-
一个典型的kubernetes工作流程
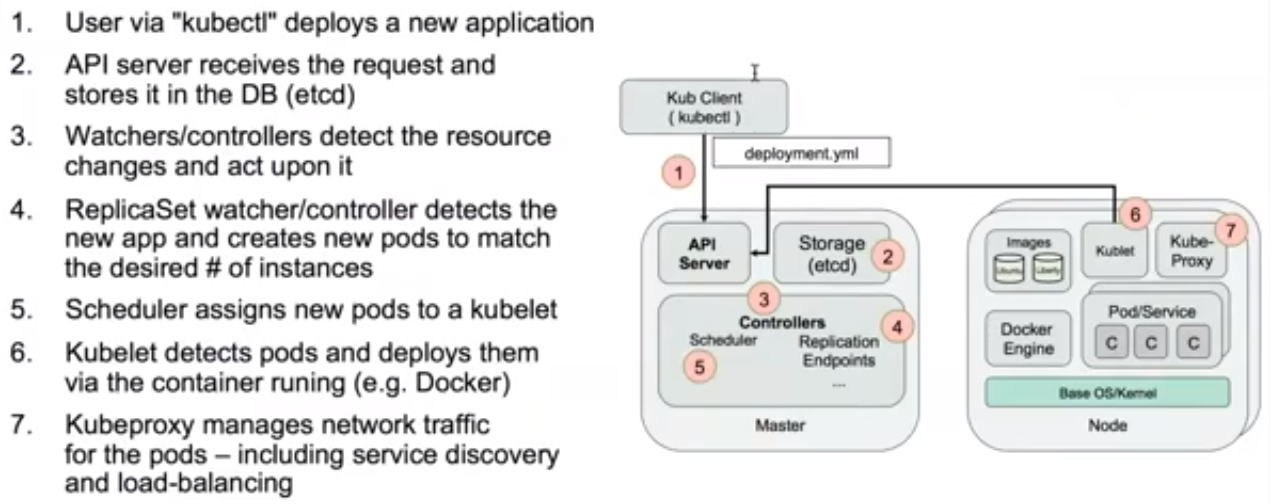
1、准备好一个包含应用程序的Deployment的yml文件,然后通过kubectl客户端工具发送给ApiServer。
2、ApiServer接收到客户端的请求并将资源内容存储到数据库(etcd)中。
3、Controller组件(包括scheduler、replication、endpoint)监控资源变化并作出反应。
4、ReplicaSet检查数据库变化,创建期望数量的pod实例。
5、Scheduler再次检查数据库变化,发现尚未被分配到具体执行节点(node)的Pod,然后根据一组相关规则将pod分配到可以运行它们的节点上,并更新数据库,记录pod分配情况。
6、Kubelete监控数据库变化,管理后续pod的生命周期,发现被分配到它所在的节点上运行的那些pod。如果找到新pod,则会在该节点上运行这个新pod。
7、kuberproxy运行在集群各个主机上,管理网络通信,如服务发现、负载均衡。例如当有数据发送到主机时,将其路由到正确的pod或容器。对于从主机上发出的数据,它可以基于请求地址发现远程服务器,并将数据正确路由,在某些情况下会使用轮训调度算法(Round-robin)将请求发送到集群中的多个实例。
做一个有底蕴的软件工作者
-
相关阅读:
概率图模型课堂笔记:2.4 取样方法
概率图模型课堂笔记:2.2 置信度传播
2018秋季学期学习总结
人生路上影响最大的三位老师
抓老鼠啊~亏了还是赚了?
币值转换
自我介绍
打印沙漏
2019春第七周作业
第六周编程总结
-
原文地址:https://www.cnblogs.com/justmine/p/8684564.html
Copyright © 2020-2023
润新知