7-1 Forever (20 分)
时间限制:3000 ms 内存限制:64 MB
"Forever number" is a positive integer A with K digits, satisfying the following constrains:
- the sum of all the digits of A is m;
- the sum of all the digits of A+1 is n; and
- the greatest common divisor of m and n is a prime number which is greater than 2.
Now you are supposed to find these forever numbers.
Input Specification:
Each input file contains one test case. For each test case, the first line contains a positive integer N (≤5). Then N lines follow, each gives a pair of K (3<K<10) and m (1<m<90), of which the meanings are given in the problem description.
Output Specification:
For each pair of K and m, first print in a line Case X, where X is the case index (starts from 1). Then print n and A in the following line. The numbers must be separated by a space. If the solution is not unique, output in the ascending order of n. If still not unique, output in the ascending order of A. If there is no solution, output No Solution.
Sample Input:
2
6 45
7 80
Sample Output:
Case 1
10 189999
10 279999
10 369999
10 459999
10 549999
10 639999
10 729999
10 819999
10 909999
Case 2
No Solution
解析:
看到这高达3s的时间限制就知道这题不简单……
题目大意:一个K位数A,只要A的各位之和(记为m)与A+1的各位之和(记为n)的最大公约数是一个大于2的质数,就叫做forever numbers。现在给定K和m,求出所有满足条件的A。
所以就是一道大杂烩,既要求最大公约数,又要判断质数,最后还要DFS+剪枝。剪枝的时候考虑:
1、A的最后一位一定是9,如果不是的话无法产生进位,m和n相差1,最大公约数就是1了。进一步考虑,A的最后两位只可能是99。为什么呢?假设A的最后两位是09,则A+1最后两位为10,所以m和n相差8。对于两个相差为8的数,最大公约数只能是1、2、4、8,(为什么3不是最大公约数呢?因为3至多只会是其中一个的约数,其他的数同理)而这几个数都不满足题意。同理,A的最后两位是19、29...89都不满足题意,所以A的最后两位只可能是99。再考虑最后三位可不可能是999,假设最后三位是099,则A+1最后三位为100,m和n相差17,17是有可能成为m和n的最大公约数的,满足条件。因此往这个方向的思路就此中断,只能得到最后两位一定是99。
2、感谢@陌上楼头 提供思路。假设A的末位连续的9有nineNum个,A+1使得这nineNum个9全部变成0,并且前面那个数因进位而+1,因此n与m满足n=m-nineNum×9+1。现在题目给了m,我们只需要遍历nineNum的所有可能值就可以求得n,而不必对所有n进行遍历。接下来求nineNum的范围:如前所述,最小为2。至于最大值,首先它一定小于A的位数K(如果等于,也就是K个数字全部是9,+1进位成K+1位数10…0对应n=1,显然是不满足题意的),其次观察n=m-nineNum×9+1,且n至少是2,得到m-nineNum×9+1=n ≥ 2,移项得到nineNum ≤ (m-1)/9,因此nineNum的最大值为min{K-1, ⌊(m-1)/9⌋}。
3、当前已确定的数的总和不能过大也不能过小。
枚举的时候,先让nineNum从大到小枚举以唯一确定n(式子中nineNum越大n越小),再对A从首位开始枚举,这样得到的答案一定已经有序。
#include <vector>
#include <cmath>
#include <iostream>
using namespace std;
int N, K, m;
vector<int> A;
bool flag = false; // 没有答案为false
bool isPrime (int x) {
// 本来2是质数,这里为配合题意让2也不是质数
if (x <= 2) return false;
int sqr = (int)sqrt(x);
for (int i = 2; i <= sqr; i++) {
if (x % i == 0) return false;
}
return true;
}
int gcd (int a, int b) {
return b != 0 ? gcd(b, a % b) : a;
}
// 把A拆成2个部分,第二部分就是nineNum个9,剩下的就是第一部分,长为part1Num
int nineNum, n, part1Num;
// m - nineNum * 9就是第一部分各位数之和,eamin是第一部分的未确定位的数之和,index是A当前要确定的位的下标
void DFS (int remain, int index) {
// 剪枝:remain太大了
if ((part1Num - index) * 9 - 1 < remain) return;
// 边界:到第一部分的最后一个数
if (index == part1Num - 1) {
if (remain == 9) return;
if (isPrime(gcd(m, n))) {
flag = true;
A[index] = remain;
printf("%d ", n);
for (int i = 0; i < K; i++) {
// 形成的序列一定是按n, A的顺序排列
printf("%d", i <= index ? A[i] : 9);
}
printf("
");
}
return;
}
// 从0到9枚举(首位不能是0)
for (int i = index == 0 ? 1 : 0; i <= 9; i++) {
// 不能枚举比remain还大的数
if (i > remain) return;
A[index] = i;
DFS(remain - i, index + 1);
}
}
void test() {
scanf("%d", &N);
for (int i = 1; i <= N; i++) {
scanf("%d %d", &K, &m);
printf("Case %d
", i);
flag = false;
A.clear();
A.resize(K);
// 根据nineNum的值从首位开始一位一位确定数字
for (nineNum = min(K, m / 9); nineNum >= 2; nineNum--) {
n = m - nineNum * 9 + 1;
part1Num = K - nineNum;
DFS(m - nineNum * 9, 0);
}
if (!flag) {
printf("No Solution
");
}
}
}
int main () {
test();
return 0;
}
7-2 Merging Linked Lists (25 分)
时间限制:400 ms 内存限制:64 MB
Given two singly linked lists L1=a1→a2→⋯→an−1→an and L2=b1→b2→⋯→bm−1→bm. If n≥2m, you are supposed to reverse and merge the shorter one into the longer one to obtain a list like a1→a2→bm→a3→a4→bm−1⋯. For example, given one list being 6→7 and the other one 1→2→3→4→5, you must output 1→2→7→3→4→6→5.
Input Specification:
Each input file contains one test case. For each case, the first line contains the two addresses of the first nodes of L1 and L2, plus a positive N (≤105) which is the total number of nodes given. The address of a node is a 5-digit nonnegative integer, and NULL is represented by -1.
Then N lines follow, each describes a node in the format:
Address Data Next
where Address is the position of the node, Data is a positive integer no more than 105, and Next is the position of the next node. It is guaranteed that no list is empty, and the longer list is at least twice as long as the shorter one.
Output Specification:
For each case, output in order the resulting linked list. Each node occupies a line, and is printed in the same format as in the input.
Sample Input:
00100 01000 7
02233 2 34891
00100 6 00001
34891 3 10086
01000 1 02233
00033 5 -1
10086 4 00033
00001 7 -1
Sample Output:
01000 1 02233
02233 2 00001
00001 7 34891
34891 3 10086
10086 4 00100
00100 6 00033
00033 5 -1
解析:
静态链表题,按模板来就好了。先在链表的结构体里加一个index参数并初始化为一个很大的数,再对两个链表按要求进行遍历, 同时修改遍历到的结点的index,最后将所有结点按index排序。
要确定两个链表谁长谁短,所以得先遍历一遍确定长度。又由于合并的时候短链表要倒过来遍历,干脆在求长度的时候把两个链表的地址都放到vector里。输出地址记得用%05d,但是-1要单独输出。
#include <vector>
#include <algorithm>
#include <iostream>
using namespace std;
const int maxn = 100000;
typedef struct Node {
int data, address, next, index = 0x3fffffff;
} Node;
Node nodes[maxn];
bool cmp (Node a, Node b) {
return a.index < b.index;
}
vector<int> list1, list2; // 分别存储L1和L2的各节点的下标
// 遍历链表得到长度,并把各节点存进数组方便合并
int get_len(int root, vector<int> &list) {
while (root != -1) {
list.push_back(root);
root = nodes[root].next;
}
return list.size();
}
// 合并两个数组并修改index的值,其中link1是较长的,link2是较短的
void set_index (int max_len, int min_len, vector<int> &link1, vector<int> &link2) {
int a = 0;
int b = min_len - 1;
int count = 0;
for (; b >= 0; b--) {
nodes[link1[a]].index = count++; a++;
nodes[link1[a]].index = count++; a++;
nodes[link2[b]].index = count++;
}
// 处理长链表剩下的结点
for (; a < max_len; a++) {
nodes[link1[a]].index = count++;
}
}
void test() {
int l1, l2, n, t1, t2, t3;
int i;
scanf("%d %d %d", &l1, &l2, &n);
for (i = 0; i < n; i++) {
scanf("%d %d %d", &t1, &t2, &t3);
nodes[t1].address = t1;
nodes[t1].data = t2;
nodes[t1].next = t3;
}
int len1 = get_len(l1, list1), len2 = get_len(l2, list2);
if (len1 > len2) {
set_index(len1, len2, list1, list2);
} else {
set_index(len2, len1, list2, list1);
}
sort(nodes, nodes + maxn, cmp);
for (i = 0; i < len1 + len2 - 1; i++) {
printf("%05d %d %05d
", nodes[i].address, nodes[i].data, nodes[i+1].address);
}
printf("%05d %d -1", nodes[i].address, nodes[i].data);
}
int main() {
test();
return 0;
}
7-3 Postfix Expression (25 分)
时间限制:400 ms 内存限制:64 MB
Given a syntax tree (binary), you are supposed to output the corresponding postfix expression, with parentheses reflecting the precedences of the operators.
Input Specification:
Each input file contains one test case. For each case, the first line gives a positive integer N (≤ 20) which is the total number of nodes in the syntax tree. Then N lines follow, each gives the information of a node (the i-th line corresponds to the i-th node) in the format:
data left_child right_child
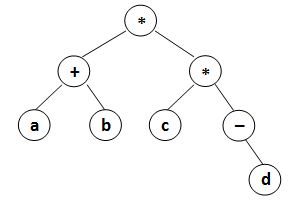
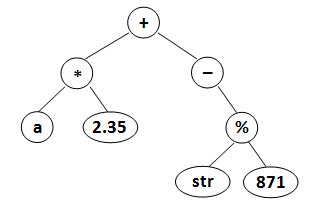
where data is a string of no more than 10 characters, left_child and right_child are the indices of this node's left and right children, respectively. The nodes are indexed from 1 to N. The NULL link is represented by −1. The figures 1 and 2 correspond to the samples 1 and 2, respectively.
 |
 |
|---|---|
| Figure 1 | Figure 2 |
Output Specification:
For each case, print in a line the postfix expression, with parentheses reflecting the precedences of the operators.There must be no space between any symbols.
Sample Input 1:
8
* 8 7
a -1 -1
* 4 1
+ 2 5
b -1 -1
d -1 -1
- -1 6
c -1 -1
Sample Output 1:
(((a)(b)+)((c)(-(d))*)*)
Sample Input 2:
8
2.35 -1 -1
* 6 1
- -1 4
% 7 8
+ 2 3
a -1 -1
str -1 -1
871 -1 -1
Sample Output 2:
(((a)(2.35)*)(-((str)(871)%))+)
解析:
先建静态二叉树,再后序遍历。进入DFS加左括号,退出本次DFS加右括号。需要判断左子树是否存在,如果存在,运算符要放到后面;如果不存在,运算符放到前面。根的确定方法:维护一个哈希表,凡是子节点就将对应项置1,最后扫一遍哈希表,值为0的就是根。
注意,测试点4把+当做正号使用,不能只特判-。
#include <string>
#include <iostream>
using namespace std;
typedef struct Node {
string data;
int l, r;
} Node;
Node nodes[22];
int isRoot[22];
void post (int index) {
if (index == -1) return;
printf("(");
if (nodes[index].l == -1) {
cout << nodes[index].data;
post(nodes[index].r);
} else {
post(nodes[index].l);
post(nodes[index].r);
cout << nodes[index].data;
}
printf(")");
}
void test() {
int N, left, right;
int i, root;
string s;
scanf("%d", &N);
for (i = 1; i <= N; i++) {
cin >> s >> left >> right;
nodes[i].data = s;
nodes[i].l = left; isRoot[left] = 1;
nodes[i].r = right; isRoot[right] = 1;
}
for (i = 1; i <= N; i++) if (isRoot[i] == 0) break;
root = i;
post(root);
}
int main() {
test();
return 0;
}
7-4 Dijkstra Sequence (30 分)
时间限制:1500 ms 内存限制:64 MB
Dijkstra's algorithm is one of the very famous greedy algorithms. It is used for solving the single source shortest path problem which gives the shortest paths from one particular source vertex to all the other vertices of the given graph. It was conceived by computer scientist Edsger W. Dijkstra in 1956 and published three years later.
In this algorithm, a set contains vertices included in shortest path tree is maintained. During each step, we find one vertex which is not yet included and has a minimum distance from the source, and collect it into the set. Hence step by step an ordered sequence of vertices, let's call it Dijkstra sequence, is generated by Dijkstra's algorithm.
On the other hand, for a given graph, there could be more than one Dijkstra sequence. For example, both { 5, 1, 3, 4, 2 } and { 5, 3, 1, 2, 4 } are Dijkstra sequences for the graph, where 5 is the source. Your job is to check whether a given sequence is Dijkstra sequence or not.
Input Specification:
Each input file contains one test case. For each case, the first line contains two positive integers Nv (≤103) and Ne (≤105), which are the total numbers of vertices and edges, respectively. Hence the vertices are numbered from 1 to Nv.
Then Ne lines follow, each describes an edge by giving the indices of the vertices at the two ends, followed by a positive integer weight (≤100) of the edge. It is guaranteed that the given graph is connected.
Finally the number of queries, K, is given as a positive integer no larger than 100, followed by K lines of sequences, each contains a permutationof the Nv vertices. It is assumed that the first vertex is the source for each sequence.
All the inputs in a line are separated by a space.
Output Specification:
For each of the K sequences, print in a line Yes if it is a Dijkstra sequence, or No if not.
Sample Input:
5 7
1 2 2
1 5 1
2 3 1
2 4 1
2 5 2
3 5 1
3 4 1
4
5 1 3 4 2
5 3 1 2 4
2 3 4 5 1
3 2 1 5 4
Sample Output:
Yes
Yes
Yes
No
解析:
要判断迪杰斯特拉序列,也就是每一轮循环中凡是路径最小的点都可以选,而不是按照模板所有路径最小的点中选序号最小的。为此用unordered_set存储所有路径最小的点,每次松弛前检查下序列对应点是否在里面。
#include <unordered_set>
#include <string>
#include <vector>
using namespace std;
const int maxn = 1002, INF = 0x3fffffff;
typedef struct Node {
int next, dist;
} Node;
vector<Node> G[maxn];
int dist[maxn], visited[maxn];
int nv, ne, K;
vector<int> input;
bool dij () {
int i, j, min_dist, cur_index;
for (i = 1; i <= nv; i++) { dist[i] = INF; visited[i] = 0; }
dist[input[0]] = 0;
for (i = 0; i < nv; i++) {
min_dist = INF - 1;
unordered_set<int> temp;
// 先找到最小值
for (j = 1; j <= nv; j++) {
if (!visited[j] && min_dist > dist[j]) {
min_dist = dist[j];
}
}
// 再把所有最小路径加入unordered_set
for (j = 1; j <= nv; j++) {
if (!visited[j] && min_dist == dist[j]) {
temp.insert(j);
}
}
if (temp.count(input[i]) == 0) return false;
// 松弛
cur_index = input[i];
visited[cur_index] = 1;
for (auto &node : G[cur_index]) {
if (!visited[node.next] && dist[cur_index] + node.dist < dist[node.next]) {
dist[node.next] = dist[cur_index] + node.dist;
}
}
}
return true;
}
void test() {
int i, j, t1, t2, t3;
scanf("%d %d", &nv, &ne);
input.resize(nv);
for (i = 0; i < ne; i++) {
scanf("%d %d %d", &t1, &t2, &t3);
Node node; node.next = t2, node.dist = t3;
Node node2; node2.next = t1, node2.dist = t3;
G[t1].push_back(node); G[t2].push_back(node2);
}
scanf("%d", &K);
for (i = 0; i < K; i++) {
for (j = 0; j < nv; j++) scanf("%d", &input[j]);
printf("%s
", dij() ? "Yes" : "No");
}
}
int main() {
test();
return 0;
}
总结
| 编号 | 标题 | 分数 | 类型 |
|---|---|---|---|
| 7-1 | Forever | 20 | 5.2 最大公约数+5.4 素数+8.1 DFS |
| 7-2 | Merging Linked Lists | 25 | 7.3 链表处理 |
| 7-3 | Postfix Expression | 25 | 9.2 二叉树的遍历 |
| 7-4 | Dijkstra Sequence | 30 | 10.4 最短路径 |
究极缝合怪他来了,带着第一题的下马威来了!第一题最难没有问题吧,这题恰似一记当头棒喝,打得所有人(大佬除外)七荤八素,时间打没了,心态也打没了。第二题是套路题的老熟人,稍微变通一下就好。第三题也是套路题,套了个应用的壳,根据应用进行变通。第四题看懂了题就知道,只需把迪杰斯特拉算法的模板稍作改动。所以就是一道难题+三道套路题,第一题:我不是针对谁,我是说在座各题,都是垃圾……