一、读取文件
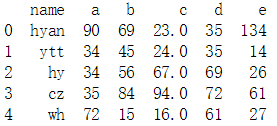
import pandas as pd data = pd.read_csv("F:\ml\机器学习\01\score.csv") #一般读取的是csv文件,就是以逗号形式分隔开的文件 print(data) #显示data的值 """name a b c d e 0 hyan 90 69 23.0 35 134 1 ytt 34 45 24.0 35 14 2 hy 34 56 67.0 69 26 3 cz 35 84 94.0 72 61 4 wh 72 15 16.0 61 27 5 hj 62 61 NaN 28 38 """ print(data.dtypes) #显示data里面参数的类型 """ name object a int64 b int64 c float64 d int64 e int64 dtype: object""" print(type(data)) #显示data的类型------<class 'pandas.core.frame.DataFrame'> print(help(pd.read_csv)) #寻求帮助
data.columns #显示每类的类名------Index(['name', 'a', 'b', 'c', 'd', 'e'], dtype='object') data.shape #显示维度------(6, 6)
data.head(3) #显示前三行的数据,默认前5行
data.tail(3) #显示后3行的数据,默认后5行
二、索引与计算
import pandas as pd data = pd.read_csv("F:\ml\机器学习\01\score.csv") #一般读取的是csv文件,就是以逗号形式分隔开的文件 data.loc[0:2] #读取行,通过loc形式读取,比如data.loc[0]读取第0行,也可以通过切片,如这样就可以读取前三行,注意的是包括索引2所在的行
data[["name", "a"]] #读列,默认第一行的为列名,如果单独读取某个列,比如data["name"],如果读取好几个列的话,放进数组的里读取。
#读取列名中的含a的列-----一般寻找的特殊列的过程 col_names = data.columns.tolist() #将所有的列名放进列表中 print(col_names) #------['name', 'a', 'b', 'c', 'd', 'e'] select_col = [] for name in col_names: if 'a' in name: select_col.append(name) print(data[select_col])

#新增列,先通过运算得到的列 f = data['d'] + data['e'] print(f)
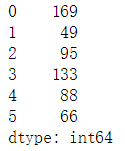
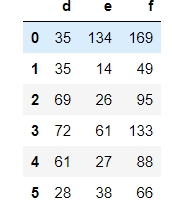
#再将列填进去 data['f'] = f print(data.shape) #------(6, 7) data[['d', 'e', 'f']]
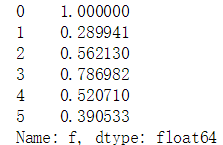
#将f列进行归一化操作 data['f'].min() #取f列的最小值------49 data['f'].max() #取f列的最大值------169 f_normalized = data['f'] / data['f'].max() print(f_normalized)
三、数据预处理实例
data.sort_values('f', inplace = True, ascending = True) #排序,inplace=True表示会改变原来的数据,ascending = True表示升序,默认就是升序。NaN表示之前没有数据,用NaN代替 print(data)
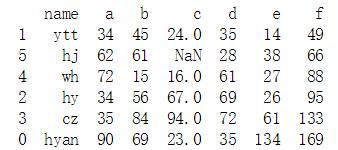
#寻找c列的NaN的个数,也就是缺失值的个数。 c = data['c'] c_is_null = pd.isnull(c) #判断c列的值,NaN为True,否则为False print(c_is_null)

nan = c[c_is_null] #以c_is_null为索引,只返回True的值 print(nan)
![]()
count = len(nan) #显示nan的个数 print(count) #------1
#去掉NaN求均值的两个方法 #方法一 c_isnot_null = data['c'][c_is_null == False] #去掉NaN所得到的列 mean_c = sum(c_isnot_null) / len(c_isnot_null) print(mean_c) #------44.8 #调用自己的函数 mean_c_1 = data['c'].mean() print(mean_c_1) #------44.8
#统计以a为等级的对应e的平均值 e_mean = data.pivot_table(index = 'a', values = 'e', aggfunc = np.mean) print(e_mean)

#统计以a为等级对应d、e的总和 sum_d_e = data.pivot_table(index = 'a', values = ['d', 'e'], aggfunc = np.sum) #如果不写参数aggfunc,默认为平均值 print(sum_d_e)
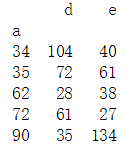
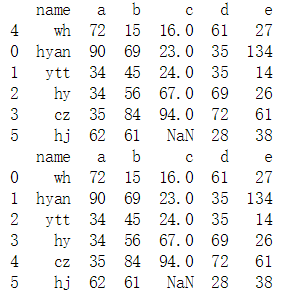
#去掉NaN所在的行或者列 new_data = data.dropna(axis = 1) #去掉含NaN所在的列 print(new_data)

new_data_1 = data.dropna(axis = 0, subset = ['c', 'd']) #去掉NaN所在的行 print(new_data_1)
#确定寻找某个值 b_2 = data.loc[2, 'b'] print(b_2) #------56
import pandas as pd data = pd.read_csv("F:\ml\机器学习\01\score.csv") #一般读取的是csv文件,就是以逗号形式分隔开的文件 data.sort_values('c', inplace = True, ascending = True) print(data) #排序后行号发生的改变,这时候重新从头设定的话 new_data = data.reset_index(drop = True) #drop = True表示原来的索引不要了,重新从头开始设定 print(new_data)
四、自定义函数
import pandas as pd data = pd.read_csv("F:\ml\机器学习\01\score.csv") #一般读取的是csv文件,就是以逗号形式分隔开的文件 #自定义函数,取data的DataFrame的第4行数据 def a_values(data): return data.loc[4] a_value = data.apply(a_values) #调用自定义函数 print(a_value)
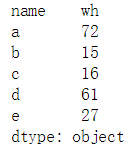
五、Series结构
import pandas as pd import numpy as np from pandas import Series #取出DataFrame中的某一行或者某一列都是Series类型 data = pd.read_csv("F:\ml\机器学习\01\score.csv") #一般读取的是csv文件,就是以逗号形式分隔开的文件 d_data = data['d'] print(type(d_data)) #------<class 'pandas.core.series.Series'> d = d_data.values #将Series类型转化为ndarry类型 print(d) #------[35 35 69 72 61 28] print(type(d))#------<class 'numpy.ndarray'> #对于两个ndarray类型,只要维度一样,就可以将其中的一个ndarray作为索引形成Series类型。 num = np.array([1, 2, 3, 4, 5, 6]) name = np.array(['a', 'b', 'c', 'd', 'e', 'f']) name_num = Series(num, index = name) print(name_num)
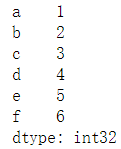
#也可以直接创建 Series([1, 2, 3, 4])
0 1 1 2 2 3 3 4 dtype: int64
Series({'a':1, 'b':2, 'c':3})
a 1 b 2 c 3 dtype: int64
Series([1, 2, 3, 4, 5], index = ['a', 'b', 'c', 'd', 'e'])
a 1 b 2 c 3 d 4 e 5 dtype: int64
v = Series([1, 2, 3, 4, 5], index = ['a', 'b', 'c', 'd', 'e']) print(v.cumsum()) #cumsum()是累计求和
a 1 b 3 c 6 d 10 e 15 dtype: int64