以下是选择复制源节点的代码
代码总结:
A=datanode上要复制block的Queue size与 target datanode没被选出之前待处理复制工作数之和。
1. 优先选择退役中的节点,因为其无写入请求,负载低。
2. 不会选择退役完成的节点。
3. 如果A未达到复制限制(<maxReplicationStreams,conf配置名为dfs.namenode.replication.max-streams),在nodelist中随机选择节点
4. 如果A达到复制限制(>=maxReplicationStreams),除非blockQueue是最高优先级的,会随机选一台节点,否者会pass掉(代码中为continue)。
5. 如果A达到复制硬限制(>=replicationStreamsHardLimit,conf配置为dfs.namenode.replication.max-streams-hard-limit),无论满足什么条件都会pass。
/**
* Parse the data-nodes the block belongs to and choose one,
* which will be the replication source.
*
* We prefer nodes that are in DECOMMISSION_INPROGRESS state to other nodes
* since the former do not have write traffic and hence are less busy.
* We do not use already decommissioned nodes as a source.
* Otherwise we choose a random node among those that did not reach their
* replication limits. However, if the replication is of the highest priority
* and all nodes have reached their replication limits, we will choose a
* random node despite the replication limit.
*
* In addition form a list of all nodes containing the block
* and calculate its replication numbers.
解析块所属的数据节点并选择一个,这将是复制源。
我们更偏向处于DECOMMISSION_INPROGRESS(退役中)状态的节点到其他节点,因为前者没有写入流量,因此不太忙。
我们不使用已经退役的节点作为源。
除此之外,我们会在未达到复制限制的节点中选择一个随机节点(<maxReplicationStreams)。
但是,如果复制到达最高优先级并且所有节点都已达到其复制限制(>=maxReplicationStreams,当然如果>=replicationStreamsHardLimit最算是最高优先级也是不行的),我们将随机选择一个节点,尽管有复制限制。
另外,形成包含块的所有节点的列表并计算其复制数。
*
* @param block Block for which a replication source is needed
* @param containingNodes List to be populated with nodes found to contain the
* given block
* @param nodesContainingLiveReplicas List to be populated with nodes found to
* contain live replicas of the given block
* @param numReplicas NumberReplicas instance to be initialized with the
* counts of live, corrupt, excess, and
* decommissioned replicas of the given
* block.
* @param priority integer representing replication priority of the given
* block
* @return the DatanodeDescriptor of the chosen node from which to replicate
* the given block
*/
@VisibleForTesting
DatanodeDescriptor chooseSourceDatanode(Block block,
List<DatanodeDescriptor> containingNodes,
List<DatanodeStorageInfo> nodesContainingLiveReplicas,
NumberReplicas numReplicas,
int priority) {
containingNodes.clear();
nodesContainingLiveReplicas.clear();
DatanodeDescriptor srcNode = null;
int live = 0;
int decommissioned = 0;
int corrupt = 0;
int excess = 0;
Collection<DatanodeDescriptor> nodesCorrupt = corruptReplicas.getNodes(block);
for(DatanodeStorageInfo storage : blocksMap.getStorages(block)) {
final DatanodeDescriptor node = storage.getDatanodeDescriptor();
LightWeightLinkedSet<Block> excessBlocks =
excessReplicateMap.get(node.getDatanodeUuid());
int countableReplica = storage.getState() == State.NORMAL ? 1 : 0;
if ((nodesCorrupt != null) && (nodesCorrupt.contains(node)))
corrupt += countableReplica;
else if (node.isDecommissionInProgress() || node.isDecommissioned())
decommissioned += countableReplica;
else if (excessBlocks != null && excessBlocks.contains(block)) {
excess += countableReplica;
} else {
nodesContainingLiveReplicas.add(storage);
live += countableReplica;
}
containingNodes.add(node);
// Check if this replica is corrupt
// If so, do not select the node as src node
if ((nodesCorrupt != null) && nodesCorrupt.contains(node))
continue;
if(priority != UnderReplicatedBlocks.QUEUE_HIGHEST_PRIORITY
&& node.getNumberOfBlocksToBeReplicated() >= maxReplicationStreams)
{
continue; // already reached replication limit
}
if (node.getNumberOfBlocksToBeReplicated() >= replicationStreamsHardLimit)
{
continue;
}
// the block must not be scheduled for removal on srcNode
if(excessBlocks != null && excessBlocks.contains(block))
continue;
// never use already decommissioned nodes
if(node.isDecommissioned())
continue;
// we prefer nodes that are in DECOMMISSION_INPROGRESS state
// 如果你是退役中的节点会被优先选择并把你赋值给srcNode,后期的判断就基本跳过DFSUtil.getRandom().nextBoolean(),因为在 if(srcNode.isDecommissionInProgress()) continue;直接continue了。
if(node.isDecommissionInProgress() || srcNode == null) {
srcNode = node;
continue;
}
if(srcNode.isDecommissionInProgress())
continue;
// switch to a different node randomly
// this to prevent from deterministically selecting the same node even
// if the node failed to replicate the block on previous iterations
// 这里主要是防止一直选相同节点,如果所遍历的node是退役中节点,不会走这个方法(在上层就continue了),如果某个待复制的block(正常块,不存在损坏超额等问题)所在的三个节点都是普通正常节点,那具体选择哪个node就完全随机了,虽然是个伪随机。
if(DFSUtil.getRandom().nextBoolean())
srcNode = node;
}
if(numReplicas != null)
numReplicas.initialize(live, decommissioned, corrupt, excess, 0);
return srcNode;
}
加快退役的三个参数
默认数分别为2,4,2 修改为 10,20,5 后
测试2w+个块(15G左右)迁移,后者比前者(默认参数)快4-5倍左右
但是如果线上不建议开过大,会严重影响线上正常服务
<!-- speed up decommission -->
<property>
<name>dfs.namenode.replication.max-streams</name>
<value>10</value>
</property>
<property>
<name>dfs.namenode.replication.max-streams-hard-limit</name>
<value>20</value>
</property>
<property>
<name>dfs.namenode.replication.work.multiplier.per.iteration</name>
<value>5</value>
</property>
前两个参数已经介绍完了,下面来介绍下第三个参数的用途
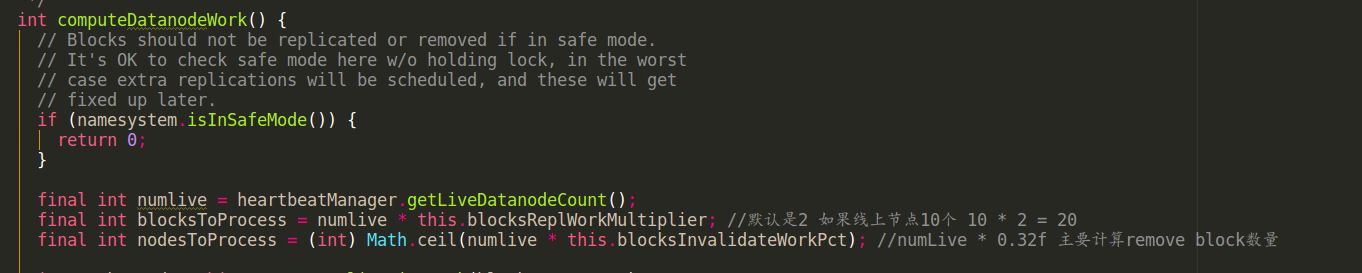
dfs.namenode.replication.work.multiplier.per.iteration 参数决定了可以从很多under replication blocks中选出多少个block 准备进行复制。
可以选出的block数与集群live 的datadnode 成正比。
int blocksToProcess = numlive * this.blocksReplWorkMultiplier(就是这个参数dfs.namenode.replication.work.multiplier.per.iteration),如果线上有10个in service datanode 那默认就可以选出 10 * 2 = 20个block 准备进行replicate
源码如图:
总结一下这三个参数:
这三个参数其实就是个限流参数
第三个参数相当于入口限流参数,决定了可以从under replication blocks 的集合中选出多少个blocks 加到复制队列中准备进行复制。
前两个参数相当于出口限流,他们是在遍历复制队列中的blocks时,决定是否给当前block一个srcNode(也可能返回null)。如果满足限流条件,srcNode=当前node;如果不满足就contiune,直到找到满足的node,如果所有node都不满足就返回null(如果返回null 该block是不会relicate的);
问题:
1. 队列中的block 最高优先级指什么,是live的副本数远小于默认的副本数吗?
2. "ask: srcNode" 日志中的srcNode 节点不只是退役中的节点,为什么?
问题1解答:
block所在队列的优先级有五个,源码如下:
/** The total number of queues : {@value} */
// 共五个等级
static final int LEVEL = 5;
/** The queue with the highest priority: {@value} */
//最高优先级queue:这些blocks会被优先复制。只有一个副本的块或者这些块有0个live副本,1个副本在正在退役的节点.如果这些blocks所在的磁盘或者服务器出现问题,这些blocks有丢失风险。
static final int QUEUE_HIGHEST_PRIORITY = 0;
/** The queue for blocks that are way below their expected value : {@value} */
//第二优先级: 这些blocks的副本远低于他们所期望的值。目前意味着实际的比例时少于1/3,虽然这些blocks可能并没有风险,但是他们清楚地考虑到blocks重要性。
static final int QUEUE_VERY_UNDER_REPLICATED = 1;
/** The queue for "normally" under-replicated blocks: {@value} */
//第三优先级:这些blocks 也低于所期望值(同样处于复制状态的块),以及 实际:预期的比例 足够好(不少与1/3),以至于它们不需要进入队列
static final int QUEUE_UNDER_REPLICATED = 2;
/** The queue for blocks that have the right number of replicas,
* but which the block manager felt were badly distributed: {@value}
*/
//第四优先级:一个block满足要求的最小副本数,但是由于分布不充分,如果一个机架当机可能导致所有的副本丢失/下线
static final int QUEUE_REPLICAS_BADLY_DISTRIBUTED = 3;
/** The queue for corrupt blocks: {@value} */
//第五优先级:这适用于已损坏的块,并且当前有可用的非损坏副本(当前)。这里的策略是保持这些损坏的块被复制,但是给出不是更高优先级的块。
static final int QUEUE_WITH_CORRUPT_BLOCKS = 4;
问题2的解答:( xx.x.x.34为退役中节点)
1.退役节点的上要replica 的block非常多,有些block还没来得及replica 就已经过期了,所以不能把退役中的节点作为srcNode
2.由于前期以退役节点为srcNode较多,已经有达到了dfs.namenode.replication.max-streams 或 dfs.namenode.replication.max-streams-hard-limit 的上限,所以只能选其他节点作为srcNode
这是复制block日志可以说明问题2, xx.x.x.34 达到上限10(也可能是20)后,就会选择其他节点作为srcNode了(共70个)。
2018-09-25 11:38:01,439 INFO BlockStateChange: BLOCK* ask xx.x.x.34:50010 to replicate blk_1298821823_225481125 to datanode(s) xx.x.x.28:50010
2018-09-25 11:38:01,439 INFO BlockStateChange: BLOCK* ask xx.x.x.34:50010 to replicate blk_1298821896_225481198 to datanode(s) xx.x.x.36:50010
2018-09-25 11:38:01,439 INFO BlockStateChange: BLOCK* ask xx.x.x.34:50010 to replicate blk_1298821588_225480890 to datanode(s) xx.x.x.45:50010
2018-09-25 11:38:01,439 INFO BlockStateChange: BLOCK* ask xx.x.x.34:50010 to replicate blk_1298821581_225480883 to datanode(s) xx.x.x.30:50010
2018-09-25 11:38:01,439 INFO BlockStateChange: BLOCK* ask xx.x.x.34:50010 to replicate blk_1282045832_208688251 to datanode(s) xx.x.x.30:50010
2018-09-25 11:38:01,439 INFO BlockStateChange: BLOCK* ask xx.x.x.34:50010 to replicate blk_1282045861_208688280 to datanode(s) xx.x.x.44:50010
2018-09-25 11:38:01,439 INFO BlockStateChange: BLOCK* ask xx.x.x.34:50010 to replicate blk_1282045812_208688231 to datanode(s) xx.x.x.31:50010
2018-09-25 11:38:01,439 INFO BlockStateChange: BLOCK* ask xx.x.x.34:50010 to replicate blk_1282045643_208688062 to datanode(s) xx.x.x.11:50010
2018-09-25 11:38:01,439 INFO BlockStateChange: BLOCK* ask xx.x.x.34:50010 to replicate blk_1282045478_208687897 to datanode(s) xx.x.x.43:50010
2018-09-25 11:38:01,439 INFO BlockStateChange: BLOCK* ask xx.x.x.34:50010 to replicate blk_1282045530_208687949 to datanode(s) xx.x.x.22:50010
2018-09-25 11:38:01,439 INFO BlockStateChange: BLOCK* ask xx.x.x.41:50010 to replicate blk_1206547507_133106764 to datanode(s) xx.x.x.42:50010
2018-09-25 11:38:01,439 INFO BlockStateChange: BLOCK* ask xx.x.x.41:50010 to replicate blk_1206548077_133107334 to datanode(s) xx.x.x.28:50010
2018-09-25 11:38:01,439 INFO BlockStateChange: BLOCK* ask xx.x.x.11:50010 to replicate blk_1206548222_133107479 to datanode(s) xx.x.x.19:50010
2018-09-25 11:38:01,439 INFO BlockStateChange: BLOCK* ask xx.x.x.11:50010 to replicate blk_1189768077_116313696 to datanode(s) xx.x.x.45:50010
......
解释下图字段的含义:
Node :退役中的节点hostname
Last contact:节点心跳,这里为空,在页面上面会展示心跳信息
Under replicated blocks:当前block的副本 < 所设置的副本(默认就是小于3) 数量
Blocks with no live replicas:没有live 的副本,存在的副本可能都在退役中的节点上
Under Replicated Blocks In files under construction: 当前正在复制中的block个数

可以通过 这个命令看内存的配置key-value
hdfs getconf -confkey xxx