
【摘要】 Modelarts技术及相关产业已成为未来AI与大数据重点发展行业模式之一,为了促进人工智能领域科学技术快速发展,modelarts现状及生态前景成为研究热点。笔者首先总结modelarts发展的现状,并阐述modelarts端边云协同部署对无感识别技术的支撑与迭代。其次,对Modelarts支撑的无感支付“生态”应用展望,期待能为人工智能领域发展提供帮助。

1 modelarts现状和发展的特点
1.1 modelarts的现状和发展的概述
ModelArts 是华为全栈全场景 AI 解决方案面向用户和开发者的门户,作为一站式 AI 开发平台,提供海量数据预处理及半自动化标注、大规模分布式训练、自动化模型生成,及端 - 边 - 云模型按需部署能力,帮助用户快速创建和部署模型,管理全周期 AI 工作流。
1.2 modelarts发展点
1.2.1数据处理
AI 开发过程中经常需要处理海量数据,数据准备与标注往往耗费整体开发一半以上时间。ModelArts 数据处理框架包含数据采集、数据筛选、数据标注、数据集版本管理功能,支持自动化和半自动化的数据筛选功能,自动化的数据与标注及辅助自动化标注工具。AI 开发者可基于框架实现数据标注全流程处理.
1.2.2 算法开发
深度学习需要大规模的加速计算,往往需要大规模 GPU 集群进行分布式加速。而现有的开源框架需要算法开发者写大量的代码实现在不同硬件上的分布式训练,而且不同框架的加速代码都不相同。为了解决这些痛点,需要一种轻型的分布式框架或者 SDK,构建于 TensorFlow、PyTorch、MXNet 等深度学习引擎之上,使得这些计算引擎分布式性能更高,同时易用性更好,ModelArts 的 MoXing 可以很好地解决这些痛点.
简化调参,集成多种调参技巧包,如数据增强的调参策略,可简化 AI 算法工程师的模型调优痛苦。
简化分布式,支持将单机代码自动分布式,使算法工程师不需要学习分布式相关的知识,在自动化分布式的同时,也优化了分布式的性能,自动化和高性能是相辅相成的。
1.2.3 模型训练
模型训练中除了数据和算法外,开发者花了大量时间在模型参数设计上。模型训练的参数直接影响模型的精度以及模型收敛时间,参数的选择极大依赖于开发者的经验,参数选择不当会导致模型精度无法达到预期结果,或者模型训练时间大大增加。
ModelArts 高性能分布式训练优化点:
第一,自动混合精度训练(充分发挥硬件计算能力)
第二,动态超参调整技术(动态 batch size、image size、momentum 等)
第三,模型梯度的自动融合、拆分
第四,基于 BP bubble 自适应的计算 - 通信算子调度优化
第五,分布式高性能通信库(nstack、HCCL)
第六,分布式数据 - 模型混合并行
第七,训练数据压缩、多级缓存
1.2.4 模型部署
通常 AI 模型部署和规模化落地非常复杂。如智慧交通,在获得训练好的模型后,需要部署到云、边、端多种场景。端边云协同 AI 应用开发和部署服务。
ModelArts 平台端云协同关键技术点包括:
第一,针对不同类型的端侧平台,支持模型拆分、任务拆分,从而让端云协同起来。
第二,利用模型管理能力,进行版本管理、模型搜索、模型复用。
第三,支持对第三方平台的管理,针对模型安全进行权限认证,计费管理。
ModelArts 端云结合方案,在图片清晰度检测、智慧小区人脸识别等实际场景进行了应用。如在交警场景就使用 ARM 架构边缘云进行信控和流量检测,优化了交通灯、路灯等市政设施的控制,如对灯光亮度调整达到了 40% 节能的水平。
1.2.5 AI市场
AI 市场是在 ModelArts 的基础上构建的开发者生态社区,提供模型、API 的交易,数据、竞赛案例等内容的共享功能,为高校科研机构、AI 应用开发商、解决方案集成商、企业及个人开发者等群体,提供安全、开放的共享及交易环境,加速 AI 产品的开发与落地,保障 AI 开发生态链上各参与方高效地实现各自的商业价值。
1.2.6自动学习
ModelArts 通过机器学习的方式帮助不具备算法开发能力的业务开发者实现算法的开发,基于迁移学习、自动神经网络架构搜索实现模型自动生成,通过算法实现模型训练的参数自动化选择和模型自动调优的自动学习功能,让零 AI 基础的业务开发者可快速完成模型的训练和部署。依据开发者提供的标注数据及选择的场景,无需任何代码开发,自动生成满足用户精度要求的模型。可支持图片分类、物体检测、预测分析、声音分类场景。可根据最终部署环境和开发者需求的推理速度,自动调优并生成满足要求的模型。
华为与世界雨林保护组织的合作项目里,采用了 ModelArts 自动学习声音分类功能,实现对电锯和卡车噪音的精准识别,结果比很多博士手工调参精度还要高。
1.2.7 AI开发流程管理
AI 开发过程中,如果开发者手动管理 AI 开发数据集、模型、训练参数,当需要大量的调优迭代时,实验过程难以追踪,结果难以复制。现有的代码管理产品不适合管理 AI 资产如图片、视频类的数据集,二进制的模型,部署后的 Web Services 等。为了解决这些问题,ModelArts 提供 AI 开发全生命周期管理,从原始数据、标注数据、训练作业、算法、模型、推理服务等,提供全流程可视化管理服务。

2 modelarts端边云协同部署对无感识别技术的支撑与迭代
从理论研究来谈论。目前,对无感支付没有权威、标准的概念界定。在建研无感支付课题组认为,无感支付是用某种独一无二的特征标的物绑定银行账户或支付工具,通过一系列技术加以识别该特征标的物,从而完成支付。无感支付体现三个特征:一是支付身份认证方法不再是ID卡,密码等传统方式。二是支付不再作为一个独立的环节出现,没有专门的支付动作。三是支付速度高速化,目前普遍认为不超过2秒。根据无感支付的概念界定,无感支付技术是以识别技术为基础。目前识别技术主要可划分为三类,即光学识别、声学识别、各类波的识别,这些技术为无感支付提供了基础的理论条件。
从技术层面实施来说。各类无感识别应用技术的支撑即精度要无穷接近于1。基于光学、声学、各类波的识别端(自带ascend、MindSpore)+无感边缘服务+Modelarts平台的全栈支撑综上所述一一对应。端边云的协同部署将非难实例高效解决在端,特殊定制化实例化解在边缘服务,难题型实例利用光纤、5G、6G网络连接Modelarts交给atelas900集群解决,让精度和速度完美匹配。
从代码开发层面来说。ModelArts是一个通用AI开发平台,具体开发出什么东西,主要取决于开发人员的技术能力和开发方向。基于ModelArts上开发无感支付的业务模型,对能力和方向的考验同样是广袤的。
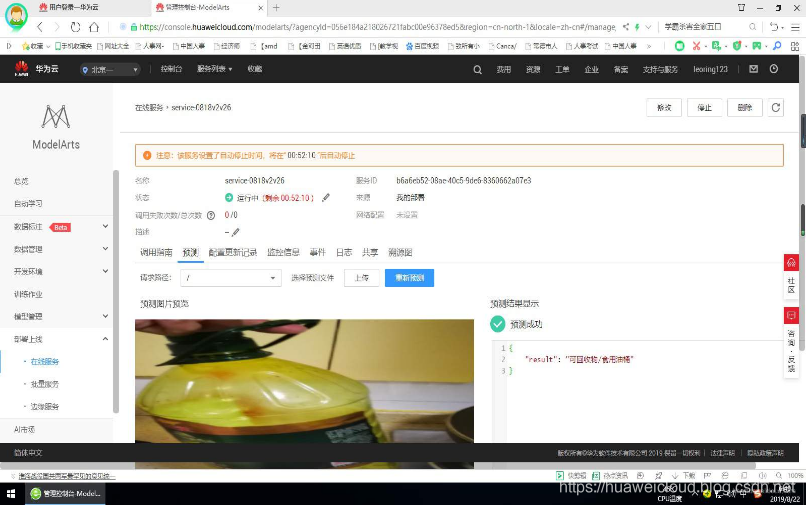
2.1 劳动者港湾人工智能垃圾分类的部署
在华为云上海2019HCC全联接大会上,见证了基于modelarts的端边云协同部署,启发式开发了端云协同系统即劳动者港湾人工智能垃圾分类系统。modelarts提供云服务加载模型和提供算力,安卓系统为端并可部署于全国劳动者港湾。
2.1.1创意简介
劳动者港湾垃圾分类AI,目的在于构建基于深度学习技术的图像分类模型,实现垃圾图片类别的精准识别,参考深圳垃圾分类标准,按可回收物、厨余垃圾、有害垃圾和其他垃圾四项分类。
2.1.2痛点分析(背景及需要解决的问题)
如今,垃圾分类已成为社会热点话题。其实在2019年4月26日,我国住房和城乡建设部等部门就发布了《关于在全国地级及以上城市全面开展生活垃圾分类工作的通知》,决定自2019年起在全国地级及以上城市全面启动生活垃圾分类工作。到2020年底,46个重点城市基本建成生活垃圾分类处理系统。
随着人工智能深度学习在无感识别技术领域的应用和发展,让我们看到了利用AI来自动进行垃圾分类的可能,通过在建研无感支付课题组的研究学习,摄像头拍摄垃圾图片,检测图片中垃圾的类别,从而可以让机器自动进行垃圾分拣,极大地提高垃圾分拣效率。
2.1.3具体解决方案
在劳动者港湾部署一台普通Android手机作为人工智能垃圾分类系统的端,利用WIFI或5G、4G网络连接华为云modelarts服务器提供算力支撑。端云协同的部署利于单点服务大众,更利于点线面的铺开。打破了国外谷歌公司端云协同人工智能领域的垄断。可有效解决人民对垃圾分类的疑惑与全民垃圾分类的普及问题。当下云端和安卓端已推出第一版,人工智能模型在华为的2019HCC大会中获得了荣誉证书。
2.1.4创意亮点
本创意的创新点就是助力和解决垃圾分类的难点,让人民的生活少花精力在这个局面,助力人民生活更加美好。本创意应用了人工智能技术,采取端、云协同的方式实现垃圾分类。即可单一部署,也可全局全行部署。全行推行,将对社会、环保、民生等多个方面带来文明与进步。其精准分类后的垃圾,可变现、可回收、可节约社会资源、可协同社会与生态的良性发展,实现人民对美好生活的向往。
2.1.5运用到的技术与知识点
模型采用Modelarts平台,使用的TensorFlow1.6框架,分别尝试了SENet、resnet50、resnet152、SEResNet
通过baseline比对调优后最终采用残差50网络计算,9轮训练达到鞍点测试集精度稳定在0.8756。
在多达1000次的训练中,发现优化器采取二分类对残差50网络模型的精度提升显著。但由于是40类以上的垃圾分类识别,0.9287的验证集精度并不能维持真理,在测试集中表现只能达到0.6813的精度。在多次尝试后,优化器采用多分类,测试集精度才回到0.8756。
在后期的版本中,将总结迭代余弦退火学习率,进一步将测试集精度提高到0.95以上。
3 Modelarts支撑的无感识别技术生态展望
支付意味着现金流,有资金流动的地方就是金融服务可以覆盖的地方。无感识别支付的应用必须从“生态系统”的角度来实现。在“生态系统”下,支付仅仅是开始而非结束。以支付为前端入口,通过支付给生态带来更多的基础用户和数据,由此打开更多的流量入口,引出更多的风口。一方面,支付有效促进C端用户和G端政府、B端企业(企业服务)之间的连接;另一方面,每一次支付都是高质量数据诞生的过程,通过支付数据判断用户喜好、支付能力、消费地点等,从而完善肖像数据图,挖掘潜在的需求。以下将选择modelarts支撑的支付机构(以下简称“支付机构”)为例,对支付机构在无感支付的“生态”应用方面进行展望。
3.1汽车生态
3.1.1无人值守停车场
推出汽车智能收费机器人套件,采用车辆立体识别技术替代传统的车牌技术,智能计算标准化定价,车主提前通过modelarts支撑的支付机构手机银行或小程序联动识别实现爱车与账户的绑定,驾车离场时自动扣费抬杆放行。
3.1.2ETC的迭代----高速通行
基于汽车电子标识技术的应用,车主提前将汽车信息与银行账户进行关联,充分发挥数据提取与应用的功能优势,解决银行与用户之间信息不对称的问题,实现全天候自动提取车辆属性信息、位置信息以及状态信息。通过收费闸口时,电子车牌准确识别并通过与电子车牌关联的银行账户中自动扣除费用,实现车辆动态通行收费,避免可能出现的拥堵状况。运用modelarts迭代训练视频识别的模型后,用户车主和高速路网中心免去了安装ETC的读写设备及其过程,即提高了高速闸机通行的效率、又降低了多方应用成本。
在互联网金融领域,交通大数据运用的最大价值就在于为银行打造真实的生产、生活场景,通过真实场景产生信息、存储信息、挖掘信息等,以此产生更透明、更高效的金融交易活动。
4 结束语
Modelarts是当前世界算力、推理、精度最快的技术之一,发展现状及探讨未来发展无感支付的前景对人工智能领域是非常有利有益的。相信随着计算机科学技术发展,人们也将享受modelarts训练和部署模型带来的更加便利的生活。
参考文献
[1] Schroff F, Kalenichenko D, Philbin J. Facenet: A unified embedding for face recognition and clustering[J]. arXiv preprint arXiv:1503.03832, 2015.
[2] G-washington , 华为云modelarts2.0来袭
[3] 陈亮 AI前线 深度解读华为云AI开发平台ModelArts技术架构
[4] 张倩雯,庄 毅. 基于机器学习的指令 SDC 脆弱性分析方法 [J]. 小型微型计算机系统,2018,39( 4) : 725-731.
[5] 邱飞岳,胡 烜,王丽萍,等. 分组分解的多目标粒子群进化算法研究[J]. 小型微型计算机系统,2017,38( 8) : 1824-1828.
[6] 张雨石https://blog.csdn.net/stdcoutzyx/article/details/46687471
作者:建行袁覃
往期文章精选
javascript基础修炼(13)——记一道有趣的JS脑洞练习题