1、求每年的最高温度
数据格式如下:
0067011990999991950051507004888888889999999N9+00001+9999999999999999999999
0067011990999991950051512004888888889999999N9+00221+9999999999999999999999
0067011990999991950051518004888888889999999N9-00111+9999999999999999999999
0067011990999991949032412004888888889999999N9+01111+9999999999999999999999
0067011990999991950032418004888888880500001N9+00001+9999999999999999999999
0067011990999991950051507004888888880500001N9+00781+9999999999999999999999
代码:
package com.test
import org.apache.spark.{SparkConf,SparkContext}
/**
* Created by hadoop on 2016/10/23.
* 计算每年的最高温度
* C:UsersAdministratorIdeaProjectssparkTestsrc esources emprature
*/
object MaxTemprature {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setMaster("local[2]").setAppName("MaxTemprature")
val sc=new SparkContext(conf)
val one = sc.textFile("C:\Users\Administrator\IdeaProjects\sparkTest\src\resources\temprature")
val yearAndTemp = one.filter(line => {
val quality = line.substring(50, 51);
var airTemperature = 0
if(line.charAt(45)=='+'){
airTemperature = line.substring(46, 50).toInt
}else{
airTemperature = line.substring(45, 50).toInt
}
airTemperature != 9999 && quality.matches("[01459]")}).map{
line =>{
val year = line.substring(15,19)
var airTemperature = 0
if(line.charAt(45)=='+'){
airTemperature = line.substring(46, 50).toInt
}else{
airTemperature = line.substring(45, 50).toInt
}
(year,airTemperature)
}
}
val res = yearAndTemp.reduceByKey(
(x,y)=> if(x>y) x else y
)
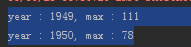
res.collect.foreach(x=>println("year : " + x._1+", max : "+x._2))
}
}
输出结果:
2、数据去重问题
原始数据txt1:
2012-3-1 b
2012-3-2 a
2012-3-3 b
2012-3-4 d
2012-3-5 a
2012-3-6 c
2012-3-7 d
2012-3-3 c
原始数据txt2:
2012-3-1 a
2012-3-2 b
2012-3-3 c
2012-3-4 d
2012-3-5 a
2012-3-6 b
2012-3-7 c
2012-3-3 c
要求输出结果如下:
2012-3-1 a
2012-3-1 b
2012-3-2 a
2012-3-2 b
2012-3-3 b
2012-3-3 c
2012-3-4 d
2012-3-5 a
2012-3-6 b
2012-3-6 c
2012-3-7 c
2012-3-7 d
代码:
package com.test
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by hadoop on 2016/10/23.
* 数据去重
*/
object Demo2 {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setMaster("local[2]").setAppName("Demo2")
val sc=new SparkContext(conf)
val two = sc.textFile("C:\Users\Administrator\IdeaProjects\sparkTest\src\resources\demo2")
two.filter(_.trim().length>0).map(line=>(line.trim,"")).groupByKey().sortByKey().keys.collect.foreach(println _)
}
}
输出结果:

3、数据排序
数据输入txt1:
2
32
654
32
15
756
65223
数据输入txt2:
5956
22
650
92
数据输入txt3:
26
54
6
输出结果:
1 2
2 6
3 15
4 22
5 26
6 32
7 32
8 54
9 92
10 650
11 654
12 756
13 5956
14 65223
代码:
package com.test
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by hadoop on 2016/10/23.
* 数据排序
*/
object Demo3 {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setMaster("local[2]").setAppName("Demo3")
val sc=new SparkContext(conf)
val three = sc.textFile("C:\Users\Administrator\IdeaProjects\sparkTest\src\resources\demo3",3)
var idx = 0
import org.apache.spark.HashPartitioner
val res = three.filter(_.trim().length>0).map(num=>(num.trim.toInt,"")).partitionBy(new HashPartitioner(1)).sortByKey().map(t => {
idx += 1
(idx,t._1)
}).collect.foreach(x => println(x._1 +" " + x._2) )
}
}
4、平均成绩:
4.1、需求分析
对输入文件中数据进行就算学生平均成绩。输入文件中的每行内容均为一个学生的姓名和他相应的成绩,如果有多门学科,则每门学科为一个文件。
要求在输出中每行有两个间隔的数据,其中,第一个代表学生的姓名,第二个代表其平均成绩。
4.2、原始数据
1.math
张三 88
李四 99
王五 66
赵六 77
2.chinese
张三 78
李四 89
王五 96
赵六 67
3.english
张三 80
李四 82
王五 84
赵六 86
输出:
张三 82
李四 90
王五 82
赵六 76
//代码
package com.test
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by hadoop on 2016/10/23.
* 求平均成绩
* 思路:先groupBy分组,再map处理成绩的集合
*/
object Demo4 {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setMaster("local[2]").setAppName("Demo4")
val sc=new SparkContext(conf)
val fourth = sc.textFile("C:\Users\Administrator\IdeaProjects\sparkTest\src\resources\demo4",3)
val res = fourth.filter(_.trim().length>0).map(line=>(line.split(" ")(0).trim(),line.split(" ")(1).trim().toInt)).groupByKey().map(x => {
var num = 0.0
var sum = 0
for(i <- x._2){
sum = sum + i
num = num +1
}
val avg = sum/num
val format = f"$avg%1.2f".toDouble
(x._1,format)
}).collect.foreach(x => println(x._1+" "+x._2))
}
}
5、求最大值和最小值
数据输入:
txt1:
102
10
39
109
200
11
3
90
28
txt2:
5
2
30
838
10005
//代码
package com.test
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by hadoop on 2016/10/23.
* 求最大值和最小值
* 思路与Mr类似,先设定一个key,value为需要求最大与最小值的集合,然后再groupBykey聚合在一起处理。
*/
object Demo5 {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setMaster("local[2]").setAppName("Demo5")
val sc=new SparkContext(conf)
val file = "C:\Users\Administrator\IdeaProjects\sparkTest\src\resources\demo5"
val fifth = sc.textFile(file,3)
val res = fifth.filter(_.trim().length>0).map(line => ("key",line.trim.toInt)).groupByKey().map(x => {
var min = Integer.MAX_VALUE
var max = Integer.MIN_VALUE
for(num <- x._2){
if(num>max){
max = num
}
if(num<min){
min = num
}
}
(max,min)
}).collect.foreach(x => {
println("max "+x._1)
println("min "+x._2)
})
}
}
6、TopN并排序
数据输入1:
100,3333,10,100
101,9321,1000,293
102,3881,701,20
103,6791,910,30
104,8888,11,39
数据输入2:
1,9819,100,121
2,8918,2000,111
3,2813,1234,22
4,9100,10,1101
5,3210,490,111
6,1298,28,1211
7,1010,281,90
8,1818,9000,20
输出结果:
1 9000
2 2000
3 1234
4 1000
5 910
代码:
package com.test
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by hadoop on 2016/10/23.
* 求topN并排序
#orderid,userid,payment,productid
求topN的payment值
* spark排序传入false参数即可倒序
*/
object TopN {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setMaster("local[2]").setAppName("TopN")
val sc=new SparkContext(conf)
val file = "C:\Users\Administrator\IdeaProjects\sparkTest\src\resources\demo6"
val six = sc.textFile(file,3)
var idx = 0;
val res = six.filter(x => (x.trim().length>0) && (x.split(",").length==4)).map(_.split(",")(2)).map(x => (x.toInt,"")).sortByKey(false).map(x=>x._1).take(5)
.foreach(x => {
idx = idx+1
println(idx +" "+x)})
}
}
7.二次排序
示例数据如下:
class1 90 class2 56 class1 87 class1 76 class2 88 class1 95 class1 74 class2 87 class2 67 class2 77
要求对第一列升序,第一列相同则第二列降序
|
package com.spark.secondApp
import org.apache.spark.{SparkContext, SparkConf} object SecondarySort { def main(args: Array[String]) { val conf = new SparkConf().setAppName(" Secondary Sort ").setMaster("local") val sc = new SparkContext(conf) val file = sc.textFile("hdfs://worker02:9000/test/secsortdata") val rdd = file.map(line => line.split(" ")). map(x => (x(0),x(1))).groupByKey(). sortByKey(true).map(x => (x._1,x._2.toList.sortWith(_>_))) val rdd2 = rdd.flatMap{ x => val len = x._2.length val array = new Array[(String,String)](len) for(i <- 0 until len) { array(i) = (x._1,x._2(i)) } array } sc.stop() } } |
将8~12行复制到spark-shell中执行后,再使用rdd2.collect,结果如下:

上图中第一列升序排列,第二列降序排列。
Hadoop实现二次排序需要近200行代码,而Spark只需要20多行代码