每日一问8:C++中的内存对齐机制是什么
什么是内存对齐
要理解内存对齐我们先来看一个现象:
#include<iostream>
#include<Windows.h>
#pragma pack (8)
using namespace std;
typedef struct {
char b;
double c;
int a;
} A;
typedef struct {
int a;
char b;
double c;
} B ;
int main() {
A a;
B b;
cout << "sizeof(a)=" << sizeof(a) << ends << "sizeof(b)=" << sizeof(b) << endl;
return 0;
}
运行结果如下:
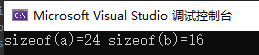
可以看到仅仅是调换了结构体中数据的顺序,结构的大小就变化了,这里就是内存对齐导致的一个结果。
而较为正式的定义是:现代计算机中内存空间都是按照 byte 划分的,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但是实际的计算机系统对基本类型数据在内存中存放的位置有限制,它们会要求这些数据的首地址的值是某个数k(通常它为4或8)的倍数,这就是所谓的内存对齐。
为什么要内存对齐
要理解为什么需要内存对齐,我们观察一下当没有内存对齐时的情况就可以知道。
首先我们要知道内存存取粒度这个概念。计算机中,内存可以理解为一个字节数组,但大部分CPU都不是按字节来读取内存,一般会以双字节,四字节,8字节,16字节甚至32字节为单位来存取内存,这些单位就称为内存存取粒度。
接下来我们来比较有无内存对齐的不同情况,任务是,先从地址0读取4个字节到寄存器,然后从地址1读取4个字节到寄存器。
1.单字节存取
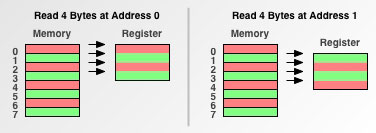
单字节存取的情况下,对齐和不对齐都为四次操作。
2.双字节存取

双字节存取的情况下,从地址0读取四个字节只要两次,而从地址1读取需要三次。
3.四字节存取
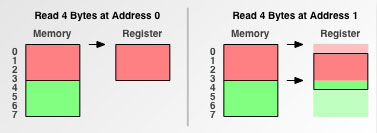
四字节存取的情况下,从地址0读取四个字节只要一次,而从地址1读取需要两次。
由上我们可以看到,内存对齐后,会提升程序的效率。
1)可以访问未对齐的内存,但是会影响性能。例如x86架构的CPU
2)抛出异常or静默访问错误的地址(内存对齐是为了方便移植)
总结:防止数据随意存放,cpu访问内存对齐的速度会大大提升。
内存对齐是怎么运行的
每个特定平台上的编译器都有自己的默认“对齐系数”(也叫对齐模数)。gcc中默认#pragma pack(4),可以通过预编译命令#pragma pack(n),n = 1,2,4,8,16来改变这一系数。也可以使用#pragma pack ()来取消自定义字节对齐方式。
对齐规则:
1.基本类型的对齐值就是其sizeof值;
2.struct,class,union类型的对齐量等于它的非静态成员变量中最大的对齐量。标准规定所有的对齐量必须是2的幂。
3.编译器可以通过#pragma pack指定的对齐参数,类型的实际对齐值是该类型的对齐值与指定的对齐参数的最小值。
参考博客:
1. 为什么要内存对齐 Data alignment: Straighten up and fly right_子虚-CSDN博客