| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/2020SPRINGS |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/2020SPRINGS/homework/10287 |
| 这个作业的目标 | 开发一个疫情统计程序,编写代码风格文档,并撰写博客 |
| 作业正文 | https://www.cnblogs.com/hqq1031196651/p/12336531.html |
| 其他参考文献 | 《腾讯c++代码规范》等 |
一、GitHub仓库地址
https://github.com/FreeHqq/InfectStatistic-main
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 45 | 45 |
| Estimate | 估计这个任务需要多少时间 | 20 | 25 |
| Development | 开发 | 900 | 1700 |
| Analysis | 需求分析 (包括学习新技术) | 70 | 260 |
| Design Spec | 生成设计文档 | 30 | 20 |
| Design Review | 设计复审 | 45 | 60 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 45 |
| Design | 具体设计 | 60 | 80 |
| Coding | 具体编码 | 500 | 700 |
| Code Review | 代码复审 | 30 | 45 |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | 70 |
| Reporting | 报告 | 45 | 60 |
| Test Repor | 测试报告 | 30 | 30 |
| Size Measurement | 计算工作量 | 35 | 20 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 35 | 45 |
| 合计 | 1905 | 3205 |
三、解题思路描述
1.看到题目的时候,最先想到的就是利用单链表。
首先创建链表,以各个省份及其对应的疫情信息作为一个节点,每次读取情况的时候就通过头指针去搜索对应的省份,然后对其各项值进行修改,输出也是同理。

2.读取操作则是应用数据流来一行行的读入并先存储下来,再使用字符串截取、字符串比较、字符串合并等方法,读取相应操作信息。
四、设计实现过程
1.程序运行流程图

2.主要设计图(指令内容提取部分)
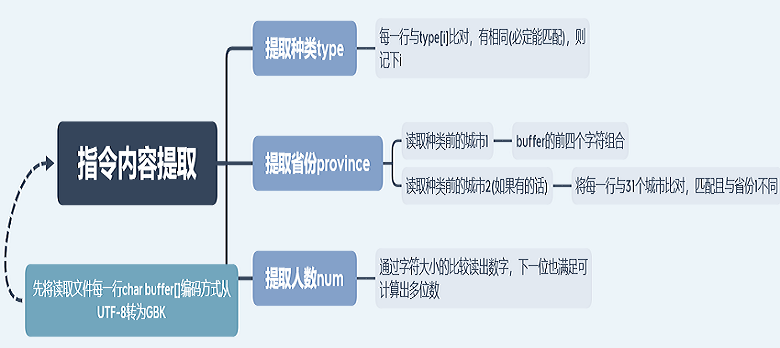
五.代码说明
1.内容提取
首先对读取的每一行,进行转码,存入operation,然后将其运用string类的截取函数string.substr(0,4)获得第一个城市。再将完整语句与实现存储好省份与操作的数组内容一一用string类的find进行查找匹配并记录
string operation = buffer;//读取的每一行
operation = Utf8ToGbk(buffer);//将读取操作语句转换为GBK模式
op_province[0] = operation.substr(0,4);//读取语句中的前四个字符(中文的省份)
string::size_type idx; //string搜索
for (int i = 0; i < 8; i++)//读取指令
{
buf_situation = situation[i];
idx = operation.find(buf_situation);
if (idx != string::npos )
{
op = i;
for (int j = 0; j < 32; j++)//循环匹配城市
{
buf_province = province[j];
idx = operation.find(buf_province);
if (idx != string::npos && province[j] != op_province[0] )
{
op_province[1] = buf_province;
}
}
}
}
2.读取命令行参数(举读取输出病患种类的例子)
通过对读取到的命令行参数数组argv[]与已知的情况"ip""sp""cure""dead"比较来记录参数
void getType(int argc, char *argv[], string type[])
{
string s1;
string s2;
for (int i = 0; i < argc; i++)//循环读取argv数组
{
s1 = argv[i];
if (s1 == "-type")
{
for (int j = i + 1; j < argc; j++)
{
s2 = argv[j];
if (s2 == "ip" || s2 == "sp" || s2 == "cure" || s2 == "dead")
{
type[j - i- 1] = s2;
}
}
}
}
}
3.重要的string转码函数(值得好好记录下来)
c++新版本特有的转换方法
static string Utf8ToGbk(const char *src_str)//utf-8转gbk
{
int len = MultiByteToWideChar(CP_UTF8, 0, src_str, -1, NULL, 0);
wchar_t* wszGBK = new wchar_t[len + 1];
memset(wszGBK, 0, len * 2 + 2);
MultiByteToWideChar(CP_UTF8, 0, src_str, -1, wszGBK, len);
len = WideCharToMultiByte(CP_ACP, 0, wszGBK, -1, NULL, 0, NULL, NULL);
char* szGBK = new char[len + 1];
memset(szGBK, 0, len + 1);
WideCharToMultiByte(CP_ACP, 0, wszGBK, -1, szGBK, len, NULL, NULL);
string strTemp(szGBK);
if (wszGBK)
{
delete[] wszGBK;
}
if (szGBK)
{
delete[] szGBK;
}
return strTemp;
}
static string GBKToUTF8(const char* strGBK)//gbk转utf-8
{
int len = MultiByteToWideChar(CP_ACP, 0, strGBK, -1, NULL, 0);
wchar_t* wstr = new wchar_t[len + 1];
memset(wstr, 0, len + 1);
MultiByteToWideChar(CP_ACP, 0, strGBK, -1, wstr, len);
len = WideCharToMultiByte(CP_UTF8, 0, wstr, -1, NULL, 0, NULL, NULL);
char* str = new char[len + 1];
memset(str, 0, len + 1);
WideCharToMultiByte(CP_UTF8, 0, wstr, -1, str, len, NULL, NULL);
std::string strTemp = str;
if (wstr)
{
delete[] wstr;
}
if (str)
{
delete[] str;
}
return strTemp;
}
六、单元测试截图和描述
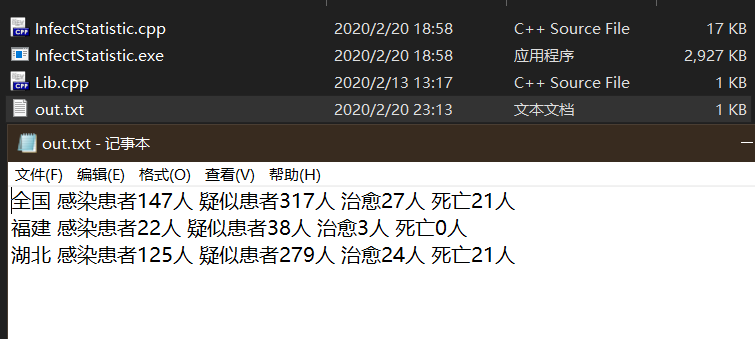
1.测试province为空,type为空,date为空,log和out已知的情况
程序与已知数据

输出结果:
2.测试特定province输出(湖北 福建),type为空,date为空,log和out已知的情况
程序与已知数据

输出结果:

3.测试特定type输出(dead ip sp),province为空,date为空,log和out已知的情况
程序与已知数据

输出结果:

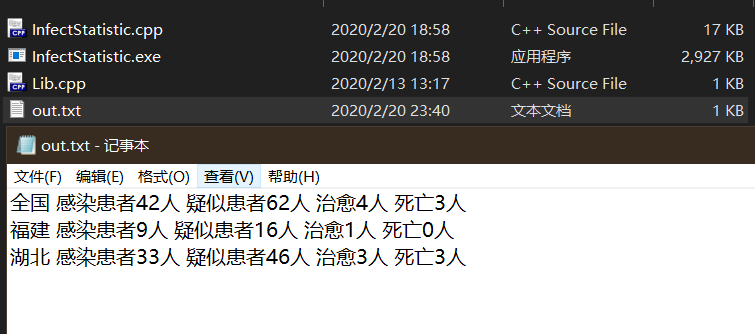
4.测试特定date(2020-01-25小于log目录下日期最大文件2020-01-27,且大于第一第二个文件日期2020-01-22 2020-01-23),type为空,province为空,log和out已知的情况
程序与已知数据

输出结果:
七、单元测试覆盖率优化和性能测试,性能优化截图和描述
DevC++开发,没有办法统计单元测试覆盖率和性能
八、git仓库链接、代码规范链接
git仓库链接https://github.com/FreeHqq/InfectStatistic-main
代码规范链接https://github.com/FreeHqq/InfectStatistic-main/blob/master/221701336/codestyle.md
九、心路历程和收获
- 这次作业一个最主要的感受就是心累

一开始分析需求,很快就确定了用链表来存储数据,然后按照每天完成一部分的情况来安排这次作业,觉得后面应该还挺顺利的。
第一个遇到的难题是命令行操作,因为之前完全没有接触这个类型的c++程序运行,好在网络上很多的教程,让我很快就学会了char *argv[]来读取命令行操作。
然后就是对文件输入输出的不熟悉,普通的数据流输出输出还好,但读取特定目录下文件的文件名确实花费了不少上网学习的经历,最终发现了struct _finddata_t FileInfo,解决了这一问题。后续又纠结在对文件内容的处理这一问题上,最终确定了按行读取,然后对每行内容进行各值的读取。
接下来就是卡了我好几天的编码格式的问题,将utf-8的文件读取的每行存进char数组内,但由于机器默认是Gbk,对文本的处理来回搜索、思考,修改编译方式或者命令行执行方式都还是有一定的问题,最后终于在CSDN的犄角旮旯发现了
static string Utf8ToGbk(const char *src_str)//utf-8转gbk和static string GBKToUTF8(const char* strGBK)//gbk转utf-8我一辈子都会记住的(bushi)这两个函数!
在开发过程中也发现了自己许许多多的问题:编程语言的不熟悉、代码的丑陋(以前写代码极其不规范,在编写了代码规范后,花了极大的经历在后续修改代码风格上,通过之前的commit可能可以发现),最后终于完成了。心累,但还是有满足感的,因为以前很多的作业都是参考网上现有的原题,这次的"联动",使我第一次从头到尾独立思考、整理、学习和编写一份最像是目前我的水平能写出的代码,但还是由于时间紧张和个人能力的不足以及放假在家条件有限,程序在效率上还未来得及进行进一步的测试和优化。之后有时间应该会回看的。
十、技术路线图相关的5个仓库
- 1.基于Node.js+MySQL开发的开源微信小程序商城(微信小程序)
简介:
界面高仿网易严选商城(主要是2016年wap版)
测试数据采集自网易严选商城
功能和数据库参考ecshop
服务端api基于Node.js+ThinkJS+MySQL
计划添加基于Vue.js的后台管理系统、PC版、Wap版
- 2.音乐播放器第三方
简介(特点):
JSS主题支持、OSX友好、跨平台、键盘支持、桌面通知、现代UI设计、
音乐链接(QQ音乐,虾米音乐,酷狗音乐,酷我音乐,咪咕音乐,百度音乐合而为一)
可将音乐分享到Facebook,Twitter,Google +,微信、
支持微信扫描登录
- 3.Elm-react-native(模拟饿了么的外卖软件)
简介:这是一个由React Native实现的高仿真eleme应用程序(eleme网站)。该应用程序可以在iOS和Android上运行,该应用程序不使用任何API,没有数据,它是一个UI显示应用程序,该应用程序的UI与eleme应用程序有超过95%的共同点。这是一个学习React Native的过程
- 4.仿知乎日报APP
简介:知乎 App客户端,使用React Native实现。该项目可以在Android和iOS上运行,共有80%以上的代码。这是一个演示项目,展示了如何使用React Native开发完整的应用程序
- 5.使用 Node.js 和 MongoDB 开发的社区系统
简介:Nodeclub 是使用 Node.js 和 MongoDB 开发的社区系统,界面优雅,功能丰富,小巧迅速,已在Node.js 中文技术社区 CNode(http://cnodejs.org) 得到应用,完全可以用它搭建自己的社区。