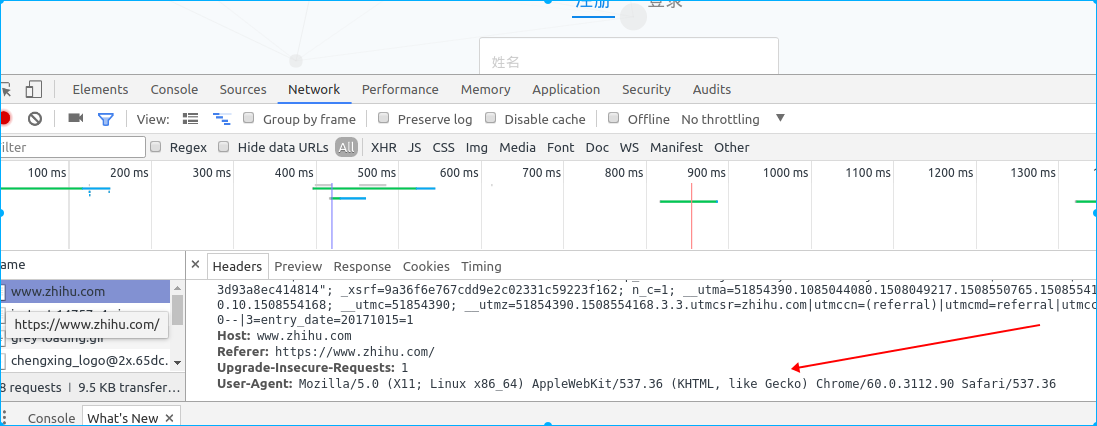
了解http常见状态码
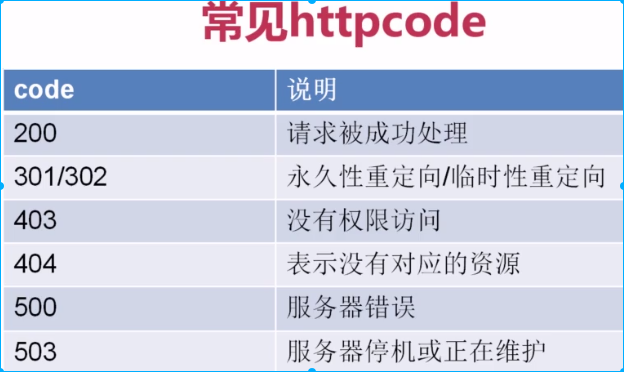
可以通过输入错误的密码来找到登陆知乎的post:url

把Headers拉到底部,可以看到form data
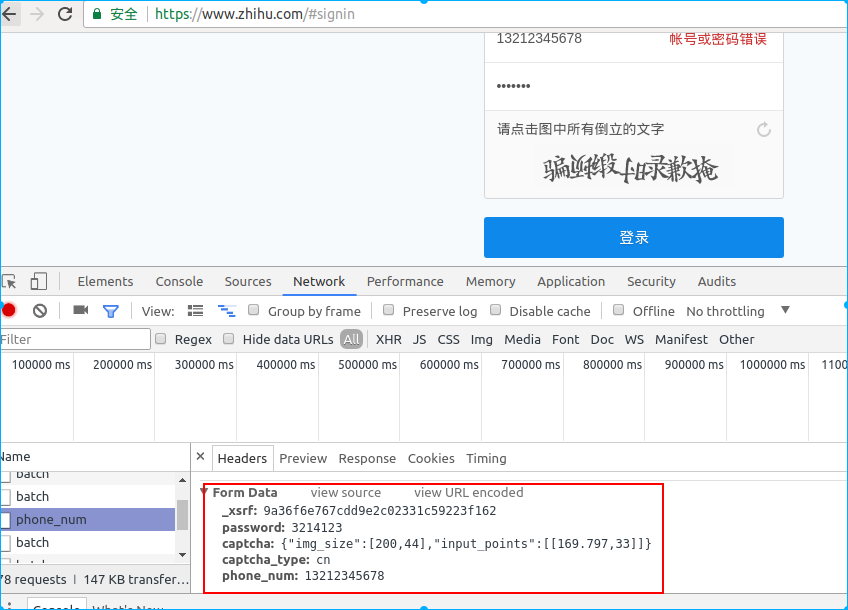
_xsrf是需要发送的,需要发送给服务端,否则会返回403错误,提示用户没权限访问
获取xsrf的方法:
# -*- coding: utf-8 -*- import requests,re #py2里叫cookielib,py3里叫cookiejar try: import cookielib except: import http.cookiejar as cookielib #拿到浏览器设置的用户代理 User_Agent = "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.90 Safari/537.36" #定义header,注意:header里的key是固定的 header = { "HOST":"www.zhihu.com", "Referer":"https://www.zhihu.com", "User-Agent":User_Agent } def get_xsrf(): #可以通过自定义请求头来传入User-Agent response = requests.get("http://www.zhihu.com",headers=header) print(response.text) return '' get_xsrf()
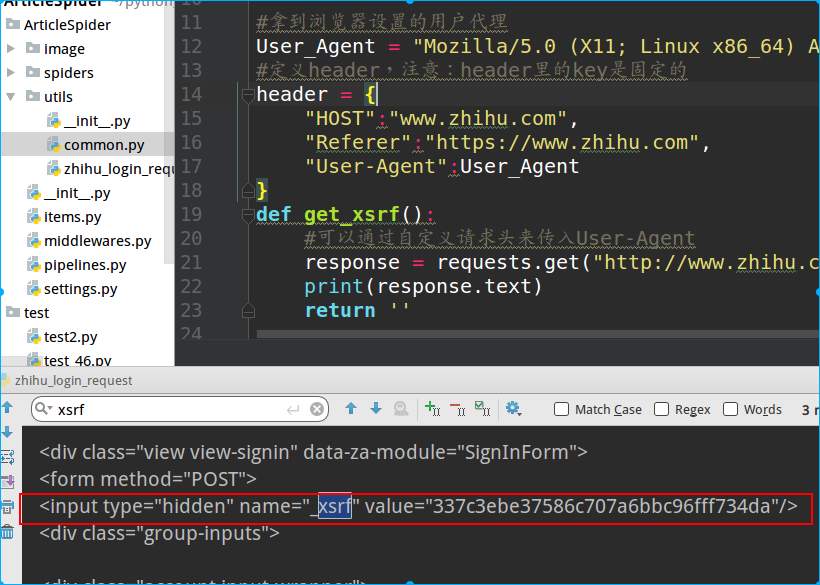
接着使用re模块来获取到这一行数值
#如果匹配不到,那可能是中间有换行符的原因,可以加上re.dotall match_obj = re.match('.*name="_xsrf" value="(.*?)"', response.text, re.DOTALL)
每次查看知乎页面要用get和post创建新连接效率不高,可以使用session,后面使用requests的方法就在session上调用
session = requests.session()
session = requests.session() #给session的cookies方法重新指定,cookielib类实例出来的LWPCookieJar方法可以很方便的保存文件 #可以指定一个文件名,如果文件不存在会自动创建。 session.cookies = cookielib.LWPCookieJar(filename="cookies.txt") try: #加载cookies session.cookies.load(ignore_discard=True) except: print("cookie未能加载") def get_index(): """ 前面用session保存了cookie到本地,这里我再用session调用get方法时,会自动把cookie带过去。 :return: """ response = session.get("https://www.zhihu.com", headers=header) with open("index_page.html","wb") as f: f.write(response.text.encode('utf-8')) print("OK")
要判断是否已登陆,可以访问一些需要登陆才有权限访问的页面,比如知乎页面的登陆后的我的私信页面,用FireFox可以先看到返回状态:302临时重定向
接着301重定向,不过我用chrome检测,直接从第三行数据开始展示

所以可以获取状态码来判断是否登陆:
PS:get方法有个参数allow_redirects是否允许重定向,默认是True,如果访问的url状态是301/302,则会去访问重定向的url
def is_login(): #通过个人的私信页面判断是否已登陆 inbox_url = "https://www.zhihu.com/inbox" #allow_redirects参数是否跳转到重定向的url response = session.get(inbox_url,headers=header,allow_redirects=False) if response.status_code != 200: status_code = False else: status_code = True return status_code
测试获取xsrf时服务器返回500错误,这个是因为使用requests模块时,没有设置浏览器的用户代理,不同的浏览器这个值是不一样的,有的服务器会验证这个是否合法的,这是服务器的一种防御策略。
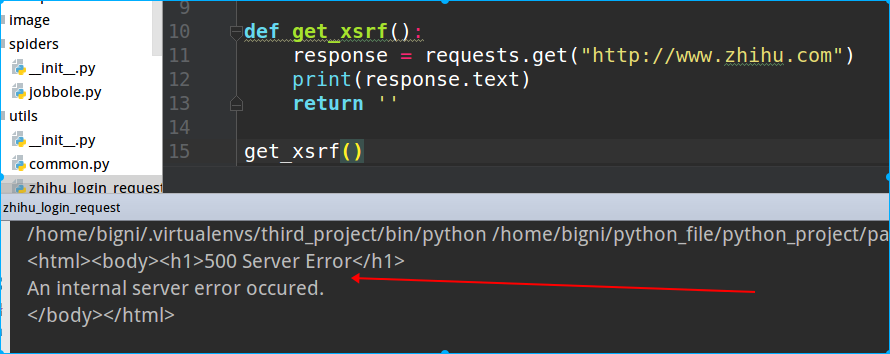
处理方法:
在知乎登陆界面F12,刷新页面,找到Header请求头: