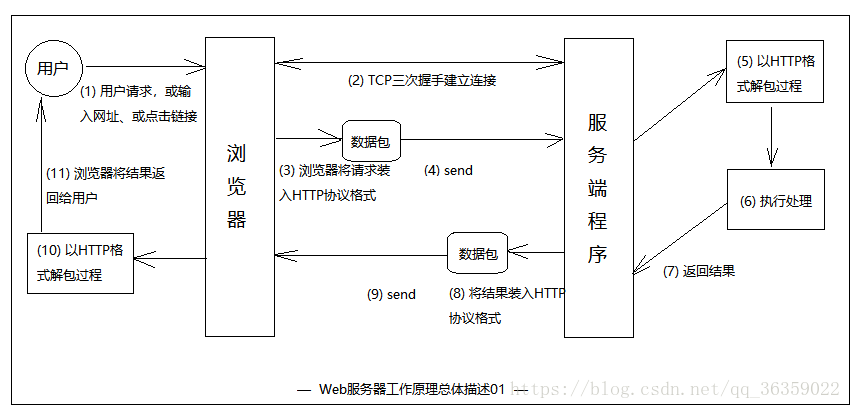
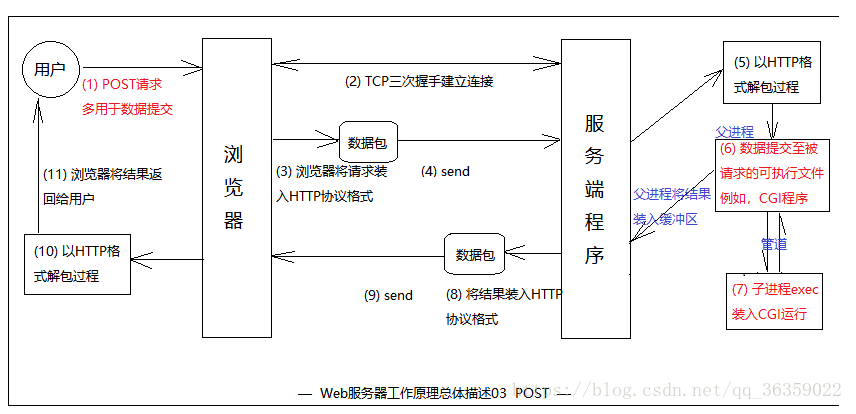
实现一个web服务器
服务器监听一个端口,并读取浏览器的请求信息,从该信息提取出访问的资源(这里为文件名)。并在工作目录下查找是否有该资源,有则输出资源内容,否则返回404
代码实现
代码为自己手动输入,并加入注释帮助理解
package webserver;
import java.io.*;
import java.net.*;
public class WebServer {
/**
* web服务器:实现200和404操作
* 原理:
* 服务器监听一个端口,并读取浏览器的请求信息,从该信息提取出访问的资源(这里为文件名)。并在工作目录下查找是否有该资源,有则输出资源内容,否则返回404
* 测试方法:
* 1、用String path=System.getProperty("user.dir");获取当前的工作目录,并在该目录下放要测试的文件
* 2、访问127.0.0.1:8080/HelloWorld.html
*/
public static void main(String[] args) {
// TODO Auto-generated method stub
ServerSocket server = null;
Socket s=null;
try
{
//参数:(int port, int backlog, InetAddress bindAddr)
server=new ServerSocket(99,3,InetAddress.getByName("127.0.0.1"));
}catch(Exception e)
{
e.printStackTrace();
}
while(true)
{
try{
/*
* Listens for a connection to be made to this socket and accepts it.
*/
s=server.accept();
OutputStream output=s.getOutputStream();
InputStream input=s.getInputStream();
//通过自实现reques类获取请求参数
Request request=new Request(input);
String filename=request.getUri();
//通过自实现response类处理,传入请求资源名,并响应请求信息
Response response=new Response(output,filename);
response.response();
}catch(Exception e)
{
e.printStackTrace();
}
}
}
}
package webserver;
import java.io.*;
/*
* 获取请求的信息,并返回资源
* 返回请求资源文件名
*/
public class Request {
InputStream input;
public Request(InputStream input){
this.input = input;
}
/*
* 自写的获取资源URI的方法
*/
public String getUri(){
String content = null;
//String str = null;
//对需要频繁处理的字符串, 使用StringBuffer类操作
StringBuffer request = new StringBuffer();
//作用?将输入流中的存入字节数组,在存入SB
byte[] buffer = new byte[2048];
int i = 0;
try{
i = input.read(buffer);
}catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
i = -1;
}
for(int k = 0; k < i; ++k){
request.append((char)buffer[k]);
}
content = request.toString();
/*
*以下方法错误!用该返回会使浏览器不断处于请求连接状态
* BufferedReader br=new BufferedReader(new InputStreamReader(input));
while((str=br.readLine())!=null)
{
content=content+str+"
";
}
*/
if(content != null){
return getFileName(content);
}else{
return null;
}
}
/*
* 关键:字符串(即文件名(即资源路径))格式
*/
public String getFileName(String content){
int a, b;
a = content.indexOf(' '); //文件名的格式???
if(a != -1){
/*
* Returns the index within this string of the first occurrence of the specified character,
* starting the search at the specified index.
*/
b = content.indexOf('?', a+1);
if(b == -1){
b = content.indexOf(' ', a+1);
}
/*
* a+2:beginIndex; b:endIndex
*/
return content.substring(a+2, b);
}
return null;
}
}
package webserver;
import java.io.*;
/*
* 响应并处理请求信息
*/
public class Response {
public OutputStream output;
public String fileName;
//static final定义常量,不可更改
private static final int BUFFER_SIZE = 1024;
public Response(OutputStream output, String fileName){
this.output = output;
this.fileName = fileName;
}
public void response() throws IOException{
//"user.dir" 是固定的工作目录???
String path = System.getProperty("user.dir");
byte[] buffer = new byte[BUFFER_SIZE];
int ch;
FileInputStream fis = null;
if(path != null &&fileName != null){
/*
* 内置方法:Creates a new File instance from a parent pathname string and a child pathname string.
* request获得用户请求文件名,结合文件目录,生成File类
*/
File file = new File(path, fileName);
System.out.println(path + " " + fileName);
String str = "";
/*
* 模拟web服务器响应,生成响应头等信息,并返回html文件
*/
/*
* 如果文件存在,则返回请求结果,打印请求信息
*/
if(file.exists()){
System.out.println("find");
//FileInputStream读取文件内容,并使用OutputStream输出
fis = new FileInputStream(file);
str = "HTTP/1.1 200 OK
" +
"Content-Type: text/html
" +
"
";
output.write(str.getBytes());
//循环读取,存入缓冲字节数组,并输出
ch = fis.read(buffer);
while(ch != -1){
output.write(buffer, 0 , ch);
ch = fis.read(buffer, 0, BUFFER_SIZE);
}
}else{
/*
* 如果文件不存在——没有找到请求资源,响应头状态返回404信息
*/
System.out.println("not find");
str = "HTTP/1.1 404 File Not Found
" +
"Content-Type: text/html
" +
"Content-Length: 100
" +
"/r/n" +
"<h1>404 File Not Found!</h1>";
output.write(str.getBytes());
}
}
output.close();
}
}
测试方法:
- 在目录下存入指定资源html文件以便访问,HTML文件实现如下
<!DOCTYPE html>
<html>
<head>
<title>hello world</title>
</head>
<body>
<h1>hello world!</h1>
</body>
</html>
-
通过打印达到user.dir为 “D:工作环境SimpleServer”
不用新建一个user.dir文件夹,直接把html文件放在同一个目录下
-
运行应用,在浏览器中输入
运行结果:
- 输入正确资源名

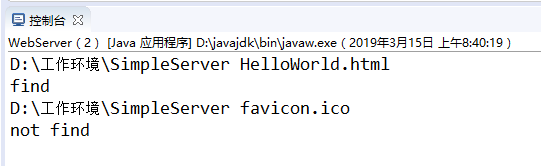
2.输入不正确资源名
- 在谷歌浏览器下,输入不存在资源名会一直加载而没有显示404(为什么??)

- 在IE浏览器下成功显示404

出现的问题:
- 多次操作会在套接字连接时出现空指针异常,了解到是端口占用问题

-
解决方法:
- 关闭端口占用:
在命令行中输入netstat -ano 找到被占用端口号
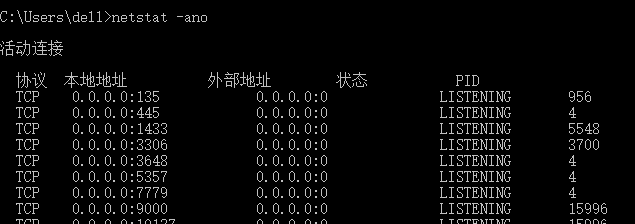

打开任务管理器,找到端口号对应进程ID对应的进程,点击结束进程即可解决占用
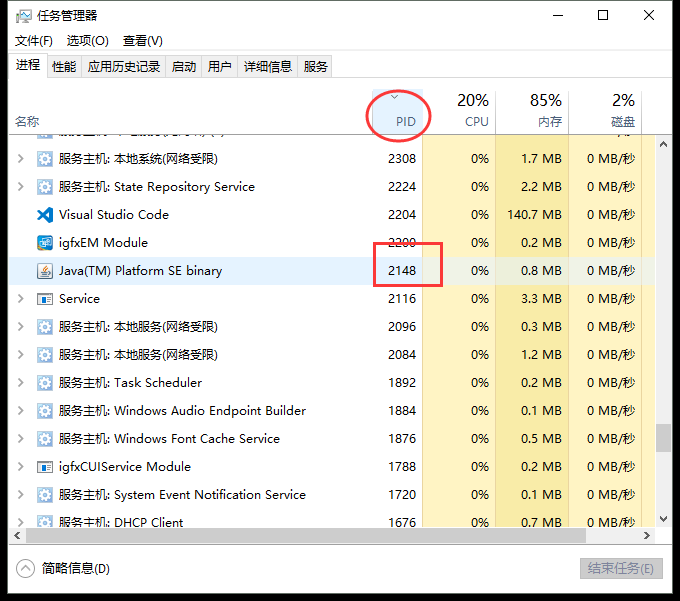
- 更换new ServerSocket(99,3,InetAddress.getByName("127.0.0.1"));里的端口号
- 关闭端口占用:
- 始终404错误!:打印可知搜索路径为,D:工作环境SimpleServer
- 所以解决方案为,将html资源文件放在“ D:工作环境SimpleServer”该目录下(我之前同java文件放在src目录下)
- 所以解决方案为,将html资源文件放在“ D:工作环境SimpleServer”该目录下(我之前同java文件放在src目录下)
扩展——网络编程:
- Socket编程步骤
服务器端创建ServerSocket对象,调用accept方法返回Socket对象
客户端创建Socket对象,通过端口连接到服务器
客户端、服务器端都使用Socket中的getInputStream方法和getOutputStream方法获得输入流和输出流,进一步进行数据读写操作
(InetAddress用来描述主机地址;
Socket用来创建两台主机之间的连接;
ServerSocket用来侦听来自客户端的请求;
Socket通常称作“套接字”,通常通过“套接字”向网络发出请求或者应答网络请求。)
由该程序理解Web服务器的工作原理
- 一组我认为很好理解的源于网络的工作原理图解
参考web服务器工作原理