堆排序与选择排序的关联
一、简单选择排序
-
基本思想:假设排序表为 L[1....n] ,第i趟排序即从L[i,,,,n] 中选择关键字最小的元素与 L(i) 交换,每一趟排序可以确定一个元素的最终位置,这样经过 n-1 趟排序就可以使整个排序表有序。
-
选择排序的执行过程为每次循环遍历数组找出最小(或最大)的数,将其放在数组的有序数列的最后面,每次第i次遍历查找要执行N-i个单位时间,然后要执行N次,故时间复杂度为O(N^2),很简单,比较适合较小的数列的排序。
代码如下:
public static void changeSort(int [] arr) {
for (int i = 0; i < arr.length-1; i++) {
int index = i;
for (int j = i+1; j < arr.length; j++) {
if(arr[j] < arr[index]){
index = j;
}
}
//比完在交换,游标不稳定,故稳定性不稳定
int temp = arr[index];
arr[index] = arr[i];
arr[i] = temp;
}
}
二、堆排序
-
而堆排序是对于选择排序的优化排序,它利用率了最大(最小)堆顶的数最大(最小)的性质,使得找到一个数组找到最大(最小)的元素的操作不需要像选择排序一样消耗N-i的时间。其时间复杂度为O(nlogn)与归并排序一样啊,空间复杂度为O(1)。
-
在介绍堆排序的执行过程前,先要了解几个公式:
- 对于一个根节点 i,其左子树为 2*i+1,其右子树为 2*i+2 ,而最后一个有子树的根节点 a 的位置小于等于 N/2,N是待排序数组的长度。
其执行过程如下:
1.先建立最大(最小)堆(build_heap)
1.1 将数组导入一颗完全二叉树;
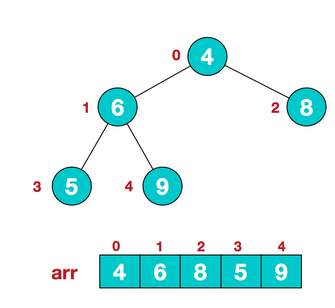
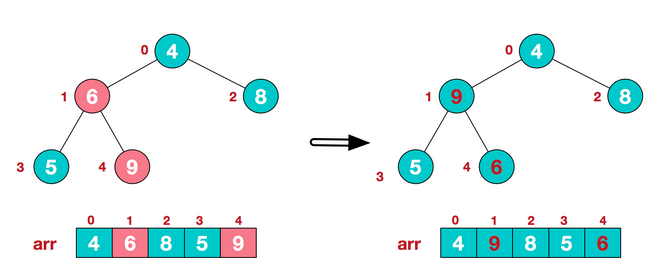
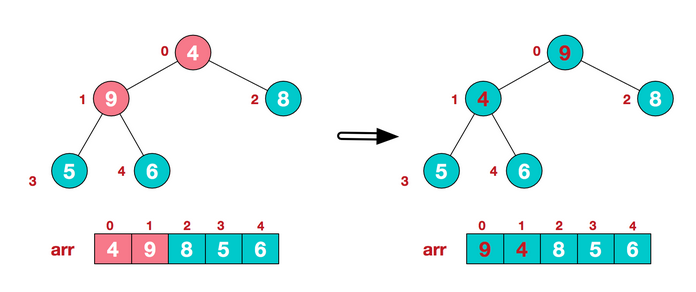
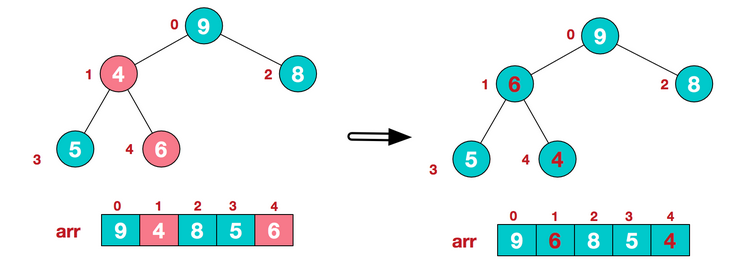
1.2 从倒数第一个有子树的根节点开始建立堆(heapify)(操作就是通过比较和变换使得根节点的大小大于(小于)子树的大小。),然后对前面一个根节点做同样的循环操作,直到堆顶也操作结束,则完成建立整个堆。
在heapify的过程中,我们要在改变了一个子树跟根节点位置后,再向下调整其子树的子树和其子树的位置,直至最后一个子树。
代码如下:
package com.m.suan_pai;
import java.util.Arrays;
public class Test {
public static void main(String[] args) {
int arr[] = new int[]{1, 0, 2, 1, 3, 1, 4, 1, 5, 1, 6, 7, 8, 9};
dumpSort(arr);
}
public static void dumpSort(int[] arr) {
//测试,理解代码
// int i = arr.length / 2 - 1;
// adjust(arr, i, arr.length);
// System.out.println(Arrays.toString(arr));
// i--;
// adjust(arr, i, arr.length);
// System.out.println(Arrays.toString(arr));
// i--;
// adjust(arr, i, arr.length);
// System.out.println(Arrays.toString(arr));
// 寻找最后一个非叶子节点为初始值
for (int i = arr.length / 2 - 1; i >= 0; i--) {
//调整大顶堆
adjust(arr, i, arr.length);
}
//交换堆首与堆尾
for (int i = arr.length - 1; i > 0; i--) {
swap(arr, 0, i);
adjust(arr, 0, i);
}
System.out.println(Arrays.toString(arr));
}
//调整大顶堆
public static void adjust(int[] arr, int i, int length) {
int temp = arr[i];
for (int k = 2 * i + 1; k < length; k = k * 2 + 1) {
if (k + 1 < length && arr[k] < arr[k + 1]) {
k++;
}
if (arr[k] > temp) {
arr[i] = arr[k];
i = k;
} else {
break;
}
}
arr[i] = temp;
}
//交换
public static void swap(int[] arr, int a, int b) {
int t = arr[a];
arr[a] = arr[b];
arr[b] = t;
}
}
堆排序时间复杂度:O(nlogn)
堆排序对原始记录的排序状态并不敏感,其在性能上要远远好过于冒泡、简单选择、直接插入排序。