系统版本:CentOS 7.4
top
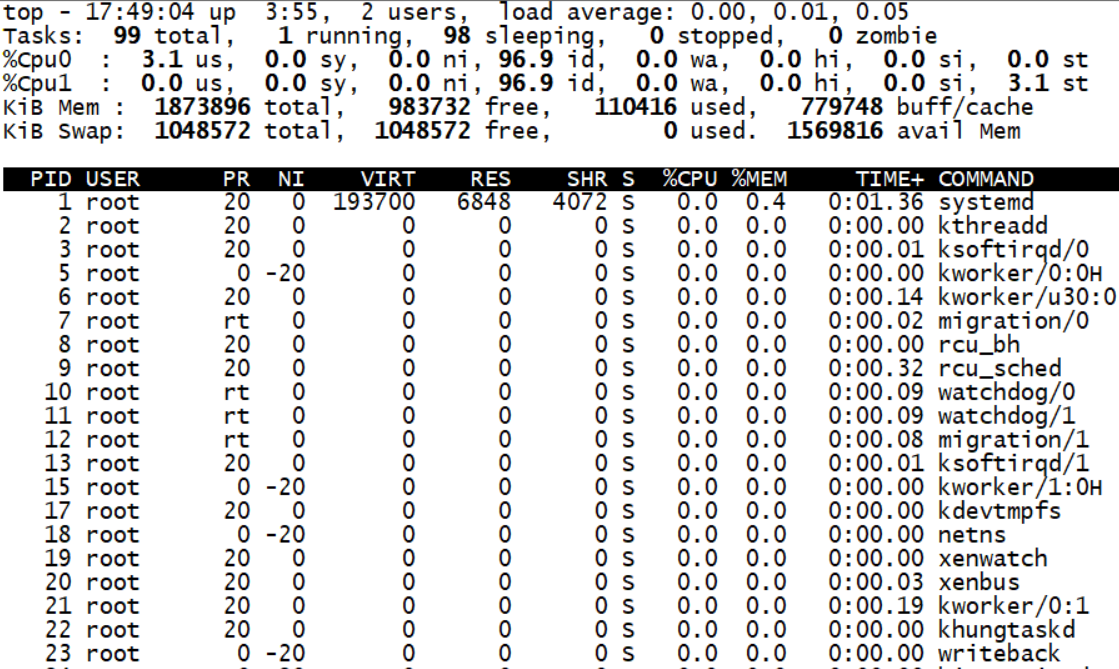
17:49:04 // 当前时间
up 3:55 // 系统运行时间,格式为时:分
2 users // 当前登录用户数
load average // 三个值分别为 1分钟,5分钟,15分钟内的系统负载,当这个值超过 CPU 可执行单元的数目,表示 CPU 的性能已成为瓶颈。
Tasks // 进程总数
running // 正在运行的进程数,包括正在 CPU 上运行的和将要被调度运行的
sleeping // 睡眠的进程数, 通常是等待事件(比如 IO 操作)完成的任务,细分可以包括 interruptible 和 uninterruptible 的类型;
stopped // 停止的进程数
zombie // 僵尸进程数
us // 用户空间占用 CPU 百分比
sy // 内核空间占用 CPU 百分比,操作系统通过系统调用(system call)从用户态陷入内核态,以执行特定的服务;但是当服务器执行的 IO 比较
密集的时候,该值会比较大
ni // 用户进程空间内改变过优先级的进程占用CPU百分比
id // 空闲CPU百分比
wa // 等待 IO 输入输出的CPU时间百分比
hi // 硬中断占用百分比
si // 软中断占用百分比
st // 虚拟机占用百分比
PID // 每个进程的 ID
USER // 每个进程所有者的用户名
PR // 每个进程的优先级别
NI // 该进程的优先级值
VIRT // 进程需要的虚拟内存大小,包括进程使用的库,代码,数据等
RES // 该进程占用的物理内存的总数量,单位是 KB
SHR // 该进程使用共享内存的数量
S // 进程状态(D=不可中断的睡眠状态,R=运行,S=睡眠,T=跟踪/停止, Z=僵尸进程)
%CPU // 该进程自最近一次刷新一来所占用的CPU时间和总时间的百分比
%MEM // 该进程占用的物理内存占总内存的百分比
TIME+ // 该进程自启动以来所占用的总 CPU 时间。
COMMAND // 该进程的命令名称。
S 列(也就是 Status 列)表示进程的状态。
R 是 Running 或 Runnable 的缩写,表示进程在 CPU 的就绪队列中,正在运行或者正在等待运行。
D 是 Disk Sleep 的缩写,也就是不可中断状态睡眠(Uninterruptible Sleep),一般表示进程正在跟硬件交互,并且交互过程不允许被其他进程或中断打断。
Z 是 Zombie 的缩写,它表示僵尸进程,也就是进程实际上已经结束了,但是父进程还没有回收它的资源(比如进程的描述符、PID 等)。
S 是 Interruptible Sleep 的缩写,也就是可中断状态睡眠,表示进程因为等待某个事件而被系统挂起。当进程等待的事件发生时,它会被唤醒并进入 R 状态。
I 是 Idle 的缩写,也就是空闲状态,用在不可中断睡眠的内核线程上。前面说了,硬件交互导致的不可中断进程用 D 表示,但对某些内核线程来说,它们有可能实际上并没有任何负载,用 Idle 正是为了
区分这种情况。要注意,D 状态的进程会导致平均负载升高, I 状态的进程却不会。
T 或者 t,也就是 Stopped 或 Traced 的缩写,表示进程处于暂停或者跟踪状态。向一个进程发送 SIGSTOP 信号,它就会因响应这个信号变成暂停状态(Stopped);再向它发送 SIGCONT 信号,进程又
会恢复运行。
X 是 Dead 的缩写,表示进程已经消亡,所以你不会在 top 或者 ps 命令中看到它。
s 表示这个进程是一个会话的领导进程,会话是指共享同一个控制终端的一个或多个进程组。
+ 表示前台进程组。进程组表示一组相互关联的进程,比如每个子进程都是父进程所在组的成员
比如,我们通过 SSH 登录服务器,就会打开一个控制终端(TTY),这个控制终端就对应一个会话。而我们在终端中运行的命令以及它们的子进程,就构成了一个个的进程组,其中,在后台运行的命令,构成后台进程组;在前台运行的命令,构成前台进程组。
CPU 占用率高很多情况下意味着一些东西,这也给服务器 CPU 使用率过高情况下指明了相应地排查思路:
当 user 占用率过高的时候,通常是某些个别的进程占用了大量的 CPU,这时候很容易通过 top 找到该程序;此时如果怀疑程序异常,可以通过 perf 等思路找出热点调用函数来进一步排查;
当 system 占用率过高的时候,如果 IO 操作(包括终端 IO)比较多,可能会造成这部分的 CPU 占用率高,比如在 file server、database server 等类型的服务器上,否则(比如>20%)很可能有些部分的内核、驱动模块有问题;
当 nice 占用率过高的时候,通常是有意行为,当进程的发起者知道某些进程占用较高的 CPU,会设置其 nice 值确保不会淹没其他进程对 CPU 的使用请求;
当 iowait 占用率过高的时候,通常意味着某些程序的 IO 操作效率很低,或者 IO 对应设备的性能很低以至于读写操作需要很长的时间来完成;
当 irq/softirq 占用率过高的时候,很可能某些外设出现问题,导致产生大量的irq请求,这时候通过检查 /proc/interrupts 文件来深究问题所在;
当 steal 占用率过高的时候,黑心厂商虚拟机超售了!
uptime

14:01:02 //系统当前时间
up 3 days, 7 min //主机已运行时间
2 users //当前登录用户数
load average: 0.00, 0.01, 0.05 //三个值分别为 1分钟,5分钟,15分钟内的系统平均负载
注意:平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数,它和 CPU 使用率并没有直接关系。
vmstat
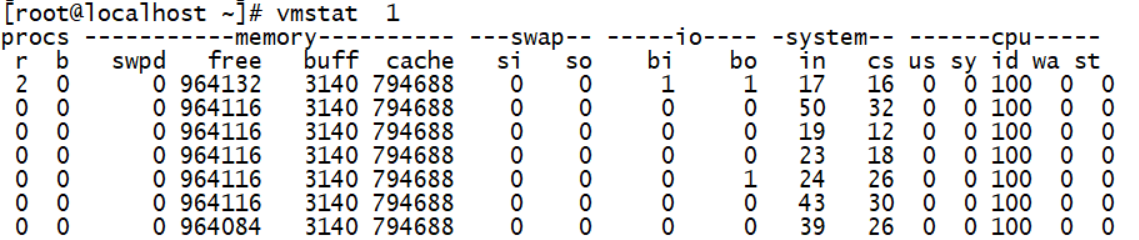
(Procs) r // 运行队列中进程数量
(Procs) b // 等待 IO 的进程数量
(Memory) swpd // 使用虚拟内存大小
(Memory) free // 可用内存大小
(Memory) buff // 用作缓冲的内存大小
(Memory) cache // 用作缓存的内存大小
(Swap) si // 每秒从交换区写到内存的大小
(Swap) so // 每秒写入交换区的内存大小
(IO) bi // 每秒读取的块数
(IO) bo // 每秒写入的块数
(System) in // 每秒中断数,包括时钟中断
(System) cs // 每秒上下文切换数
(CPU) us // 用户进程执行时间 (user time)
(CPU) sy // 系统进程执行时间 (system time)
(CPU) id // 空闲时间(包括 IO 等待时间)
(CPU) wa // 等待IO时间

指令介绍
-a :显示活跃和非活跃内存
-f :显示从系统启动至今的fork数量。
-m :显示slabinfo
-n :只在开始时显示一次各字段名称。
-s∶显示内存相关统计信息及多种系统活动数。
delay :刷新时间间隔。如果不指定,只显示—条结果。
count :刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷。
-d:显示磁盘相关统计信息。
-p∶显示指定磁盘分区统计信息
-S︰使用指定单位显示。参数有k ,K, m,M,分别代表1000,1024,1000000,1048576字节。默认单位为K ( 1024 bytes )
-V :显示vmstat版本信息。
安装 sysstat-12.0.1
yum install gcc gcc-c++ wget -y
wget http://sebastien.godard.pagesperso-orange.fr/sysstat-12.0.1.tar.gz
tar zxvf sysstat-12.0.1.tar.gz
cd sysstat-12.0.1
./configure
make && make install
mpstat

%user // 表示处理用户进程所使用CPU的百分比。注意,它不包括下面的 nice 时间,但包括了 guest 时间。
%nice // 代表低优先级用户态 CPU 时间,也就是进程的 nice 值被调整为 1-19 之间时的 CPU 时间。这里注意,nice 可取值范围是 -20 到 19,数值越大,优先级反而越低。
%sys // 表示内核进程使用的CPU百分比;
%iowait // 表示等待进行I/O所使用的CPU时间百分比;
%irq // 代表处理硬中断的 CPU 时间。
%soft // 表示用于软件中断的CPU百分比;
%idle // 显示CPU的空闲时间;注意,它不包括等待 I/O 的时间(iowait)
steal //(通常缩写为 st),代表当系统运行在虚拟机中的时候,被其他虚拟机占用的 CPU 时间。
guest //(通常缩写为 guest),代表通过虚拟化运行其他操作系统的时间,也就是运行虚拟机的 CPU 时间。
guest_nice //(通常缩写为 gnice),代表以低优先级运行虚拟机的时间。
# 显示所有CPU的指标,并在间隔5秒输出一组数据
$ mpstat -P ALL 5 1
Linux 4.15.0 (ubuntu) 09/22/18 _x86_64_ (2 CPU)
13:41:28 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
13:41:33 all 0.21 0.00 12.07 32.67 0.00 0.21 0.00 0.00 0.00 54.84
13:41:33 0 0.43 0.00 23.87 67.53 0.00 0.43 0.00 0.00 0.00 7.74
13:41:33 1 0.00 0.00 0.81 0.20 0.00 0.00 0.00 0.00 0.00 98.99
sar

%user // 显示在用户级别(application)运行使用CPU总时间的百分比。
%nice // 代表低优先级用户态 CPU 时间,也就是进程的 nice 值被调整为 1-19 之间时的 CPU 时间。这里注意,nice 可取值范围是 -20 到 19,数值越大,优先级反而越低。
%system // 在核心级别(kernel) 运行所使用CPU总时间的百分比。
%iowait // 显示用于等待I/O操作占用CPU总时间的百分比。
%steal // 管理程序(hypervisor)为另一虚拟进程提供服务而等待虚拟CPU的百分比。
%idle // 显示CPU空闲时间占用CPU总时间的百分比。
1.若 %iowait 的值过高,表示硬盘存在I/O瓶颈
2.若 %idle 高但是系统响应慢时,可能是CPU等待分配内存,此时应加大内存容量
3.若 %idle 的值持续低于1,则系统的CPU处理能力相对较低,表明系统中最需要解决的资源是CPU。
如果要查看二进制文件 test 中的内容,需键入如下sar命令:
sar -u -f test
-u : 输出cpu使用情况和统计信息
-f : 从制定的文件读取报告
pidstat
用法:
pidstat [ 选项 ] [ <时间间隔> ] [ <次数> ]
常用的参数:
-u:默认的参数,显示各个进程的cpu使用统计
-r:显示各个进程的内存使用统计
-d:显示各个进程的IO使用情况
-p:指定进程号
-w:显示每个进程的上下文切换情况
-t:显示选择任务的线程的统计信息外的额外信息
-T { TASK | CHILD | ALL }
这个选项指定了pidstat监控的。TASK表示报告独立的task,CHILD关键字表示报告进程下所有线程统计信息。ALL表示报告独立的task和task下面的所有线程。
注意:task和子线程的全局的统计信息和pidstat选项无关。这些统计信息不会对应到当前的统计间隔,这些统计信息只有在子线程kill或者完成的时候才会被收集。
-V:版本号
-h:在一行上显示了所有活动,这样其他程序可以容易解析。
-I:在SMP环境,表示任务的CPU使用率/内核数量
-l:显示命令名和所有参数
cpu使用情况统计(-u)
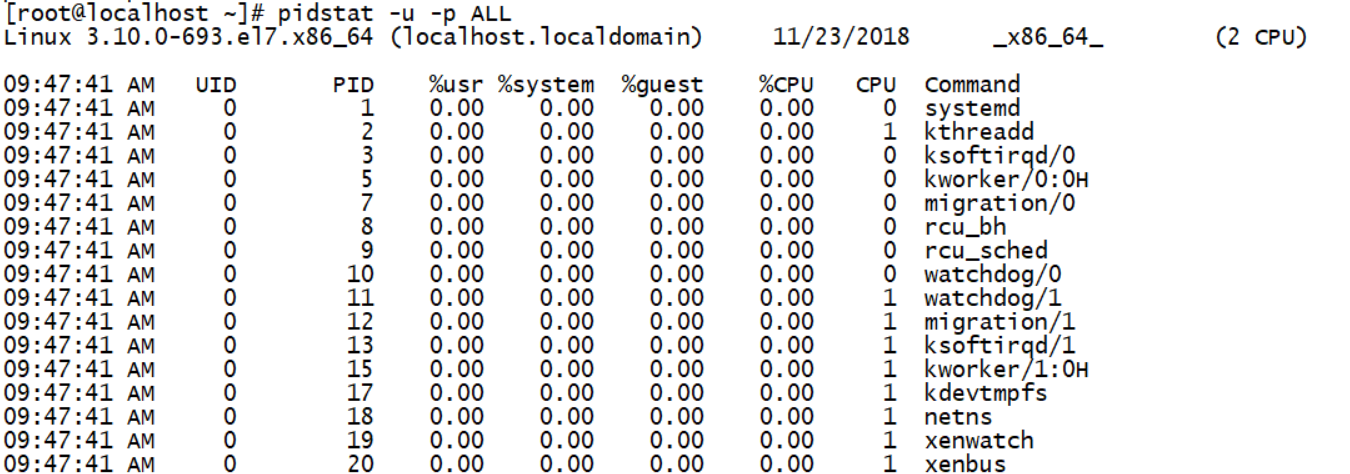
PID // 进程ID
%usr // 进程在用户空间占用cpu的百分比
%system // 进程在内核空间占用cpu的百分比
%guest // 进程在虚拟机占用cpu的百分比
%CPU // 进程占用cpu的百分比
CPU // 处理进程的cpu编号
Command // 当前进程对应的命令
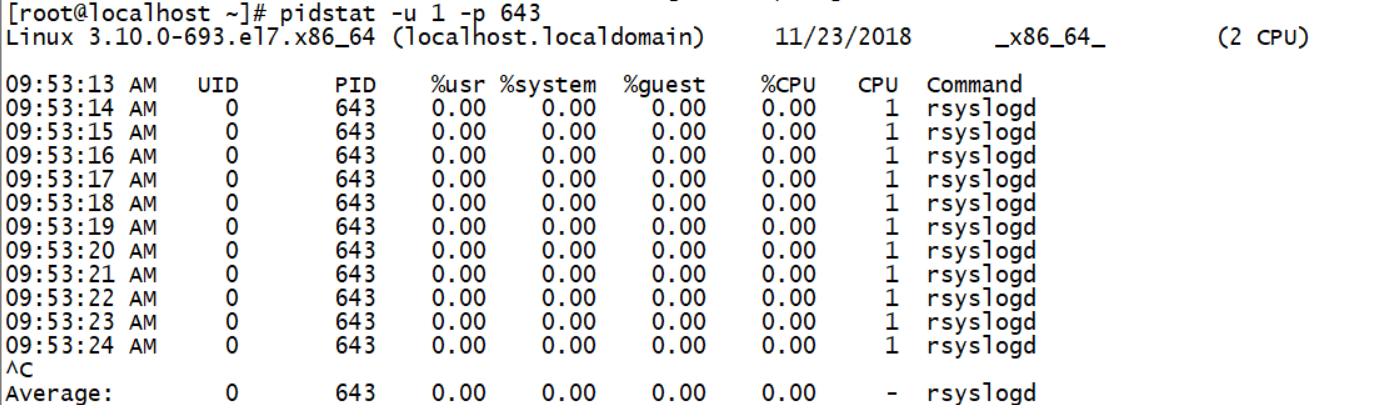
UID // 执行进程的 UID
PID // 进程ID
%usr // 进程在用户空间占用cpu的百分比
%system // 进程在内核空间占用cpu的百分比
%guest // 进程在虚拟机占用cpu的百分比
%CPU // 进程占用cpu的百分比
CPU // 处理进程的cpu编号
Command // 当前进程对应的命令
显示各个进程的IO使用情况(-d)
PID: 进程id
kB_rd/s: 每秒从磁盘读取的KB
kB_wr/s: 每秒写入磁盘KB
kB_ccwr/s: 任务取消的写入磁盘的KB。当任务截断脏的pagecache的时候会发生。
COMMAND: task的命令名
显示各个进程的上下文切换情况(-w)
# 每隔5秒输出1组数据
$ pidstat -w 5
Linux 4.15.0 (ubuntu) 09/23/18 _x86_64_ (2 CPU)
08:18:26 UID PID cswch/s nvcswch/s Command
08:18:31 0 1 0.20 0.00 systemd
08:18:31 0 8 5.40 0.00 rcu_sched
这个结果中有两列内容是我们的重点关注对象。
一个是 cswch ,表示每秒自愿上下文切换(voluntary context switches)的次数,
一个是 nvcswch ,表示每秒非自愿上下文切换(non voluntary context switches)的次数。
这两个概念意味着不同的性能问题:
所谓自愿上下文切换,是指进程无法获取所需资源,导致的上下文切换。比如说, I/O、内存等系统资源不足时,就会发生自愿上下文切换。
而非自愿上下文切换,则是指进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换。比如说,大量进程都在争抢 CPU 时,就容易发生非自愿上下文切换。
每秒上下文切换多少次才算正常呢?这个数值其实取决于系统本身的 CPU 性能。如果系统的上下文切换次数比较稳定,那么从数百到一万以内,都应该算是正常的。
但当上下文切换次数超过一万次,或者切换次数出现数量级的增长时,就很可能已经出现了性能问题。这时,你还需要根据上下文切换的类型,再做具体分析。
比方说:
1. 自愿上下文切换变多了,说明进程都在等待资源,有可能发生了 I/O 等其他问题;
2. 非自愿上下文切换变多了,说明进程都在被强制调度,也就是都在争抢 CPU,说明 CPU 的确成了瓶颈;
3. 中断次数变多了,说明 CPU 被中断处理程序占用,还需要通过查看 /proc/interrupts 文件来分析具体的中断类型。
execsnoop
一个专为短时进程设计的工具。它通过 ftrace 实时监控进程的 exec() 行为,并输出短时进程的基本信息,包括进程 PID、父进程 PID、命令行参数以及执行的结果。
# 下载
cd /usr/local/sbin/
wget https://raw.githubusercontent.com/brendangregg/perf-tools/master/execsnoop
chmod 755 execsnoop
# 运行
execsnoop