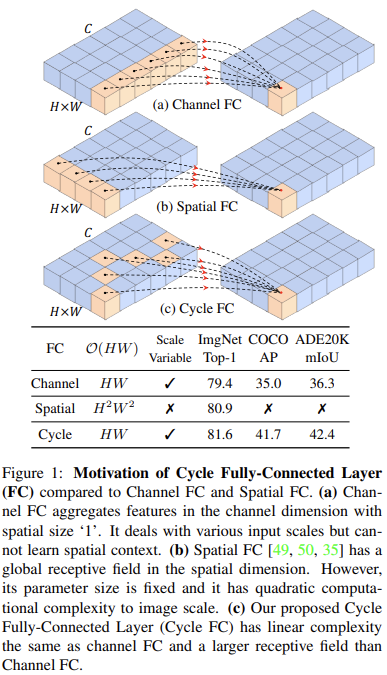
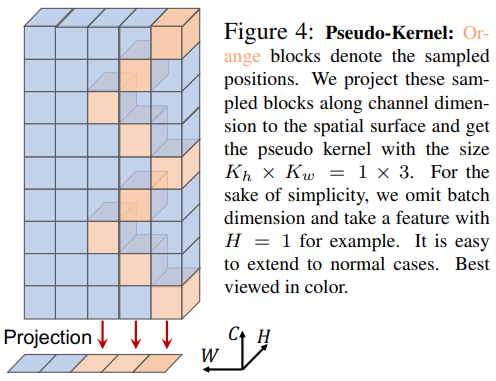
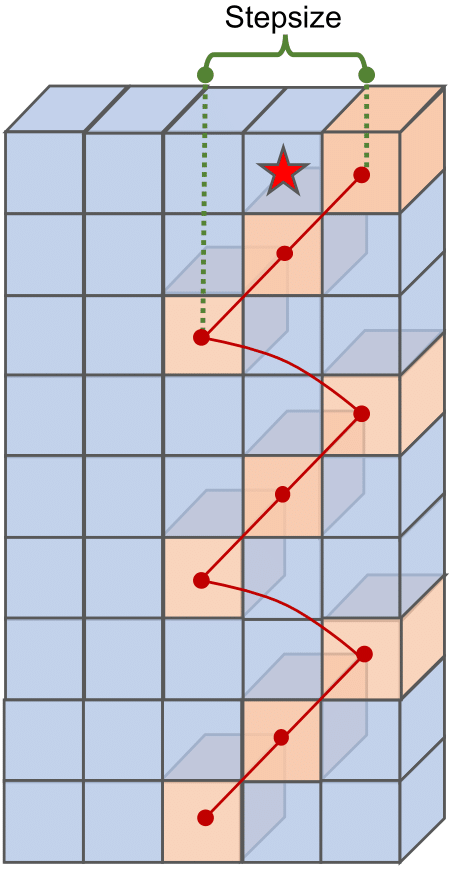
从图中给出的形式可以看到,Cycle FC 实际上是一种在通道上进行特定位置的偏移(阶梯状采样,stair-like style)的通道 MLP。所以对于输入的形状要求不会太严苛。当然,至少偏移位置不能超出 HW 上限定的核尺寸。
从代码中可以看到,这里是限定了一个范围,通过让通道索引对其取模从而实现限定范围内的循环偏移,这里的实现很有意思,用到了可变形卷积来对核参数应用偏移。
具体而言,原始的通道 MLP 的计算方式为:(Y_{i,j} = sum_{c=0}^{C_i - 1} mathcal{F}^{ op}_{j,c} cdot X_{i,c}),其中的 (mathcal{F} in mathbb{R}^{C_i imes C_o}) 表示通道 MLP 的可学习权重。其中的 (i&j) 分别表示空间和通道的索引。
而对于本文提出的 Cycle FC,计算方式扩展成为:(Y_{i, j} = sum_{c=0}^{C_i-1} mathcal{F}^{ op}_{j,c} cdot X_{i+c\%S_{mathcal{P}},c}),这引入了一个偏移范围参数 (S_{mathcal{P}}),即 pseudo-kernel size,表示通道偏移后所有涉及到的计算位置在 HW 空间上的投影的面积,而另一个参数 (i) 表示偏移的起始位置。在代码中取值为 pseudo-kernel 矩形区域内部的中心相对坐标(以区域内部左上角为起点,索引为 0,对矩形区域按照行主序进行排序索引),即start_idx=(self.kernel_size[0]*self.kernel_size[1])//2。
代码解析
这里通过注释的形式对部分核心代码分析。
from torchvision.ops.deform_conv import deform_conv2d as deform_conv2d_tv
class CycleFC(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
kernel_size, # re-defined kernel_size, represent the spatial area of staircase FC
stride: int = 1,
padding: int = 0,
dilation: int = 1,
groups: int = 1,
bias: bool = True,
):
"""
这里的kernel_size实际使用的时候时3x1或者1x3
"""
super(CycleFC, self).__init__()
if in_channels % groups != 0:
raise ValueError('in_channels must be divisible by groups')
if out_channels % groups != 0:
raise ValueError('out_channels must be divisible by groups')
if stride != 1:
raise ValueError('stride must be 1')
if padding != 0:
raise ValueError('padding must be 0')
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = kernel_size
self.stride = _pair(stride)
self.padding = _pair(padding)
self.dilation = _pair(dilation)
self.groups = groups
# 被偏移调整的1x1卷积的权重,由于后面使用torchvision提供的可变形卷积的函数,所以权重需要自己构造
self.weight = nn.Parameter(torch.empty(out_channels, in_channels // groups, 1, 1))
# kernel size == 1
if bias:
self.bias = nn.Parameter(torch.empty(out_channels))
else:
self.register_parameter('bias', None)
# 要注意,这里是在注册一个buffer,是一个常量,不可学习,但是可以保存到模型权重中。
self.register_buffer('offset', self.gen_offset())
def gen_offset(self):
"""
生成卷积核偏移量的核心操作。
要想理解这一函数的操作,需要首先理解后面使用的deform_conv2d_tv的具体用法。
具体可见:https://pytorch.org/vision/0.10/ops.html#torchvision.ops.deform_conv2d
这里对于offset参数的要求是:
offset (Tensor[batch_size,
2 * offset_groups * kernel_height * kernel_width,
out_height,
out_width])
– offsets to be applied for each position in the convolution kernel.
也就是说,对于样本s的输出特征图的通道c中的位置(x,y),这个函数会从offset中取出,形状为
kernel_height*kernel_width的卷积核所对应的偏移参数为
offset[s, 0:2*offset_groups*kernel_height*kernel_width, x, y]
也就是这一系列参数都是对应样本s的单个位置(x,y)的。
针对不同的位置可以有不同的offset,也可以有相同的(下面的实现就是后者)。
对于这2*offset_groups*kernel_height*kernel_width个数,涉及到对于输入特征通道的分组。
将其分成offset_groups组,每份单独拥有一组对应于卷积核中心位置的相对偏移量,
共2*kernel_height*kernel_width个数。
对于每个核参数,使用两个量来描述偏移,即h方向和w方向相对中心位置的偏移,
即下面代码中的减去kernel_height//2或者kernel_width//2。
需要注意的是,当偏移位置位于padding后的tensor边界外,则是将网格使用0补齐。
如果网格上有边界值,则使用边界值和用0补齐的网格顶点来计算双线性插值的结果。
"""
offset = torch.empty(1, self.in_channels*2, 1, 1)
start_idx = (self.kernel_size[0] * self.kernel_size[1]) // 2
assert self.kernel_size[0] == 1 or self.kernel_size[1] == 1, self.kernel_size
for i in range(self.in_channels):
if self.kernel_size[0] == 1:
offset[0, 2 * i + 0, 0, 0] = 0
# 这里计算了一个相对偏移位置。
# deform_conv2d使用的以对应输出位置为中心的偏移坐标索引方式
offset[0, 2 * i + 1, 0, 0] = (
(i + start_idx) % self.kernel_size[1] - (self.kernel_size[1] // 2)
)
else:
offset[0, 2 * i + 0, 0, 0] = (
(i + start_idx) % self.kernel_size[0] - (self.kernel_size[0] // 2)
)
offset[0, 2 * i + 1, 0, 0] = 0
return offset
def forward(self, input: Tensor) -> Tensor:
"""
Args:
input (Tensor[batch_size, in_channels, in_height, in_width]): input tensor
"""
B, C, H, W = input.size()
return deform_conv2d_tv(input,
self.offset.expand(B, -1, H, W),
self.weight,
self.bias,
stride=self.stride,
padding=self.padding,
dilation=self.dilation)
由于这里关于 offset 的生成有些让人疑惑的地方,我也给作者提了 issue(https://github.com/ShoufaChen/CycleMLP/issues/11),同时附了一个关于 deform_conv2d 的小例子。
这里作者给提供了一个与代码更贴合的图示:
class CycleMLP(nn.Module):
def __init__(self, dim, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.mlp_c = nn.Linear(dim, dim, bias=qkv_bias)
self.sfc_h = CycleFC(dim, dim, (1, 3), 1, 0)
self.sfc_w = CycleFC(dim, dim, (3, 1), 1, 0)
self.reweight = Mlp(dim, dim // 4, dim * 3)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, H, W, C = x.shape
h = self.sfc_h(x.permute(0, 3, 1, 2)).permute(0, 2, 3, 1)
w = self.sfc_w(x.permute(0, 3, 1, 2)).permute(0, 2, 3, 1)
c = self.mlp_c(x)
a = (h + w + c).permute(0, 3, 1, 2).flatten(2).mean(2)
a = self.reweight(a).reshape(B, C, 3).permute(2, 0, 1).softmax(dim=0).unsqueeze(2).unsqueeze(2)
x = h * a[0] + w * a[1] + c * a[2]
x = self.proj(x)
x = self.proj_drop(x)
return x
从代码中可以看到,在实际使用的时候,是基于类似于 Inception V3 中分形卷积的形式,构建了 1x3 和 3x1 的两组并行操作。另外也有一个普通的通道 MLP 来进行单个位置的处理。从而构建了一个三分支结构。
which is inspired by the factorization of convolution [47] and criss-cross attention [26].
实验效果
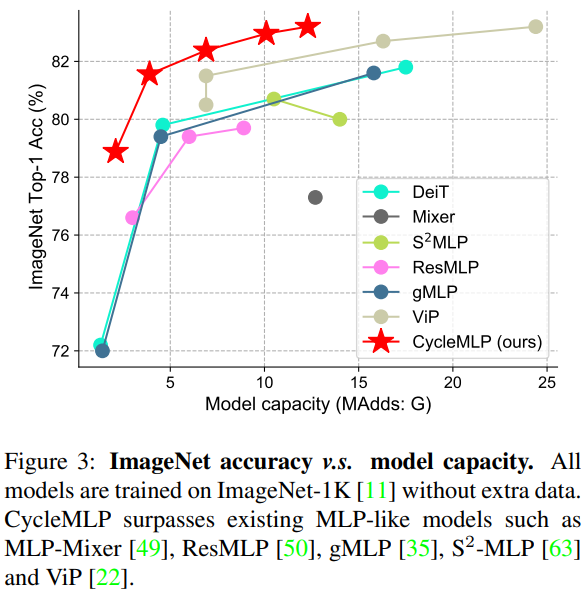
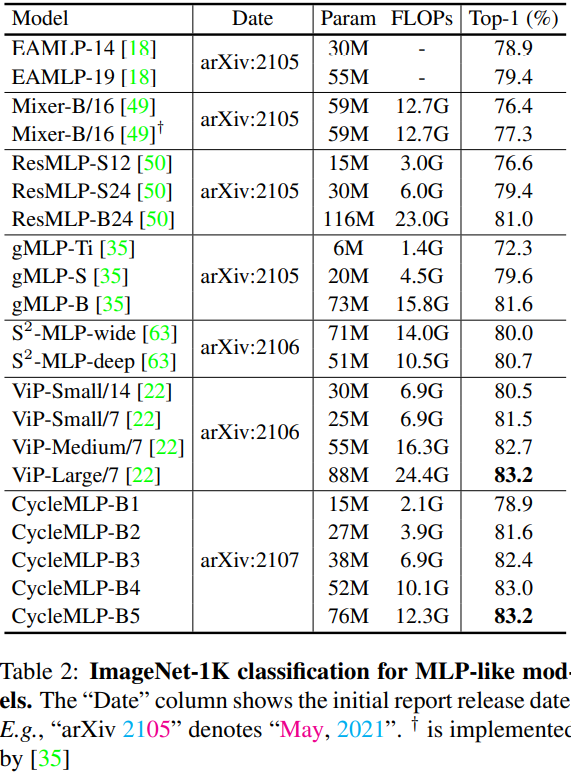
和同期 MLP 方法的比较
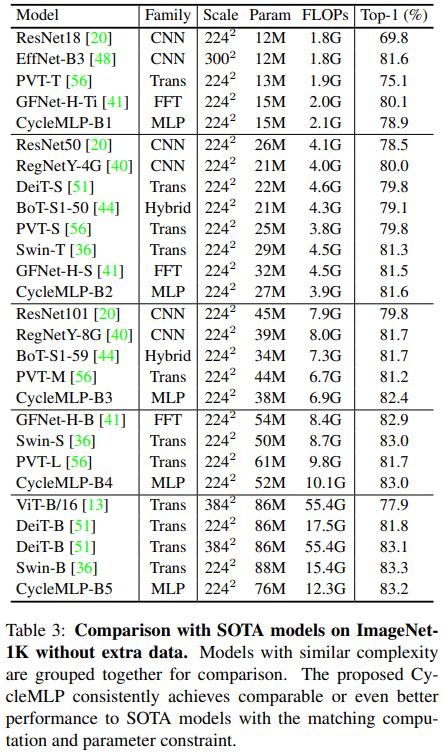
这里作者提到了 GFNet,它使用了 FFT 来学习空间特征,并且计算量也更少,与 CycleMLP 也有着相近的性能。但是其受输入分辨率的制约,如果想要更改输入分辨率则需要使用参数插值。这可能会损害密集预测任务的性能。(这真的会有很大影响么?)
另外,作者们也补充了关于不同测试分辨率和不同分支的影响的消融实验。

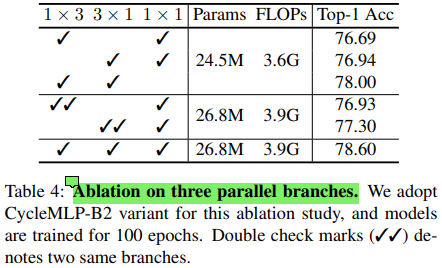
这两个实验展现出了一些有趣的现象。
- 首先看分辨率的影响, 可以看到,最优的测试粉笔那缕可能并不是与原始训练一致。结果中反映出了 CycleFC 对于测试尺寸的稳定性。
- 但是这里要注意的是,这里的实验从代码中可以看到,测试中使用的是先放大到指定尺寸的 $$frac{256}{224}$$ 倍后再从中心 crop 出对应的尺寸的操作方式。而其他形式的数据处理的对应的现象仍需进行更多的实验验证。
- 表 4 中关于多分支结构中的三个分支进行了消融实验。可以看到,操作多样性对于多分支结构是具有正向增益的。
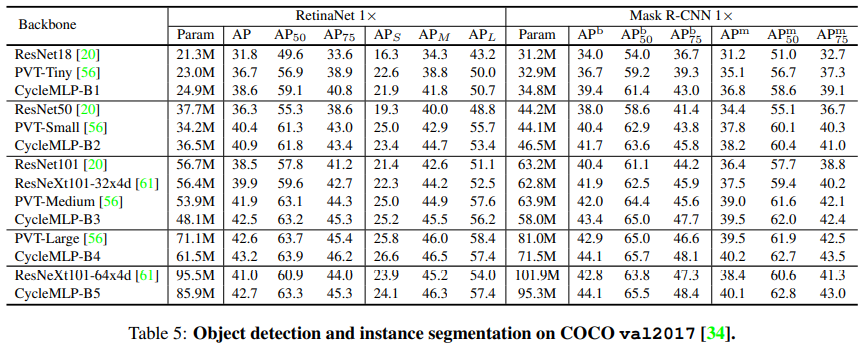
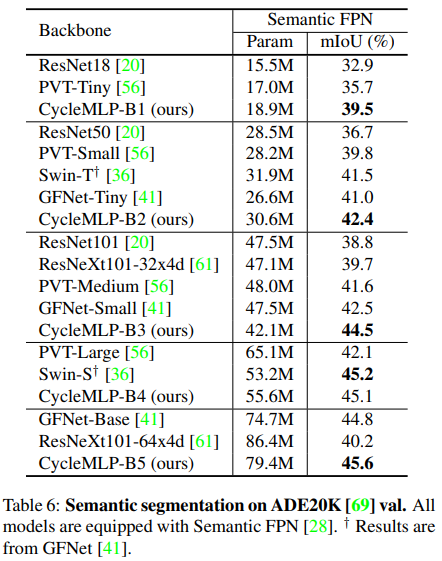
也通过在检测和分割任务上的表现展现出了提出结构(更灵活的输入尺寸、更高效的空间计算)的有效性。