1、混淆矩阵
一般情况下,分类器的好坏是通过错误率来衡量的。错误率指的是在测试数据中错误分类的样本所占比例。然而,这样进行度量掩盖了样例如何被分错的原因。
三类问题混淆矩阵示例:

当该矩阵中非对角元素均为0,那么就会得到完美的分类器。
二分类混淆矩阵:

在分类中,当某个类别的重要性高于其他类别时,可以利用上述定义来得到比错误率更好的指标:
l 正确率(Precision):TP/(TP+FP),表示在所有预测为正例中真正例所占的比例。
l 真阳率(True Positive Rate,TPR),灵敏度(Sensitivity),召回率(Recall):TP/(TP+FN),表示在所有真正例中预测为正例所占的比例。
l 真阴率(True Negative Rate,TNR),特异度(Specificity):TN/(TN+FP)
l 假阴率(False Negatice Rate,FNR),漏诊率( = 1 – 灵敏度):FN/(FN+TP)
l 假阳率(False Positice Rate,FPR),误诊率( = 1 – 特异度):FP/(FP+TN)
l 阳性似然比(Positive Likelihood Ratio (LR+)):TPR/(1-TNR)=TPR/FPR
l 阴性似然比(Negative Likelihood Ratio (LR−)):(1-TPR)/TNR=FNR/TNR
l Youden 指数(Youden index):Youden index=TPR-FPR
对于得到一个高正确率或召回率的分类器是可行的,但是很难使得两个同时成立。
2、ROC曲线、AUC
ROC曲线即receiver operating characteristic curve,表示接收者操作特征曲线。是反映敏感性和特异性连续变量的综合指标。
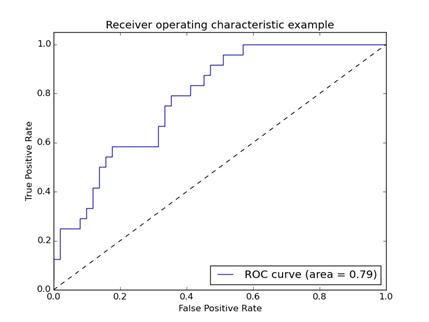
横坐标轴:伪正例的比例(假阳率=FP/(FP+TN))
纵坐标轴:真正例的比例(真阳率=TP/(TP+FN))
实线(ROC曲线):阈值变化时假阳率和真阳率的变化情况。
虚线:随机猜测的结果曲线
左下角:所有样例都判为反例
右上角:所有样例都判为正例
ROC既可以用来比较分类器,还可以基于成本效益(cost versus benefit)分析来做出决策。
在理想情况下,最佳的分类器应该尽可能地处于左上角,即意味着在假阳率很低的同时获得很高的真阳率。
对不同的ROC曲线进行比较的一个指标为曲线下面积(Area Unser the Curve,AUC)。AUC给出的是分类器的平均性能值。一个完美分类器的AUC为1.0,随机猜测的AUC为0.5。
绘制ROC曲线
①从分类器得到预测值(值越大属于1类的可能性更大),对预测值进行升序排序,并得到每个样本对应的实际类别,得到正例和反例的个数,以及步长:
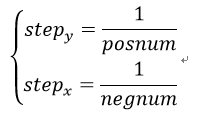
设置ROC初始绘制点为(1.0,1.0)。
②遍历所有预测值,从排名最低的样例开始,如果当前预测值对应的样本的实际类别标签为反例,则比当前预测值低的样本都视作反例,比当前预测值高的样本都视为正例。即每得到一个标签为1的类,沿y轴下降一个步长,降低真阳率,否则x轴上倒退一个步长,降低假阴率。